Оптимально сгруппированные и визуально представленные статистические данные, тем не менее, не позволяют увидеть и обосновать глубокие закономерности исследуемых явлений. Для проведения статистического анализа необходимы определенные числовые характеристики, которые наилучшим образом отражают полученные результаты экспериментов. Поэтому вычисление простых и понятных показателей, обобщающих наиболее существенные свойства статистических данных, является одним из основных методов математической статистики. Традиционно для обобщения большого количества экспериментальных данных используются определенные так называемые средние выборочные показатели. Рассмотрим наиболее известные типы средних. В любой совокупности выборочных данных естественно выделяется значение, которое появляется чаще других.
Определение 2.1 Если в выборке x 1, x 2, …, x n есть одно выборочное значение, имеющее наибольшую частоту, то оно называется модой данной выборки.
Для обозначения моды используется символ Х  .
.
Пример 2.1 Рассмотрим выборочные данные о размерах обуви двадцати женщин.
Таблица 2.1 – Вариационный ряд данных размеров обуви
| Размер | 35 36 37 38 39 40 |
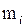
| 1 3 7 5 3 1 |
В данной выборке преобладает 37-й размер обуви, поэтому мода этой выборки равна 37, то есть Х  .
.
■
Выборка не имеет моды, когда в ней нет единственного элемента с наибольшей частотой. Если в выборке несколько значений повторяются больше других одинаково часто, то выборка называется мультимодальной (бимодальной, тримодальной и т. д.). Для определения моды надо знать частоту каждого выборочного значения. В случае, когда мы имеем только интервальный статистический ряд, то из всех интервалов можно выделить модальный интервал, который содержит самые повторяемые значения выборки. Если длина каждого интервала статистического ряда равна 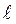 , то для вычисления моды выполняется следующая процедура.
, то для вычисления моды выполняется следующая процедура.
Дата добавления: 2015-10-21; просмотров: 136 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Упражнения | | | Алгоритм вычисления моды статистического ряда |