|
Читайте также: |
4. Процент от всех сделок, в которых принимали участие торговые агенты.
With T as (Select Cust_First_Name, Cust_Last_Name, Sum(Unit_Price) as sums
From Customers Join Orders Using(Customer_Id)
Join Order_Items Using(Order_Id)
Group By Cust_First_Name, Cust_Last_Name)
Select Cust_First_Name, Cust_Last_Name, Round(Sums/(Select Sum(Sums) From T),5) *100 As "%"
From T;
Результат:
CUST_FIRST_NAME CUST_LAST_NAME %
-------------------- -------------------- -
Maurice Hasan 1,007
Divine Aykroyd 0,391
Dheeraj Alexander 0,097
Manisha Taylor 1,043
Gustav Steenburgen 4,395
Markus Rampling 7,094
Sachin Spielberg 1,608
Matthias Hannah 1,833
Maurice Mahoney 3,633
Maximilian Henner 0,313
Dieter Matthau 0,501
Divine Sheen 3,229
Frederico Romero 2,731
Eddie Boyer 3,982
Charlotte Kazan 0,138
Christian Cage 2,211
Sidney Capshaw 0,689
Matthias MacGraw 3,41
Meenakshi Mason 4,083
Ishwarya Roberts 6,27
Geraldine Martin 2,133
Frederic Grodin 0,406
Ernest Weaver 0,075
Guillaume Edwards 3,817
Diane Higgins 0,073
Dianne Sen 0,387
Elizabeth Brown 0,751
Goldie Montand 2,159
Eddie Stern 0,311
Ernest George 0,044
Ernest Chandar 0,085
Charlotte Fonda 0,198
Gerard Hershey 0,006
Dheeraj Davis 1,196
Sivaji Landis 5,501
Sachin Neeson 0,991
Frederico Lyon 0,861
Hema Voight 3,168
Harrison Sutherland 3,414
Matthias Cruise 5,464
Mammutti Pacino 2,996
Elia Fawcett 3,17
Maurice Daltrey 1,102
Goldie Slater 2,548
Harrison Pacino 5,181
Harry Dean Fonda 0,85
Constantin Welles 4,458
47 rows selected
Комментарий:
Подзапрос Т возвращает Сумму выручки сделок, которые сопровождал торговый агент
Для этого связываем таблицы Customers, Orders, Order_Items
А уже в основном селекте суммы каждого агента будем делить на сумму выручки всех агентов
11. Вывести календарь на текущий месяц (2 цифры месяца месяц (по английски большими буквами) год (четыре цифры) день недели (по-английски маленькими буквами)) все через один пробел. Хвостовых и лидирующих пробелов быть не должно
With X As (Select Trunc(Sysdate,'mm')+Level-1 D
From Dual Connect By Level <= To_Char(Last_Day(Sysdate),'dd'))
Select To_Char(D,'dd fmMONTH yyyy day','NLS_DATE_LANGUAGE=AMERICAN') Calendar
From X Order By 1;
CALENDAR
---------------------------
01 MAY 2012 tuesday
02 MAY 2012 wednesday
03 MAY 2012 thursday
04 MAY 2012 friday
05 MAY 2012 saturday
06 MAY 2012 sunday
07 MAY 2012 monday
08 MAY 2012 tuesday
09 MAY 2012 wednesday
10 MAY 2012 thursday
11 MAY 2012 friday
12 MAY 2012 saturday
13 MAY 2012 sunday
14 MAY 2012 monday
15 MAY 2012 tuesday
16 MAY 2012 wednesday
17 MAY 2012 thursday
18 MAY 2012 friday
19 MAY 2012 saturday
20 MAY 2012 sunday
21 MAY 2012 monday
22 MAY 2012 tuesday
23 MAY 2012 wednesday
24 MAY 2012 thursday
25 MAY 2012 friday
26 MAY 2012 saturday
27 MAY 2012 sunday
28 MAY 2012 monday
29 MAY 2012 tuesday
30 MAY 2012 wednesday
31 MAY 2012 thursday
31 rows selected
Комментарий:
В разделе WITH выбираем текущую дату, усеченную до месяца и запускаем цикл.
