Читайте также:
|
На рисунке 14 показана блок-схема процесса исследования и диагностики.

| Подписи к рисунку: Re-allocate to appropriate team - Переназначение соответствующей группе Yes - Да Functional escalation required? - Требуется эскалация функциональных возможностей? No - Нет Malicious Intent suspected? - Ожидается злоумышленное намерение? Allocate support staff - Назначение персонала поддержки Assess incident details - Оценка информации об инциденте Gather facts - Сбор фактов Matches known error? - Соответствует известной ошибке? Matches existing problem? - Соответствует существующей проблеме? Investigation and diagnostic data search - Поиск данных исследования и диагностики Preserve evidence and notify security team - Сохранение доказательства и уведомление группы безопасности Management escalation required? - Требуется эскалация управления? Perform management escalation - Выполнение эскалации управления Link incident to known error - Связывание инцидента с известной ошибкой Is there a workaround? - Существует обходной путь? Problem management accept match? - Принимает ли управление проблемами соответствие? Workaround or solution identified? - Идентифицированы ли обходной путь или решение? Major incident? - Серьезный инцидент? Major incident process - Процесс серьезного инцидента Link incident to problem record - Связывание инцидента с регистрационной записью проблемы Problem management - Управление проблемами Can it be tested? - Может ли быть выполнена проверка? Test workaround or solution - Проверка обходного пути или решения Tested successfully? - Проверка прошла успешно? Resolution and recovery - Разрешение и восстановление |
Рисунок 14. Блок-схема процесса исследования и диагностики
Если группа начальной поддержки не смогла разрешить инцидент, то он переходит к процессу диагностики и исследования. Этот процесс инициализируется, когда инцидент назначается группе решения. Группы решения могут состоять из широкого диапазона ИТ групп, включая персонал по поддержке и разработке, другие SMF, другие единицы внутри организации, привлеченных внешних провайдеров, партнеров и других третьих лиц.
Число и размер групп решения зависит от организации. Как правило, организации поддержки структурируются с использованием одного из следующих подходов:
· Ярусная структура, включающая группы поддержки первой, второй, третьей и энной линий. Часто энная линия будет являться либо внешним поставщиком, либо внутренней группой разработки, в зависимости от поддерживаемых приложений и уровня внутренних экспертных знаний.
· Структура, основанная на платформе и приложении, состоящая из определенных для платформы групп поддержки, часто с использованием дополнительных групп, сфокусированных на приложениях передачи сообщений и базы данных.
· Комбинация вышеупомянутых структур. Наиболее общим вариантом является использование группы поддержки первой линии (в службе поддержки), которая поддерживается платформенной структурой групп поддержки, состоящих из персонала с различным уровнем навыка, который поддерживается внешними поставщиками, обеспечивающими поддержку энной линии для своих собственных продуктов или сложных/серьезных инцидентов. Некоторые службы поддержки управляют структурой отдела по операциям с клиентами/отдела обработки документации, в действительности создавая два яруса поддержки внутри непосредственно самой службы поддержки.
Структура должна удовлетворять потребности индивидуальной организации, но следует помнить о том, что увеличенная сложность приносит увеличенные затраты. Чем выше число индивидуальных групп поддержки, тем труднее совместно использовать информацию и обеспечивать дублирование навыков, и наиболее вероятно, что потребуется арбитраж для принятия решения по ответственности в случае возникновения сложных инцидентов. В тех случаях, когда ответственность за разрешение инцидента вызывает споры, служба поддержки должна обсудить проблему с вовлеченными сторонами, с тем, чтобы понять, может ли быть достигнуто соглашение. Если простое соглашение не может быть достигнуто, то управление проблемами будет ответственно за арбитраж.
Независимо от числа и сложности групп решения, структура должна быть четко задокументирована, для того чтобы весь персонал понял, какие категории запросов должны назначаться каждой группе и каковы пути эскалации, если она требуется. Отсутствие четко определенной структуры поддержки приводит к увеличению расходов, неудовлетворенности и времени решения, снижая удовлетворение клиента.
Инструмент поддержки должен иметь очередь для каждой группы решения. Группа решения ответственна за контролирование своей очереди и отслеживание прогресса инцидентов, назначенных ей. Персонал поддержки может регистрироваться в инструменте поддержки и просматривать регулярно обновляемый список инцидентов в пределах своей очереди.
