Читайте также:
|
Процесс поиска дублированного контента в Интернете для движка Google мы проиллюстрируем примерами. В примерах, начиная с рис. 6.24 и до рис. 6.27, сделаны три допущения:
• страница с текстом – это страница с дублированным контентом, а не просто фрагмент, как это показано на рисунках;
• все страницы с дублированным контентом находятся в разных доменах;
• показанные далее шаги были упрощены, чтобы сделать процесс легким и четким (насколько это возможно). Это, безусловно, не является точным описанием поведения Google, но передает смысл.

Рис. 6.24. Google находит дублированный контент

Рис. 6.25. Google сравнивает все копии дублированного контента

Рис. 6.26. Дублированные копии выбрасываются
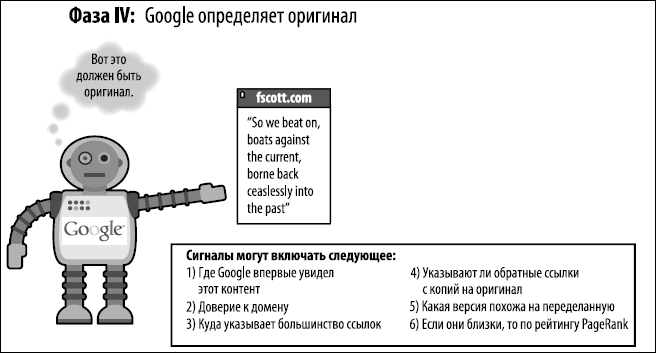
Рис. 6.27. Google выбирает оригинал
Имеется несколько фактов, касающихся дублированного контента, которые заслуживают особого упоминания, поскольку они могут запутать web-мастера, который является новичком в области проблем дублированного контента. Рассмотрим эти факторы.
• Местоположение дублированного контента.
Если весь этот контент находится на моем сайте, является ли он дублированным? Да, потому что дублированный контент может получиться как в пределах одного сайта, так и на разных сайтах.
• Процент дублированного контента.
Какой процент страницы должен быть дублирован, чтобы попасть под фильтрацию дублированного контента? К сожалению, поисковые движки никогда не раскрывают эту информацию, поскольку это нанесло бы ущерб их способности предотвращать данную проблему.
Почти уверенно можно утверждать, что этот процент у всех движков постоянно меняется и что при выявлении дублированного контента производится не просто прямое сравнение. Итог таков: чтобы считаться дубликатами, страницы не обязательно должны быть идентичными.
• Соотношение кода и текста.
А что если наш код очень большой и на странице мало уникальных элементов HTML? Не подумает ли Google, что все страницы являются дубликатами друг друга? Нет. Поисковым движкам нет никакого дела до вашего кода, их интересует контент ваших страниц. Размер кода становится проблемой только тогда, когда он становится чрезмерным.
• Соотношение навигационных элементов и уникального контента.
Все страницы моего сайта имеют большую навигационную полосу, много заголовков и нижних колонтитулов, но совсем мало контента. Не сочтет ли Google все эти страницы дублированными? Нет. Google, а также Yahoo! и Bing учитывают элементы навигации еще до оценки страниц на дублирование. Они хорошо знакомы с компоновкой web-сайтов и понимают, что наличие постоянных структур на всех страницах (или большом их количестве) – это совершенно нормально. Они обращают внимание на уникальные части страниц и почти совершенно игнорируют остальные.
• Лицензированный контент.
Что делать, если я хочу избежать проблем с дублированием контента, но у меня есть контент из других web-источников, который я лицензировал для показа своим посетителям? Используйте meta name = "robots" content="noindex, follow". Разместите это в заголовке вашей страницы и поисковые движки будут знать, что этот контент не для них. Это лучшая практика, поскольку люди все равно смогут посетить эту страницу, сделать на нее ссылку, а ссылки на этой странице будут сохранять свою ценность.
Другой вариант – получить эксклюзивные права на владение этим контентом и его публикацию.
Дата добавления: 2015-10-13; просмотров: 100 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Последствия дублированного контента | | | Как избежать дублированного контента на вашем сайте |