|
Читайте также: |
Последней строкой вывести общую сумму месячных доходов всех сотрудников. Вместо названия страны в этой строке вывести строку 'TOTAL' (в верхнем регистре).
Все суммы следует округлить до целых значений (ноль знаком после запятой).
Пример результата:
COUNTRY_NAME MONTH_INCOME
----------------- ------------
Argentina 12345
Jamaica 67890
Russian Federation 93456
United Kingdom 987654
N/A 8050
TOTAL 1169395
select case when tot = 1 then 'TOTAL: '
else case when cname is null then 'N/A' else cname end end country_name,sal as month_income
from (select tot,rez.country_id,sal,c.country_name cname from
(select grouping(country_id) tot,l.country_id,sum(e.salary + nvl(e.commission_pct,0) * e.salary) sal
from employees e left join departments d on e.department_id = d.department_id
left join locations l on d.location_id = l.location_id
group by rollup(l.country_id))rez left join countries c on rez.country_id = c.country_id)
order by tot;
COUNTRY_NAME MONTH_INCOME
---------------------------------------- ------------
Canada 19000
Germany 10000
N/A 8050
United States of America 344400
United Kingdom 383640
TOTAL: 765090
select tot,rez.country_id,sal,c.country_name cname from
(select grouping(country_id) tot,l.country_id,sum(e.salary + nvl(e.commission_pct,0) * e.salary) sal
from employees e left join departments d on e.department_id = d.department_id
left join locations l on d.location_id = l.location_id
group by rollup(l.country_id))rez left join countries c on rez.country_id = c.country_id
Комментарий:
С помощью соединения таблиц и операции rollup получаем промежуточные итоги по каждой стране в виде суммы месячных доходов сотрудников
С помощью case там где значение страны null выводим N/A, а с помощью grouping определяем когда выводить TOTAL.
8. Имеется произвольная символьная строка. Надо найти сумму входящих в нее цифр. Если результат больше 10, то процесс продолжить - снова найти сумму цифр и т.д. Пока не получится цифра.
Пример: Строка t29h8n3m7l88g7999999999999
2+9+8+3+7+8+8+7+9+9+9+9+9+9+9+9+9+9+9+9+9=169
1+6+9=16
1+6=7
with tab as (
select '0sda2321sda' str from dual
union all
select 't29h8n3m7l88g79999999999999' str from dual)
select str, s
from tab
model
partition by (rownum rn)
dimension by (1 d)
measures (str, str s)
rules iterate (1e6) until (length(s[1])=1)
(
s[1] = length(replace(s[1],'1','11'))+length(replace(s[1],'2','222'))
+ length(replace(s[1],'3','3333')) + length(replace(s[1],'4','44444'))
+ length(replace(s[1],'5','555555')) + length(replace(s[1],'6','6666666'))
+ length(replace(s[1],'7','77777777')) + length(replace(s[1],'8','888888888'))
+ length(replace(s[1],'9','9999999999')) - 9*length(s[1])
);
STR S
--------------------------- ---------------------------
0sda2321sda 8
t29h8n3m7l88g79999999999999 7
Комментарий:
С помощью модел мы в цикле проходим по строке до тех пор пока ее длина не станет равной 1 и считаем длину строки, заменяя при этом символы на необходимое нам количество. таким образом мы добиваемся расчета суммы входящих в нее цифр.
9. Используются таблицы стандартной схемы HR.
Одной командой SELECT вывести два столбца:
1. Фамилии сотрудников-руководителей, выстроив их в соответствии с иерархической структурой предприятия, выделяя каждый следующий уровень подчинения сдвигом фамилии на два пробела вправо (идентификатор непосредственного руководителя сотрудника указан в поле MANAGER_ID таблицы EMPLOYEES)
2. Сумму окладов всех сотрудников, подчиненных данному сотруднику (оклад самого сотрудника при суммировании не учитывать).
В выборке не должно быть сведений о сотрудниках, которые никем не руководят.
В построенной иерархии строки должны быть упорядочены в рамках каждого уровня по фамилии сотрудника-руководителя по возрастанию.
Пример результата (данные условные):
TREE SALARY
----------- -------
Kingman 987654
Carbofoss 64321
De De Te 23456
Hunourik 12345
Errorlevin 43210
...