Примечание, касающееся технологии. Доступно широкое разнообразие технологий для оказания помощи группам решения в их управлении очередями. Они включают отображение состояния очереди в пределах офисной зоны группы решения с использованием больших мониторов или специально разработанных электронных дисплейных панелей. Большие электронные дисплейные панели могут конфигурироваться для отображения ключевых выводов из множества различных систем, включая системы службы поддержки и системы управления событиями. На приведенном ниже рисунке показан пример очереди группы решения.

Рисунок 15. Пример очереди группы решения
Персонал поддержки во многих случаях мобилен и нуждается в просмотре своей очереди из различных местоположений. Это может быть достигнуто путем предоставления возможности персоналу поддержки соединяться с инструментом поддержки через интернет-браузер с любого персонального компьютера внутри организации. Беспроводные технологии позволяют персоналу поддержки иметь карманные компьютеры (PDA), которые могут синхронизироваться с системой поддержки для отображения очереди с самой последней информацией, а также обновления существующих инцидентов. Должны быть приняты меры, направленные на обеспечение безопасности этих систем.
Если персонал не может постоянно контролировать очередь, то снова может использоваться технология для предоставления им уведомлений о том, когда очереди назначаются новые инциденты. Уведомления могут иметь форму всплывающих полей, направляемых по электронной почте писем или мобильных текстовых сообщений.
Когда инцидент помещается в очередь группы решения, он должен быть назначен члену группы для прогресса. Член группы отвечает за поддержку регистрационной записи инцидента, обновляя ее последней информацией о состоянии, предпринятых действиях и прогрессе.
Регистрационные записи инцидента должны обновляться со следующей информацией для каждого предпринятого действия:
· Название/идентификатор группы поддержки и лица, регистрирующего действия.
· Тип действия (переназначение, диагностика, восстановление, разрешение, закрытие и т.д.).
· Дата/время действия.
· Описание и результат действия.
Если на каком-либо этапе предполагается, что инцидент должен быть назначен другой группе решения, то текущая группа решения должна переназначить инцидент обратно службе поддержки, которая затем выполнит новое назначение. Это снижает вероятность непрерывного перекидывания запросов между группами решения и позволяет службе поддержки более эффективно координировать процесс управления инцидентами, определяя ситуации, когда требуется арбитраж.
Группы решения не могут закрывать инциденты самостоятельно. Если предполагается, что инцидент разрешен, то его состояние должно быть установлено как разрешенное, и он должен быть назначен группе поддержки. Перед закрытием аналитики поддержки должны подтвердить, что инициатор удовлетворен решением.
После того как инцидент был назначен члену персонала группы решения, этот член группы решения должен оценить информацию об инциденте до этого момента и собрать любые необходимые факты.
Примечание, касающееся технологии. База данных управления конфигурациями (CMDB) может являться важным инструментом для обнаружения фактов во время исследования инцидента. База данных может использоваться для просмотра информации по затронутым конфигурационным единицам (CI), например, версий загруженного в них программного обеспечения и хронологии этих элементов конфигурации, проверки деталей любых гарантий или контрактов на поддержку, которые охватывают конфигурационные единицы, подтверждая их местоположения.
Ниже показан пример регистрационной записи основной конфигурационной единицы.

Рисунок 16. Пример регистрационной записи основной конфигурационной единицы
На приведенном ниже рисунке показан пример регистрационной записи хронологии основной конфигурационной единицы.

Рисунок 17. Пример регистрационной записи хронологии конфигурационной единицы
CMDB может также использоваться для идентификации конфигурационных единиц, связанных с затронутыми конфигурационными единицами, для того, чтобы могли быть приняты меры, направленные на минимизирование воздействия инцидента посредством изменения маршрута или переконфигурирования соответствующих конфигурационных единиц.
Другое использование CMDB заключается в идентификации других конфигурационных единиц, которые идентичны ошибочным конфигурационным единицам, с тем, чтобы они могли использоваться для сравнения, выделяя отличия, вызывающие инцидент.
Как только персонал поддержки закончит сбор фактов, он должен проверить, указывает ли собранная информация на то, что имеется появление известной ошибки. Информация по известной ошибке может быть получена из различных источников, например, из корпоративных баз данных известных ошибок, поддерживаемых управлением проблемами, из баз данных известных ошибок, предоставляемых поставщиком, а также с интернет-сайтов, включая сайты поставщиков и соответствующих сетевых телеконференций.