В селекте приводим дату к нужному виду, выбираем язык и упорядочиваем по номерам дней в месяце по возрастанию.
12. Вывести фамилию менеджера, количество его подчиненных всех уровней, а также количество подчиненных всех уровней, работающих в тех же отделах.
Пример вывода:
| LAST_NAME | NUM_S | NUM_DEP |
| King | ||
| Kochhar | ||
| De Haan | ||
| Hunold | ||
| Greenberg | ||
| Raphaely | ||
| Weiss | ||
| ……………… |
Select Last_Name,
(Select Count(*)
From Employees T2
Start With T2.Manager_Id=T1.Employee_Id
Connect By Prior Employee_Id = Manager_Id) NUM_S,
(Select Count(*)
From Employees T2
Where T1.Department_Id=T2.Department_Id
Start With T2.Manager_Id=T1.Employee_Id
Connect By Prior Employee_Id = Manager_Id) NUM_Dept
From Employees T1
LAST_NAME NUM_S NUM_DEPT
------------------------- ----- --------
King 106 2
Kochhar 11 0
De Haan 5 0
Hunold 4 4
Ernst 0 0
Weiss 8 8
Fripp 8 8
Kaufling 8 8
Mikkilineni 0 0
Landry 0 0
Rogers 0 0
Patel 0 0
Rajs 0 0
Russell 6 6
Partners 6 6
Errazuriz 6 6
Cambrault 6 6
Zlotkey 6 5
Bell 0 0
Everett 0 0
McCain 0 0
Jones 0 0
Walsh 0 0
Feeney 0 0
OConnell 0 0
107 rows selected
Комментарий:
NUM_S, --количество подчиненных всех уровней. Перебирая всех сотрудников у которых Manager_Id равен текущему Employee_Id(меняется при изменении фамилии)
NUM_Dept --количество подчиненных всех уровней, работающих в тех же отделах. Так же как в NUM_S только добавлено условие одинакового отдела
13. Вычислить число Пи с точностью 40 знаков после запятой.
Для расчета использовать быстро сходящуюся последовательность
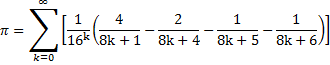
Select B||A "Число пи с точ. до 40 знака"
From (
Select Substr((Sum(Substr(Pi, 4, 100))*10),2) A, Substr(Sum(Pi),1,4) B
From (
Select Pi
From Dual
Model
Return All Rows
Dimension By (0 D)
Measures (0 Pi)
Rules Iterate (100)
(Pi[iteration_number] = 1 /
Power(16, (iteration_number)) *
(
4 / (8 * (iteration_number) + 1) -
2 / (8 * (iteration_number) + 4) -
1 / (8 * (iteration_number) + 5) -
1 / (8 * (Iteration_Number) + 6)
)
)));
Результат:
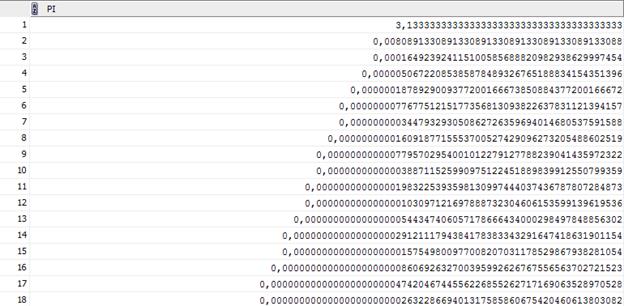
Число пи с точ. до 40 знака
-------------------------------------------
3,1415873903473333870692083336288769175294
Комментарий:
Из этих слагаемых(полученных через model) будет складываться наше число пи
Для каждого к:
Substr((Sum(Substr(Pi, 4, 100))*10),2) A, Substr(Sum(Pi),1,4) B
A – считаем сумму слагаемых начиная с третьего знака после запятой.
B – считаем сумму слагаемых начиная с первого знака до второго после запятой
Соединим полученные суммы и получим результат с точностью 40 знаков после запятой
14. Определить ближайший к заданной дате год, когда 31 декабря придется на субботу.