Kochegar 99999
Groomwall 34567
Vickings 8765
Marquez 23456
...
select lpad(' ',level*2 -2,' ')||last_name lstname,
(select sum(salary) from employees
start with employee_id = e.employee_id
connect by prior employee_id = manager_id) - (select sum(salary) from employees where employee_id = e.employee_id) sal
from employees e
where connect_by_isleaf!= 1
start with manager_id is null
connect by prior employee_id = manager_id
order siblings by last_name;
Выводим иерархию сотрудников, исключая тех, кто никем не руководит с помощью connect_by_isleaf
select lpad(' ',level*2 -2,' ')||last_name last_name
from employees e
where connect_by_isleaf!= 1
start with employee_id = 100
connect by prior employee_id = manager_id;
После чего добавляем столбец с зарплатой, исключая оттуда оклад менеджера

10. Для записи чисел римскими цифрами (roman numerals) используются буквы латинского алфавита.
Одной командой SELECT, используя только таблицу DUAL, вычислите, какие буквы встречаются в записи чисел от 1 до 3999 и сколько раз.
В результат выведите 2 столбца:
1. Буква латинского алфавита, используемая для записи римскими цифрами чисел от 1 до 3999.
2. Количество раз использования этой буквы для записи римскими цифрами чисел от 1 до 3999.
Результат упорядочить по столбцу (1) по возрастанию.
with roman_numbers as (select trim(to_char(level,'RN')) numb,
length(trim(to_char(level,'RN'))) len from dual
connect by level <=3999)
select symbol, count(symbol) from
(select rom.numb, x.it, substr(rom.numb, x.it,1) symbol from
(select level it from dual
connect by level <= (select max(len) from roman_numbers)) x
join roman_numbers rom on x.it<=rom.len)
group by symbol
order by symbol
SYMBOL COUNT(SYMBOL)
------ -------------
C 6000
D 2000
I 5600
L 2000
M 6400
V 2000
X 6000
Комментарий:
Перевели числа от 1 до 3999 в римский формат с помощью RN и посчитали количество символов в римском формате записи каждого числа
После чего считаем количество вхождений символа для каждой строки
11. Используются таблицы стандартной схемы HR.
Построить гистограмму символов, присутствующих в фамилиях сотрудников.
Буквы в разных регистрах считаются одинаковыми. В результате буквы должны быть выведены в верхнем регистре.
Если какой-либо символ не встречается в фамилиях сотрудников, то информацию о нем выводить не нужно.
В результат вывести два столбца:
1. Количество вхождений
2. Список символов (в верхнем регистре!), встретившихся такое число раз, которое указанно в столбце 1. Символы в списке не должны повторяться.
Символы в списке должны быть:
a. Упорядочены по алфавиту (по возрастанию)
b. Разделены символами ', ' ("запятая" и "пробел")
c. Перед первым символом не должно быть символов-разделителей
d. После последнего символа также не должно быть символов-разделителей
Результат упорядочить:
1. По количеству вхождений (столбец 1) по убыванию
2. По значениям строк столбца 2 по убыванию
Пример результата (данные условные):
S SYMBS
-------- -----
49 A
47 E
37 N
...
12 G, U
9 B
...
with tab as (select replace(ltrim(max(sys_connect_by_path(last_name,',')),','),',',' ') rez from
(select lower(last_name) last_name, row_number() over (order by last_name) rn from employees)
start with rn = 1
connect by prior rn = rn-1),
rez as (
select 'A' letter, regexp_count(rez,'a',1) cnt from tab
union all
select 'B', regexp_count(rez,'b',1) from tab
union all
select 'C', regexp_count(rez,'c',1) from tab
union all
select 'D', regexp_count(rez,'d',1) from tab
union all
select 'E', regexp_count(rez,'e',1) from tab
union all
select 'F', regexp_count(rez,'f',1) from tab
union all
select 'G', regexp_count(rez,'g',1) from tab
union all
select 'H', regexp_count(rez,'h',1) from tab
union all
select 'I', regexp_count(rez,'i',1) from tab
union all
select 'J', regexp_count(rez,'j',1) from tab
union all