Примечание, касающееся технологии. Изобилие информации, доступной в предоставляемых поставщиком базах знаний делает их жизненно важным инструментом для групп поддержки. Эти базы знаний доступны либо на вэбсайтах поставщиков, либо в виде CD/DVD пакетов, которые часто можно приобрести вместе с лицензией на использование системы или индивидуальной лицензией.
Базы знаний содержат разнообразную информацию, включая известные ошибки, исправления, обновленные драйверы, официальные документы, часто задаваемые вопросы (FAQ) и технические статьи.
Большое преимущество предоставляемого поставщиком знания состоит в том, что организации могут извлекать выгоду из диагностической информации и информации по решению, когда инциденты возникают в других местах, часто приводя к намного более быстрому устранению проблемы, если организация сталкивается с такими же или подобными инцидентами.
Поставщики также часто предоставляют большой объем справочной информации в своих продуктах в форме онлайновой справочной документации и с использованием средств поиска. В некоторых случаях из ресурсных наборов, специально созданных для продукта, можно получить дополнительную документацию и полезные утилиты.
Некоторые инструментальные средства управления системами также содержат базы знаний на тот случай, если будет сгенерировано предупреждение, чтобы можно было бы обеспечить дополнительную диагностику и/или рекомендацию по решению. Как это происходит для всех предоставляемых поставщиками баз знаний, на месте должны присутствовать механизмы, гарантирующие регулярное получение обновлений и их применение, с тем, чтобы предоставляемая информация относительно известных обходов исправлений оставалась на современном уровне.
Организации могут также создавать свои собственные корпоративные базы знаний. Эти корпоративные базы знаний могут содержать в себе любую информацию, являющуюся уместной для того, чтобы персонал мог поддерживать ИТ инфраструктуру организации. Принимая во внимание, что предоставляемые поставщиком базы знаний могут содержать большое количество материала, который не является значимой для конкретной организации, может также быть создана корпоративная база знаний, содержащая информацию, относящуюся к ее деятельности. Корпоративные базы знаний могут создаваться при использовании баз данных или же сторонних инструментальных средств, разработанных для этой цели.
Если инцидент действительно соответствует существующей известной ошибке, то регистрационная запись инцидента должна быть обновлена, с тем, чтобы связать его с регистрационной записью известной ошибки. В зависимости от используемых инструментальных средств, это действие может включить в себя соединение двух регистрационных записей в интегрированный набор инструментальных средств. Однако при использовании отдельных инструментальных средств это может означать только включение идентификатора известной ошибки (и всего, что позволяет свободное пространство для дополнительной информации) в регистрационную запись инцидента и, если возможно, обновление номера инцидента в регистрационной записи известной ошибки. Затем необходимо подвергнуть инцидент процессу разрешения и восстановления, если могут быть применены обходной путь или решение, идентифицируемые в регистрационной записи известной ошибки.
Инциденты, которые нельзя сопоставить с известными ошибками, должны пройти проверку на существующие проблемы. Существующие проблемы - это проблемы, которые в настоящее время известны управлению проблемами, но для которых необходимо идентифицировать решение по первопричине. Существующая проблема может иметь идентифицированный обходной путь, а может и не иметь его. Если инцидент соответствует существующей проблеме и имеется идентифицированный обходной путь, то инцидент должен быть объединен с регистрационной записью проблемы (посредством установления связи или перекрестной ссылки) и подвергнут процессу разрешения и восстановления для приложения обходного пути.
Если предполагается, что инцидент соответствует существующей проблеме, но никакого обходного пути идентифицировано не было, то регистрационную запись инцидента нужно передать управлению проблемами. Управление проблемами отвечает за подтверждение того, действительно ли соответствует инцидент проблеме, и оно должно либо принять инцидент (назначив ему уместную регистрационную запись проблемы), либо отклонить его и направить обратно управлению инцидентами, если обнаруживается, что соответствие является неправильным. Управление проблемами продолжает работать над существующими проблемами и отвечает за информирование управления инцидентами об обнаружении обходных путей или решений для проблем, с которыми связаны регистрационные записи инцидента. После информирования управления инцидентами оно будет отвечать за разрешение, восстановление и закрытие любых неразрешенных инцидентов.
Процесс сопоставления инцидентов и известных ошибок и проблем продолжается в течение исследования и диагностики инцидента. По мере получения дополнительных диагностических доказательств, например новых идентификаторов события или кодов ошибок, эта новая информация должна быть направлена в соответствующий процесс. В процессе исследования могут также анализироваться предыдущие регистрационные записи инцидента для определения того, как подобные инциденты разрешались в прошлом.