Select To_Char(Datex, 'YYYY') As Year
From (Select To_Date('&date', 'DD-MM-YYYY') As Datex From Dual)
Model
Dimension By (0 Dim)
Measures(Datex)
Rules Iterate (100500) Until (To_Char(Datex[0]) Like '31.12%' And To_Char(Datex[0], 'D') = '6')
(DateX[0] =
Case
When To_Char(Datex[0], 'MM') = '12' Then
Case
When To_Char(Datex[0], 'DD') = '31' Then
Case
When To_Char(Datex[0], 'D') = '6' Then Datex[0]
Else Datex[0] + 1
End
Else Datex[0] + 1 End
Else Datex[0] + To_Yminterval('00-01') End);
Комментарий:
Из таблицы dual выбираем значение даты, когда 31 декабря придется на субботу.
Для Этого С Помощью Model Изменяем Введенную Дату Пока Она Не Станет Искомой
-Если Месяц Не Декабрь, Прибавляем К Дате Месяц
-Если Месяц Декабрь, Но Не 31 Или Же 31, Но Не 6 День Недели (Суббота), То Добавляем День
-Если все условия соблюдены, дата не изменяется, происходит выход из цикла по условию
To_Char(Date_Sun[0]) Like '31.12%' And To_Char(Date_Sun[0], 'D') = '6'
Из полученной даты извлекаем год и выводим его на экран.
15. Одной командой SELECT вывести список сотрудников компании, имеющих наименьшие оклад среди сотрудников подразделения, в котором они работают.
Сведения о сотрудниках, для которых неизвестно подразделение компании, к которому они приписаны выводить не нужно.
В результат вывести:
1.Идентификатор подразделения компании, к которому приписан сотрудник.
2. Фамилию сотрудника.
3.Оклад, установленный сотруднику.
В команде SELECT запрещается использовать:
· Фразы WITH, GROUP BY,HAVING, ORDER BY, CONNECT BY, START WITH,
· Условия IN, =ANY, =SOME, NOT IN, <> ALL, EXISTS, NOT EXISTS,
· Подзапросы (subqueries), в том числе подзапросы во фразе FROM,
· Иерархические запросы (hierarchical queries),
· Скалярное выражение подзапроса (scalar subquery expression),
· Агрегатные функции – MIN,MAX, SUM,COUNT, AVG и др.
· Аналитические функции (analytic functions)
Select E2.Department_Id, E2.Last_Name, E2.Salary
From Employees E0 Join Employees E1 On (E0.Department_Id=E1.Department_Id And E0.Salary>E1.Salary) ----отсекаем минимальные зарплаты
---связываем каждого с каждым с разными зарплатами
Right Outer Join Employees E2 On (E0.Employee_Id=E2.Employee_Id) -- свяжем соед.ROJ с полноценной таблицей
Where E0.Salary Is Null
----и у тех у кого E0 заполнится Nullми (т.е. у тех у кого минимальные зарплаты) выведем
Order By E2.Department_Id;
Комментарий:
Мы соединяем две таблицы по department_id, в результате чего получаем соединение каждого с каждым в данном отделе, далее пишем условие, чтобы зарплата первого была больше зарплаты второго, чем мы отсеиваем все с минимальной зарплатой.
Потом свяжем соединением Right Outer Join с полноценной таблицей
И у тех у кого E0 заполнится Nullми (т.е. у тех у кого минимальные зарплаты) выведем (поставив условие Where E0.Salary Is Null)
16. Создать запрос для определения произведения всех чисел в столбце Department_Id таблицы Departments.
Select Exp(Sum(Ln(Department_Id))) as "Произведение номеров отделов"
From Departments;
Произведение номеров отделов
----------------------------
Комментарий:
Распишем нашу формулу:
Произведение номеров отделов=x
x = (Id1 * id2 *id3*….)
ln(x) = ln(Id1 * id2 *id3*….)
ln(x) = ln(Id1) + ln(id2) + ln(id3)+… => SUM(LN(Department_id))
x = e (ln(x)) => EXP(SUM(LN(Department_id)))
x = 10888869450418352160768000000000000002060000000000000000
17. В произвольной строке, состоящей из символьных элементов, разделенных запятыми, отсортировать элементы по алфавиту. Например, символьную строку
abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe
преобразовать к виду:
abc,cde,df,ef,ewe, fw,gh,mn,ss,test,wwe.