select 'K', regexp_count(rez,'k',1) from tab
union all
select 'L', regexp_count(rez,'l',1) from tab
union all
select 'M', regexp_count(rez,'m',1) from tab
union all
select 'N', regexp_count(rez,'n',1) from tab
union all
select 'O', regexp_count(rez,'o',1) from tab
union all
select 'P', regexp_count(rez,'p',1) from tab
union all
select 'Q', regexp_count(rez,'q',1) from tab
union all
select 'R', regexp_count(rez,'r',1) from tab
union all
select 'S', regexp_count(rez,'s',1) from tab
union all
select 'T', regexp_count(rez,'t',1) from tab
union all
select 'U', regexp_count(rez,'u',1) from tab
union all
select 'V', regexp_count(rez,'v',1) from tab
union all
select 'W', regexp_count(rez,'w',1) from tab
union all
select 'X', regexp_count(rez,'x',1) from tab
union all
select 'Y', regexp_count(rez,'y',1) from tab
union all
select 'Z', regexp_count(rez,'z',1) from tab)
select cnt, ltrim(max(letter),', ') letter from
(select cnt, sys_connect_by_path(letter,', ') letter from
(select letter, cnt, row_number() over (partition by cnt order by letter) rn from rez
where cnt!= 0)
start with rn = 1
connect by prior rn = rn-1 and prior cnt= cnt)
group by cnt
order by cnt desc,letter desc;
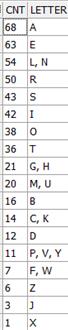
Выделяем все фамилии в одну строчку
select replace(ltrim(max(sys_connect_by_path(last_name,',')),','),',',' ') rez from
(select lower(last_name) last_name, row_number() over (order by last_name) rn from employees)
start with rn = 1
connect by prior rn = rn-1
С помощью регулярных выражений считаем количество каждой из букв в полученной строке
Далее делаем вывод таким образом, чтобы были упорядочены по кол-ву вхождений и значению строк и если количество совпадает, то выводим эти буквы через запятую.
12. Используются таблицы стандартной схемы HR.
Одной командой SELECT вывести список сотрудников, включающий следующие данные:
1. Идентификатор сотрудника
2. Год, когда сотрудник был принят на работу
3. Имя сотрудника
4. Фамилия сотрудника
5. Оклад
6. "Место" сотрудника в группе принятых на работу в одном и том же году, упорядоченных по убыванию зарплаты, а в случае равенства зарплат по возрастанию идентификатора сотрудника.
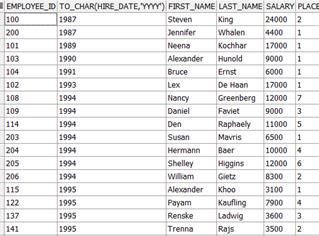
Например, в 1987 году на работу в компанию были приняты 3 сотрудника:
| EMPLOYEE_ID | LAST_NAME | SALARY |
| King | ||
| Whalen | ||
| Smith |
King’у присваивается место 1, поскольку у него наибольший оклад.
Whalen и Smith имеют одинаковые оклады, меньшие, чем у Kingа. Однако, идентификатор Whalenа меньше идентификатора Smithа, поэтому Whalenу присваивается место 2, а Smithу – место 3.
Результат должен быть упорядочен:
1. По году приема на работу по возрастанию.
2. По идентификатору сотрудника по возрастанию.
select employee_id, to_char(hire_date,'yyyy'), first_name, last_name,salary,
RANK() OVER (PARTITION BY to_char(hire_date,'yyyy') order by salary, employee_id desc) place
from employees
order by to_char(hire_date,'yyyy'), employee_id;
Комментарий:
Используем аналитическую функцию RANK, т.к. нам нужно вывести неплотный ранг по времени принятия на работу => PARTITION BY to_char(hire_date,'yyyy')
Необходимо отсортировать по зарплате, а в случае равенства зарплат по возрастанию идентификатора сотрудника => order by salary, employee_id desc
13. Используются таблицы схемы HR.
Одной командой SELECT выбрать сотрудников, имеющих оклад равный минимальному окладу сотрудников подразделения, к которому они приписаны. Исключить из выборки сотрудников, которые не приписаны ни к какому подразделению.
В результат вывести:
1. Идентификатор сотрудника,
2. Фамилию сотрудника,
3. Оклад, установленный сотруднику,
4. Идентификатор подразделения, к которому приписан сотрудник.
Результат отсортировать по возрастанию по полям:
- идентификатор подразделения, к которому приписан сотрудник.