Управление инцидентами обычно фокусируется на как можно более быстром восстановлении нормального сервиса. Исключениями являются случаи, когда подозревается злоумышленное намерение. В таких случаях персонал поддержки должен работать в тесном контакте с персоналом безопасности в соответствии с политикой и процедурами группы безопасности для обработки инцидентов безопасности. Часто очень важно гарантировать сохранение всех доступных доказательств для использования в ходе юридических или дисциплинарных разбирательств. Группа безопасности должна оказывать помощь в сборе и хранении доказательств, выдавая инструкции о том, какие доказательства будут приниматься и какая контекстная информацию (идентификаторы компьютеров, отместки даты и времени) должна быть включена. В зависимости от воздействия инцидента должно быть принято решение, следует ли разрешать инцидент в реальном времени, при этом, возможно, перезаписывая важные доказательства, или же перейти к договоренностям непрерывности резервирования, пока не будет уверенности в том, что все доступные доказательства были собраны.
Фаза исследования и диагностики включает в себя: первое - получение персоналом поддержки четкой картины того, каким образом затрагивается нормальный сервис, второе - идентификацию того, что вызывает это воздействие, и, наконец, третье - определение, как такую ситуацию можно обойти или разрешить.
При первоначальном информировании об инциденте может иметь место очень ограниченная информация по характеру, степени и общем воздействии проблемы. Регистрационная запись инцидента должна включать в себя максимально возможное количество данных, полученных от инициатора, но зачастую эта информация будет ограничиваться точкой зрения и степенью знаний человека.
Для того чтобы персонал поддержки смог разрешить инцидент, он должен сначала узнать как можно больше об инциденте. Необходимо сосредоточиться на обнаружении точных сообщений об ошибках или идентификаторов события, подтверждении любых предпринятых действий, приведших к инциденту, а также подтверждении зоны влияния инцидента, например, затрагивает ли он только отдельного пользователя, который сообщил об инциденте, или же всех пользователей сервиса. Персонал поддержки должен выполнить сбор доказательств, просматривая файлы регистрации и журналы регистрации событий и, если это выполнимо, попробовать воспроизвести проблему, с тем чтобы он смог испытать ее на собственном опыте.
Самым простым вариантом было бы реальное посещение пользователей для того, чтобы проанализировать то, как меняется проблема в зависимости от географического местоположения. Поскольку посещение даже местных пользователей занимает время, цель должна состоять в том, чтобы исправить удаленно как можно больше инцидентов. Как было сказано выше, цель управления инцидентами заключается в как можно более быстром восстановлении нормального сервиса, поэтому если это может быть сделано удаленно без необходимости затрачивания времени на поездку, то это соответствует цели. Однако, если на какой-нибудь стадии в течение жизненного цикла инцидента становится видно, что посещение, несмотря на время поездки, приведет к более быстрому разрешению, то этот вариант также необходимо принять во внимание. В рассмотрение следует включить оправдание затрат, связанных с посещением, относительно влияния увеличения времени разрешения инцидента. В то время как политика должна минимизировать превышение времени, проведенного в пути, организации должны гарантировать, что они не исключают оправданные посещения и таким образом не продлевают инциденты.
Необходимо рассмотреть структуру организации поддержки и то, должен ли персонал поддержки располагаться в центре или же быть распределен по различным местам. Как правило, распределение увеличивает сложность и, следовательно, затраты организации поддержки. Однако часто структура должна разрабатываться для того, чтобы удовлетворять согласованным уровням сервиса. Например, если согласованный уровень сервиса требует локального ответа в течение одного часа, а данное местоположение удалено от других точек поддержки, то требуется определенная форма местного присутствия. В зависимости от вовлеченных затрат, использования безопасности, простоты найма и уровня требуемой поддержки, организации могут рассматривать использование аутсорсинга для локальной поддержки в протяженных местоположениях.
Примечание, касающееся технологии. Для оказания помощи в минимизировании потребности локальных посещений доступными являются удаленные инструментальные средства поддержки. Эти инструментальные средства включают в себя утилиты, позволяющие удаленно просматривать файлы регистрации и запускать административные утилиты на удаленных компьютерах. Всегда должны приниматься меры, направленные на гарантию безопасности этих систем от неправомочного использования.