With T As
(Select Regexp_Substr('abc,cde,ef,gh,mn,test,ss,df,fw,ewe,wwe', '[^,]+', 1, Level) Str
From Dual
Connect By Instr('abc,cde,ef,gh,mn,test,ss,df,fw,ewe,wwe', ',', 1, Level - 1) > 0
Order By 1)
Select 'abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe' Исходник, Max(Ltrim(Sys_Connect_By_Path(Str, ', '), ', ')) Результат
From (Select T.Str,Rownum Rn
From T)
Start With Rn=1
Connect By Prior Rn+1=Rn;
ИСХОДНИК РЕЗУЛЬТАТ
---------------------------------------------- --------------------------------------------------------------
abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe abc, cde, df, ef, ewe, fw, gh, mn, ss, test, wwe
Комментарий:
С помощью регулярного выражения и цикла проходим по строке до тех пор, пока встречается разделительный символ (‘,’) и выводим каждую новую подстроку в новой строке Regexp_Substr('abc,cde,ef,gh,mn,test,ss,df,fw,ewe,wwe', '[^,]+', 1, Level)
Сортируем полученный столбец по возрастанию ORDER BY 1 в Т
Сборка столбика в строчку будет производиться с помощью функции Sys_Connect_By_Path(Str, ', ')
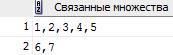
18. Имеется таблица с двумя столбцами – дочерняя вершина и родительская вершина. Определить наборы вершин, образующих связанные множества. Например, для таблицы:
| Дочерняя вершина | Родительская вершина |
результат должен быть
| Связанные множества |
| 1,2,3,4,5 |
| 6,7 |
Create Table Tab1(Child_Number Number(7,0),Parent_Number Number(7,0));
Insert Into Tab1 Values(1,2);
Insert Into Tab1 Values(2,4);
Insert Into Tab1 Values(4,5);
Insert Into Tab1 Values(4,3);
Insert Into Tab1 Values(6,7);
With
Tmp As
(Select Ch, Ch||Sys_Connect_By_Path(Parent_Number, ',') Str
from (select * from (select connect_by_root(Child_Number) Ch, Parent_Number
From Tab1
Connect By Prior Parent_Number = Child_Number
Order By 1)
Where Ch Not In
(Select Parent_Number From (Select Connect_By_Root(Child_Number) Ch, Parent_Number
From Tab1
Connect By Prior Parent_Number = Child_Number
Order By 1))
)
Connect By Prior Ch = Ch
And Prior Parent_Number<Parent_Number)
Select Str "Связанные множества" From Tmp
Where (Ch, Length(Str)) In (Select Ch, Max(Length(Str)) From Tmp Group By Ch)
Результат:
Комментарий:
Для решения задачи создадим вспомогательную таблицу Tab1, она возвращает дочерним значениям их родительские корни.
В Tab1 (CONNECT_BY_ROOT - унарный оператор, который верен только в иерархических запросах. Когда вы указываете колонку с этим оператором, то Oracle возвращает значение колонки используя данные их корневой строки.
Ставим условие, что дочернее значение Сh не может быть равно родительскому значению.)
В основном селекте отбрасываем промежуточные результаты(выбираем пути макс. длины, по их доч. знач) и выводим эти пути.
19. Определить список последовательностей подчиненности от преподавателей, не имеющих начальника, до преподавателей, не имеющих подчиненных. Результат представить в виде:
Костыркин-> Викулина-> Студейкин->Соколов (не имеет подчиненных)
With List As (Select Rownum X,Level Y, Ltrim(Sys_Connect_By_Path(Фамилия, '->'),'->') Phraze
From Преподаватели
Where Level >= 2
Start With Подчиняется Is Null
Connect By Prior Номер_Преподавателя = Подчиняется
Order By Rownum)
Select A1.Phraze || ' (не имеет подчинённых)' "RESULT"
From
List a1
Full Join
List A2
On A1.X+1 = A2.X
Where A1.Y >= A2.Y Or A2.Y Is Null
Order By "RESULT";
Комментарий:
Здесь подзапрос List, который выводит иерархию преподавателей, начиная с преподавателя, который никому не подчиняется. В данной выборке присутствуют столбцы rownum X и level Y, добавленные для того, чтобы по rownum x можно было объединить одинаковые таблицы A1 и A2, а по level Y я брал максимально возможный уровень, отсекая при этом промежуточные результаты.