- оклад, установленный сотруднику,
- фамилия сотрудника.
select employee_id, last_name, salary, department_id
from employees
where (department_id, salary) in (select distinct department_id, min(salary) over (partition by department_id)
from employees where department_id is not null)
order by department_id, salary, last_name;
EMPLOYEE_ID LAST_NAME SALARY DEPARTMENT_ID
----------- ------------------------- ---------- -------------
200 Whalen 4400 10
202 Fay 6000 20
119 Colmenares 2500 30
203 Mavris 6500 40
132 Olson 2100 50
107 Lorentz 4200 60
204 Baer 10000 70
173 Kumar 6100 80
102 De Haan 17000 90
101 Kochhar 17000 90
113 Popp 6900 100
206 Gietz 8300 110
Выбираем только тех сотрудников, зарплата которых в своем отделе равна минимальной, а также исключаем сотрудников которые не приписаны к отделам с помощью функции where() in (), указывая внутри что department_id is not null, выделяем отделы с помощью partition by.
14. Используются таблицы стандартной схемы HR.
Одной командой SELECT посчитать количество сотрудников в каждом подразделении, которые никем не руководят.
В результат вывести:
- столбец 1: идентификатор подразделения компании, к которому приписан сотрудник,
- столбец 2: количество сотрудников подразделения, которые никем не руководят
В последней дополнительной строке результата
- столбец 1: слово "ВСЕГО",
- столбец 2: общее количество сотрудников компании, которые никем не руководят.
Результат отсортировать по возрастанию по полю:
- идентификатор подразделения, к которому приписан сотрудник.
Если имеются сотрудники, которые никем не руководят, не приписанные ни к какому подразделению компании, то сведения о них должны быть выведены в первой строке результата.
Пример вывода (значения получены на другом наборе данных):
| DEPT | CNT |
| ... | ... |
| ВСЕГО |
with tab as (select department_id
from (select employee_id
from employees
minus
select manager_id
from employees) t1 left join employees
on t1.employee_id = employees.employee_id)
select to_char(department_id) DEPT, cnt
from (select department_id, cnt
from (select distinct department_id, count(*) over (partition by department_id) cnt
from tab)
order by department_id nulls first)
union all
select 'Всего',
(select count(*)
from tab)
from dual;
DEPT CNT
---------------------------------------- ----------
10 1
20 1
30 5
40 1
50 40
60 4
70 1
80 29
100 5
110 1
Всего 89
Сначала выделяем сотрудников, которые никем не руководят
select employee_id
from employees
minus
select manager_id
from employees
Определяем их количество в каждом отделе
select distinct department_id, count(*) over (partition by department_id) cnt
from tab
Добавляем итоговый результат
select 'Всего',
(select count(*)
from tab)
from dual
15. Используются таблицы стандартной схемы HR.
Одной командой SELECT вывести информацию о сотрудниках, приписанных к подразделениям компании с идентификаторами 10, 30, 50, 90.
Выборка должна быть отсортирована:
- по идентификатору подразделения компании (по возрастанию),
- по окладу сотрудника (по убыванию),
- по фамилии сотрудника (по возрастанию)),
- по идентификатору сотрудника (по возрастанию).
Вывод команды SELECT должен содержать столбцы:
1. Сквозной порядковый номер сотрудника в выборке.
2. Порядковый номер сотрудника внутри подвыборки по подразделению компании.
3. Идентификатор подразделения компании, к которому приписан данный сотрудник.
4. Идентификатор должности сотрудника.
5. Фамилия сотрудника.
6. Оклад, установленный сотруднику.
7. Ранг оклада сотрудника в подразделении компании, где он работает (Самый большой оклад имеет ранг=1, следующий – ранг=2 и т.д.)
Пример результирующей выборки:
| EMP_NUM | EMP_NUM_IN_DEPT | DEPTNO | JOB | ENAME | SAL | DEPT_SAL_RANK |
| PRESIDENT | KING | |||||
| MANAGER | CLARK | |||||
| CLERK | MILLER | |||||
| MANAGER | BLAKE | |||||
| SALESMAN | ALLEN | |||||
| SALESMAN | TURNER | |||||
| SALESMAN | MARTIN | |||||
| SALESMAN | WARD | |||||
| CLERK | JAMES |
select rownum "ЕМР_NUM", ЕМР_NUM_IN_DEPT,
case when ЕМР_NUM_IN_DEPT =1 then department_id
else null
end DEPTNO, job_id, last_name, salary, DEPT_SAL_RANK
from (select row_number() over(partition by department_id order by salary desc) "ЕМР_NUM_IN_DEPT",
department_id,job_id, last_name, salary,
dense_rank() over (partition by department_id order by salary desc) "DEPT_SAL_RANK"
from employees
where department_id = any (10,30,50,90)) t

заменяем все номера отделов у сотрудников на пусто, кроме первого сотрудника, чтобы выводить номер отдела только в строке, относящейся к первому сотруднику
case when ЕМР_NUM_IN_DEPT =1 then department_id
else null
Нумерация сотрудников по отделам
from (select row_number() over(partition by department_id order by salary desc) "ЕМР_NUM_IN_DEPT",
department_id,job_id, last_name, salary,
Нумерация сотрудников по зарплатам в отделах
dense_rank() over (partition by department_id order by salary desc) "DEPT_SAL_RANK"
from employees
Отбираем сотрудников из нужных нам отделов
where department_id in ('10', '30', '50', '90'));
16. Используются таблицы стандартной схемы HR.