Может иметь место повышение функциональных возможностей при использовании удаленных инструментальных средств, позволяющих персоналу поддержки просматривать то, что пользователь испытывает на удаленной системе и, в случае необходимости, переключать на себя систему для исследования инцидента и применять любые действия, связанные с его разрешением. Эти инструментальные средства являются также необходимыми, когда персонал поддержки ответственен за системы, расположенные в удаленных или автоматических машинных залах.
После того, как персонал поддержки сможет понять инцидент, он должен идентифицировать, почему этот инцидент происходит и как можно разрешить проблему или использовать для нее обходной путь. Управление инцидентами интересуется непосредственной причиной инцидента, а не возможными основными первопричинами, которыми интересуется управление проблемами. Например, управление инцидентами может идентифицировать причину инцидента как "заблокированный" или "зависший" файловый сервер и для решения данной проблемы требуется перезагрузка сервера. Вместе с этим управление проблемами должно определить, была ли эта проблема изолированным инцидентом или же в его основе существует проблема, которая вызывает блокировку этого, и возможно других, файловых серверов.
Несмотря на всесторонние процессы управления изменениями и релизами, вероятно, что некоторые инциденты будут все еще возникать из-за внесенных изменений. Если происходит инцидент и никакую непосредственную причину идентифицировать невозможно, то персонал поддержки должен проконтролировать, какие изменения произошли недавно, для того чтобы проверить, были ли они уместными. Формальное управление изменениями не только стремится воспрепятствовать возникновению дальнейших инцидентов из-за изменений, но также гарантирует, что, когда такие инциденты действительно происходят, будет доступна полная информация о сделанных изменениях.
При диагностировании сложных инцидентов персонал поддержки должен изучить все доступные доказательства и затем разбить инцидент на более простые модули.
Для гарантии организованного и логического подхода полезно представить проблему в графическом виде, нарисовав ее на бумаге, белой доске или же с помощью программного инструмента. Это может быть блок-схема, поток данных или сетевая диаграмма. Подходящее графическое представление может помочь идентифицировать вовлеченные компоненты и интерфейсы, а, следовательно, и потенциальные проблемные точки. В этот момент может потребоваться мозговой штурм для идентификации всех возможных проблемных точек. Если существует несколько потенциальных проблемных точек, то может быть применено взвешивание, которое оценивает воспринимаемую вероятность каждой проблемной точки, позволяя определить непосредственную причину инцидента и избавиться от проверки каждой проблемной точки. Взвешивание может позволить расположить по приоритетам исследовательские действия.
Для того чтобы персонал поддержки мог воспроизводить инциденты и тестировать обходные пути вдали от реальной среды, он должен иметь доступ к испытательным средам, отражающим реальную среду (или ее часть) настолько близко, насколько это возможно. Несмотря на то, что редко можно точно воспроизвести размер и рабочую нагрузку реальной среды, значительные выгоды можно получить от масштабированной испытательной среды. Обоснование стоимости испытательных сред может представлять собой трудную задачу. Однако эти инвестиции должны быть сделаны для того, чтобы предотвратить постоянный цикл, в котором производятся изменения (используя процессы управления изменениями и релизами) для разрешения одного инцидента, приводящие к другому инциденту, поскольку до изменения в реальной среде было выполнено неадекватное тестирование.
На приведенном ниже рисунке показан пример жизненного цикла изменения инцидента.

| Подписи к рисунку: Start - Начало Incident Management - Управление инцидентами Incident - Инцидент Problem Management - Управление проблемами Problem - Проблема Change Management and Release Management - Управление изменениями и управление релизами Change - Изменение Release - Релиз Break out of the vicious circle by conducting thorough testing of changes, resulting in incident closure without causing new incidents - Выход из порочного круга посредством выполнения всестороннего тестирования изменений, приводя к закрытию инцидента, не вызывая при этом новых инцидентов Inadequate testing of changes results in vicious circle, generating further new incidents - Неадекватное тестирование изменений приводит к порочному кругу, генерируя дальнейшие новые инциденты End - Конец |
Рисунок 18. Пример жизненного цикла изменения инцидента
Для содействия диагностике инцидентов группы поддержки могут использовать такие методики как наставничество и собрания сортировки.
Процесс наставничества может проводиться в отношении младшего персонала поддержки более опытными людьми, возможно из более высоких ярусов структуры поддержки. Более опытный персонал может давать советы и указания о том, как следует исследовать определенный инцидент и как его разрешать после диагностирования.