Связь дает результат: откуда при помощи Where мы выбираем нужное
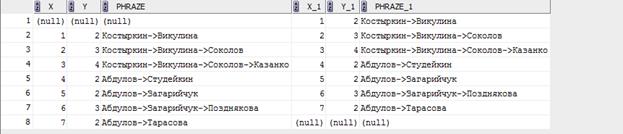
RESULT
Абдулов->Загарийчук->Позднякова (не имеет подчинённых)
Абдулов->Студейкин (не имеет подчинённых)
Абдулов->Тарасова (не имеет подчинённых)
Костыркин->Викулина->Соколов->Казанко (не имеет подчинённых)
20. Создать запрос, который выводит фамилию преподавателя, зарплату и процент, который составляет его зарплата от суммарной зарплаты преподавателей кафедры, на которой он работает (с использованием аналитических функций).
Select Фамилия,Зарплата,
Round(Ratio_To_Report(Зарплата) Over (Partition By Кафедра),3)*100 "%"
From Преподаватели;
Комментарий:
Функция подсчета долей(Ratio_To_Report) позволяет одной SQL-операцией получить для каждой строки ее "вес" в таблице в соответствии с ее значениями
ФАМИЛИЯ ЗАРПЛАТА %
-------------------- -------- -
Казанко 2000 19
Соколов 1500 14,3
Викулина 3000 28,6
Костыркин 4000 38,1
Позднякова 2500 20,8
Загарийчук 2000 16,7
Студейкин 2500 20,8
Тарасова 2000 16,7
Абдулов 3000 25
9 rows selected
ВАРИАНТ 23
(Базы данных HR и OE)
1. Имеется таблица с числовым столбцом первичного ключа, например:
ID
Для каждого значения ID получить набор значений в виде "горки":
| ID | Rezult |
| 1,3,1 | |
| 1,3,6,3,1 | |
| 1,3,6,8,6,3,1 | |
| 1,3,6,8,9,8,6,3,1 | |
| 1,3,6,8,9,11,9,8,6,3,1 |
Задачу решить без использования Model, аналитических функций, регулярных выражений, иерархических запросов, рекурсии.
Вариант 1
select ID, nvl2(a7,a7||',','')||nvl2(a6,a6||',','')||nvl2(a5,a5||',','')||nvl2(a4,a4||',','')
||nvl2(a3,a3||',','')||nvl2(a2,a2||',','')||nvl2(a1,a1,'')||nvl2(a2,','||a2,'')||nvl2(a3,','||a3,'')
||nvl2(a4,','||a4,'')||nvl2(a5,','||a5,'')||nvl2(a6,','||a6,'')||nvl2(a7,','||a7,'') as Result
from
(select pp.id ID, a1,a2,a3,a4,a5,a6,a7
from (select a1,a2,a3,a4,a5,a6,a7,rownum r2
from
(select distinct p1.ID a1, p2.ID a2, p3.ID a3, p4.ID a4, p5.ID a5, p6.ID a6, p7.ID a7
from
PkId p1 left join PkId p2 on p2.ID < p1.ID
left join PkId p3 on p3.ID < p2.ID
left join PkId p4 on p4.ID < p3.ID
left join PkId p5 on p5.ID < p4.ID
left join PkId p6 on p6.ID < p5.ID
left join PkId p7 on p7.ID < p6.ID
order by p1.ID, p2.ID, p3.ID, p4.ID, p5.ID, p6.ID, p7.ID)) ps
right join
(select Id, rownum r1 from pkId) pp
on Pp.Id = ps.a1 and ps.r2 = power(2,pp.r1-1))
Вариант 2
select tab1.id, str1||str2 as "Result" from
(select id, LTRIM(SYS_CONNECT_BY_PATH(id, ','), ',') str1, rownum R1
from
(select id, rownum r2 from PkID)
start with r2 = 1
connect by prior r2 = r2 - 1) tab1
left join