Эта методика приносит пользу, увеличивая знания и опыт младшего персонала, а также снижая число инцидентов, которые должны быть назначены более опытный персоналу, таким образом предоставляя им больше времени на обработку более сложных и стратегических проблем. Необходимо приветствовать такой процесс совместного использования знаний. Однако все еще необходимо осуществлять эскалацию инцидентов, если персонал чувствует, что это необходимо, для того чтобы удовлетворить сервисные цели.
Членами группы могут проводиться регулярные неформальные собрания сортировки. Во время этих занятий могут обсуждаться детали любых нерешенных инцидентов, с тем, чтобы другие члены группы могли рекомендовать опробование каких-либо вещей, а также предложить преимущества своего собственного опыта. И снова, это есть форма совместного использования знания, которая применяет неявное знание членов группы инфраструктуры и среды. Если группы различаются географически, то для этих собраний могут использоваться средства теле- или видеоконференций.
Иногда применяемая другая форма совместного использования знаний, которая заключается в использовании для задания вопросов почтовых списков, относящихся к конкретной теме. Если у человека имеется вопрос относительно определенной темы, то он может послать его по электронной почте в соответствующий список распределения, для того чтобы кто-либо из списка предложил совет или решение. Например, может существовать один почтовый список, включающий в себя весь персонал со знанием базы данных, второй - для продуктов передачи сообщений, и третий - для основных знаний по операционной системе.
В зависимости от исследуемого инцидента и опыта внутри организации, может оказаться полезным заняться поиском знаний за пределами организации, отправляя вопрос на соответствующий форум в интернете. Доступно большое число форумов и они часто нацеливаются на определенную платформу или приложение, что позволяет обсуждать затруднения и общее знание совместно с персоналом поддержки из других организаций, которые работают с такими же продуктами.
Примечание, касающееся технологии. Некоторые инструментальные средства группы поддержки позволяют прикреплять к регистрационным записям инцидентов электронное доказательство типа файлов регистрации, регистрационных записей событий или журналов заданий. Персонал, работающий с инцидентом, может открывать приложенные документы непосредственно из регистрационной записи инцидента, вместо того, чтобы искать их.
После того, как возможный обходной путь или решение были идентифицированы, их необходимо протестировать вдали от реальной среды, если это возможно. В прошлом слишком часто возникала такая ситуация, когда изменения, реализуемые для решения одного инцидента, приводили к множеству других инцидентов. Во избежание этого персонал поддержки должен тестировать предложенные обходы или решения настолько всесторонне, насколько это возможно, и затем передавать любые необходимые изменения конфигурационной единицы (CI) для реализации через процессы управления изменениями и управления релизами.
Если тестирование демонстрирует, что предложенное решение работать не будет, то должны продолжиться процессы исследования и диагностики, которые должны осуществляться до тех пор, пока не будет идентифицировано успешное решение. Если тестирование прошло успешно, то решение может быть подвергнуто процессу разрешения и восстановления.
В любое время в течение исследования и диагностики инцидента может возникнуть необходимость объявления серьезного инцидента. Серьезные инциденты - это инциденты с высокой или потенциально высокой степенью воздействия, требующие реакции, которая лежит за рамками, установленными для "обычных" инцидентов. Как правило, такие инциденты требуют координации по всей компании, эскалации управления, мобилизации дополнительных ресурсов и усиленных связей. Несмотря на то, что инцидент может подозреваться как "серьезный" при первоначальном его обнаружении, персонал поддержки должен подтвердить его рамки и степень воздействия прежде, чем будет инициализирована процедура по серьезным инцидентам. Инциденты, подозреваемые как "серьезные", должны регистрироваться с высоким приоритетом и уведомлением соответствующей группы решения так, чтобы она могла как можно быстрее подтвердить рамки и степень воздействия.
Организации должны документировать критерии, в соответствии с которыми они идентифицируют серьезные инциденты. Например, банк, занимающийся обслуживанием мелкой клиентуры, может считать, что любой инцидент, воздействующий на нормальный сервис в 20 или более филиалах, должен классифицироваться как серьезный инцидент. Подозреваемые серьезные инциденты должны помечаться для дежурного менеджера инцидентов, который отвечает за принятие решения о необходимости инициализации процедуры по серьезным инцидентам на основании доказательств и после консультации с соответствующими сторонами.