(select id, ltrim(ltrim(SYS_CONNECT_BY_PATH(id, ','), ','), '0987654321') str2, rownum R2
from
(select id, rownum r2 from PkID)
where id = 1
start with r2 = r2
connect by r2 = prior r2 - 1) tab2
on tab1.R1 = tab2.R2
Вариант 1
ID RESULT
---------- ------------------------------------------------------------------------------------------------------------
1 1
3 1,3,1
6 1,3,6,3,1
8 1,3,6,8,6,3,1
9 1,3,6,8,9,8,6,3,1
11 1,3,6,8,9,11,9,8,6,3,1
23 1,3,6,8,9,11,23,11,9,8,6,3,1
7 rows selected
Комментарий:
1) создаем таблицу PkId как в примере
2) соединяем ее саму с собой шесть раз по условию, что значение в присоединяемой таблице меньше чем в текущей, чем обеспечиваем убываемость значений в строках по столбцам. Будем называть ее Ps
3) выбираем значения ID и всех столбцов Ps таблицы. Путем соединения PkId с Ps таблицей по условию равенства Id в Ps и Id в PkId и по условию зависимости номеров строк(в Ps нужная строка будет находится как 2 в степени номера строки PkId)
4) выбираем столбец Id и Result
Вариант 2
ID Result
---------- --------------------------------------------------------------------------------------------------------
1 1
3 1,3,1
6 1,3,6,3,1
8 1,3,6,8,6,3,1
9 1,3,6,8,9,8,6,3,1
11 1,3,6,8,9,11,9,8,6,3,1
23 1,3,6,8,9,11,23,11,9,8,6,3,1
55 1,3,6,8,9,11,23,55,23,11,9,8,6,3,1
8 rows selected
Комментарий:
1) Первый подзапрос выводит с помощью иерархии путь от корня до текущего значения
2) Второй подзапрос выводит в обратном порядке без первого значения
3) Select str1||str2 выводит конкатенацию строк из первого и второго подзапросов
2. Создать запрос для определения произведения количеств сотрудников в отделах.
select round(exp(sum(ln(ID)))) as composition
from (select count(employee_id) as "ID"
from employees
group by department_id);
COMPOSITION
-----------
Комментарий:
1) Подзапрос select count(employee_id) as "ID"
from employees
group by department_id
выводит таблицу с количествами сотрудников в отделах без вывода отделов, к которым они относятся. Обозначим столбец как ID
2) Произведение столбцов из подзапроса выводим с помощью четырех вложенных функций:
Сумма логарифмов каждой строки sum(ln(ID)) – логарифм произведения строк
Экспонента в степени этого логарифма exp(sum(ln(ID))) – произведение строк подзапроса
3) Усечем до целого, так как exp(sum(ln(ID)) возвращает значение со знаками после запятой.
3. Имеется стандартная шахматная доска 8 х 8 = 64 клетки.
Расставить 8 ферзей так, чтобы ни один из них не находился под боем другого.
То есть два ферзя не могут находиться ни на одной горизонтали, ни на одной вертикали, ни на одной диагонали.
Требуется одной командой SELECT вывести все варианты решения задачи в виде (каждая строка - это один вариант решения задачи о восьми ферзях):
Столбец 1. Положение ферзя на вертикали "а" (в виде ‘aN’)
Столбец 2. Положение ферзя на вертикали "b" (в виде ‘bN’)
Столбец 3. Положение ферзя на вертикали "с" (в виде ‘cN)
Столбец 4. Положение ферзя на вертикали "d" (в виде ‘dN’)
Столбец 5. Положение ферзя на вертикали "е" (в виде ‘eN’)
Столбец 6. Положение ферзя на вертикали "f" (в виде ‘fN’)
Столбец 7. Положение ферзя на вертикали "g" (в виде ‘gN’)
Столбец 8. Положение ферзя на вертикали "h" (в виде ‘hN’)
Пример одного решения (одной строки результата):
| A | B | C | D | E | F | G | H |
| a1 | b1 | c1 | d1 | e1 | f1 | g1 | h1 |
select 'a' || a A, 'b' || b B, 'c' || c C, 'd' || d D, 'e' || e E, 'f' || f F, 'g' || g G, 'h' || h H
from
(
select a, b, c, d, e, f, g, h,
case when a = b or abs(a - b) = 1 or a = c or abs(a - c) = 2 or a = d or abs(a - d) = 3 or a = e or abs(a - e) = 4 or a = f or abs(a - f) = 5 or a = g or abs(a - g) = 6 or a = h or abs(a - h) = 7
then 0
else case when b = c or abs(b - c) = 1 or b = d or abs(b - d) = 2 or b = e or abs(b - e) = 3 or b = f or abs(b - f) = 4 or b = g or abs(b - g) = 5 or b = h or abs(b - h) = 6
then 0
else case when c = d or abs(c - d) = 1 or c = e or abs(c - e) = 2 or c = f or abs(c - f) = 3 or c = g or abs(c - g) = 4 or c = h or abs(c - h) = 5
then 0
else case when d = e or abs(d - e) = 1 or d = f or abs(d - f) = 2 or d = g or abs(d - g) = 3 or d = h or abs(d - h) = 4
then 0
else case when e = f or abs(e - f) = 1 or e = g or abs(e - g) = 2 or e = h or abs(e - h) = 3
then 0
else case when f = g or abs(f - g) = 1 or f = h or abs(f - h) = 2
then 0
else case when g = h or abs(g - h) = 1
then 0
else 1
end
end
end
end
end
end
end Bool
from
(select level a from dual connect by level <= 8)
cross join
(select level b from dual connect by level <= 8)
cross join
(select level c from dual connect by level <= 8)
cross join
(select level d from dual connect by level <= 8)
cross join
(select level e from dual connect by level <= 8)
cross join
(select level f from dual connect by level <= 8)
cross join
(select level g from dual connect by level <= 8)
cross join
(select level h from dual connect by level <= 8)
)
where Bool = 1;
A B C D E F G H
-----------------------------------------------------------------------------------------------------------------------
a4 b2 c7 d3 e6 f8 g5 h1
a5 b7 c2 d6 e3 f1 g4 h8
92 rows selected
Комментарий:
1) создаем запрос select level a from dual connect by level <= 8
который выдает числа от 1 до 8:
2) делаем cross join 8 таких столбцов
(select level a from dual connect by level <= 8)
cross join
(select level b from dual connect by level <= 8)
cross join
(select level c from dual connect by level <= 8)
cross join
(select level d from dual connect by level <= 8)
cross join
(select level e from dual connect by level <= 8)
cross join
(select level f from dual connect by level <= 8)
cross join
(select level g from dual connect by level <= 8)
cross join
(select level h from dual connect by level <= 8)
)
Как результат – таблица вариантов расположения ферзей, где ферзи не могут находится на одной вертикали
3) далее вложенными case удаляем варианты расположения ферзей на одной горизонтали и диагонали, т.е. выбираем столбец, который содержит 1, если строка соответствует нашим ограничениям и 0, если нет.
как пример: case when e = f or abs(e - f) = 1 or e = g or abs(e - g) = 2 or e = h or abs(e - h) = 3
then 0 – возвращение 0, если значение в е совпадает с f, или g, или h (это удаляет варианты расположения на одной горизонтали), а также
e = f +- 1 или e = g +- 1 e = h +- 1 (это удаляет варианты расположения на одной диагонали)
4) выводим получившиеся столбцы:
select a, b, c, d, e, f, g, h,
case when a = b or abs(a - b) = 1 or a = c or abs(a - c) = 2 or a = d or abs(a - d) = 3 or a = e or abs(a - e) = 4 or a = f or abs(a - f) = 5 or a = g or abs(a - g) = 6 or a = h or abs(a - h) = 7
Дата добавления: 2015-08-18; просмотров: 132 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Main_Table PK User_Constraints 21 страница | | | Main_Table PK User_Constraints 23 страница |