Во время серьезных инцидентов процесс исследования, диагностики, разрешения, восстановления и закрытия все еще продолжается. Однако процедура по главным инцидентам следит за этими действиями и обеспечивает повышенные координацию, ресурсы и связь.
Если инцидент не является серьезным инцидентом, то он может все еще нуждаться в некоторой форме эскалации. Эскалация - это механизм, помогающий разрешать инцидент в пределах согласованных целей сервиса. Существуют две формы эскалации: эскалация управления, или иерархическая эскалация, и эскалация функциональных возможностей.
Эскалация управления, или иерархическая эскалация, может выполняться на любой стадии в течение жизненного цикла инцидента, если предполагается, что инцидент не будет решен удовлетворительно или вовремя. Персонал службы поддержки и групп решения отвечает за расширение инцидента до управления, как только становится вероятным неудовлетворительное или несвоевременное решение. Эскалация должна инициализироваться как можно скорее, с тем, чтобы у управления оставалось время на оценку ситуации и осуществление корректирующего действия. Корректирующие действия могут использоваться для назначения дополнительных ресурсов или поиска специализированных навыков откуда-либо, как внутри организации, так и вне ее.
На протяжении жизненного цикла инцидента также должна рассматриваться потребность в эскалации функциональных возможностей. Эскалация функциональных возможностей касается передачи инцидента другому персоналу поддержки, который лучше оснащен для продвижения инцидента и достижения разрешения в пределах согласованных целей сервиса. В ярусной структуре поддержки это действие может включать в себя передачу инцидента от группы второй линии группе третьей линии; а в структуре на основе платформы это может являться назначением более опытному персоналу в пределах группы или же назначения другой группе, поскольку категория инцидента отличается от категории, предполагаемой вначале. Эскалация функциональных возможностей также включает в себя рассмотрение инцидента с внешними ресурсами поддержки и поставщиками.
Все действия по эскалации должны регистрироваться в регистрационной записи инцидента.
Примечание, касающееся технологии. Инструментальные средства группы поддержки позволяют осуществлять автоматическую эскалацию на основе затраченного или оставшегося времени, пока не будут достигнуты цели сервиса. Время эскалации должно быть тщательно спланировано, так, чтобы не были превышены цели уровня сервиса. Нижним ярусам поддержки необходимо предоставить разумное время для разрешения инцидентов, с тем, чтобы уменьшить воздействие на более дорогостоящие ресурсы “верхнего яруса”.
Организации могут принимать решение по внедрению автоматического управления и эскалации функциональных возможностей, основываясь на факторах времени. Автоматические действия во многих случаях могут просто включать в себя уведомление соответствующих лиц о том, что для определенного инцидента должна осуществляться эскалация, с тем, чтобы они могли предпринять соответствующие действия. Инструментальные средства могут остановить “часы эскалации”, если инцидент находится в определенном состоянии, например, “ожидает доказательства”, если персонал поддержки запросил дополнительную информацию и ожидает контакта для ее предоставления, или же "разрешен", когда инцидент считается разрешенным, но аналитики поддержки ожидают подтверждения этого от инициатора перед закрытием запроса. В таких случаях, когда прогресс зависит от инициатора, “часы эскалации” могут быть остановлены. Однако менеджер по инцидентам должен следить за тем, что персонал поддержки не “использует систему”, запрашивая дополнительные "трудные для получения" доказательства, с тем, чтобы увеличить время, в течении которого он должен исследовать проблему.
На приведенном ниже рисунке показан пример регистрационной записи инцидента со значениями времени эскалации и запланированного разрешения.
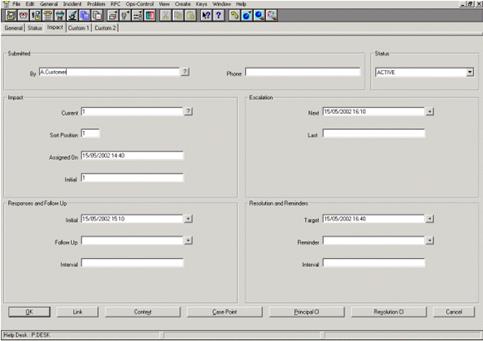
Рисунок 19. Пример регистрационной записи инцидента со значениями времени эскалации и запланированного разрешения
Дата добавления: 2015-10-29; просмотров: 134 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Начальная поддержка | | | Процедура по серьезным инцидентам |