Одной командой SELECT вывести список сотрудников компании, руководящих (прямо или опосредованно) одним единственным подчинённым.
В выводимом списке должны быть следующие столбцы:
1. Фамилия сотрудника-руководителя,
2. Должность сотрудника-руководителя,
3. Название подразделения компании, в котором работает сотрудник-руководитель,
4. Фамилия единственного сотрудника-подчиненного,
5. Должность единственного сотрудника-подчиненного.
Результат необходимо отсортировать:
1. По окладу сотрудника-руководителя (по возрастанию)
2. По идентификатору сотрудника-руководителя (по возрастанию)
select m.last_name as "Руководитель", jobs.job_title as "Должность руководителя",
n.department_name as "Название компании руководителя", e.last_name as "Подчиненный", p.job_title as "Должность подчиненного"
from employees a
join employees m on (a.manager_id = m.employee_id)
join jobs on (m.job_id = jobs.job_id)
join departments n on (m.department_id = n.department_id)
join employees e on (m.employee_id = e.manager_id)
join jobs p on (e.job_id = p.job_id)
group by m.last_name,jobs.job_title,n.department_name,e.last_name,p.job_title,m.employee_id,m.salary
having (count(a.manager_id)) = 1
order by m.salary,m.employee_id;

Комментарий:
За счет объединения таблиц employees, jobs, departments получаем должность и название руководителя, затем соединяем итоговую таблицу снова с таблицей employees и получаем фамилию подчиненного, объединяем с jobs и получаем должность подчиненного
having (count(a.manager_id)) = 1 дает нам возможность отсортировать руководителей с одним подчиненным
17. Используются таблицы стандартной схемы HR.
Одной командой SELECT выведите названия стран и средний оклад (с округлением до целого значения) сотрудников, работающих в этих странах, отсортировав результат в порядке убывания среднего оклада и возрастания названия страны.
Примечания:
- сведения для сотрудников, работающих неизвестно в какой стране, в расчет принимать не следует,
- в выборке не должно быть стран, в которых не работает ни один сотрудник.
select country_name, sal from
(select c.country_name country_name,round(avg(e.salary)) sal
from employees e left join departments d
on e.department_id = d.department_id left join
locations l on d.location_id = l.location_id left join
countries c on l.country_id = c.country_id
where c.country_name is not null
group by c.country_name)
order by sal desc
COUNTRY_NAME SAL
---------------------------------------- ----------
Germany 10000
Canada 9500
United Kingdom 8886
United States of America 5065
Комментарий:
Соединяем таблицы employees, departments, locations и countries, выбирая оттуда название страны и среднюю зарплату сотрудников, с помощью условия where исключаем сотрудников, работающих неизвестно в какой стране
18. Используются таблицы стандартной схемы HR.
Одной командой SELECT вывести список сотрудников компании, имеющих коллег с таким же идентификатором должности и окладом.
Если данный идентификатор должности и размер оклада имеет один единственный сотрудник, то сведения о нём в результат попадать не должны.
В результат вывести:
1. Идентификатор должности
2. Размер оклада
3. Список фамилий сотрудников, имеющих данный идентификатор должности и данный оклад.
Фамилии в списке должны быть:
a. Упорядочены по алфавиту (по возрастанию)
b. Разделены символами ', ' ("запятая" и "пробел")
c. Перед первой фамилией не должно быть символов-разделителей
d. После последней фамилии символов-разделителей быть не должно
Результат упорядочить:
1. По размеру оклада (по убыванию)
2. По идентификатору должности (по возрастанию)
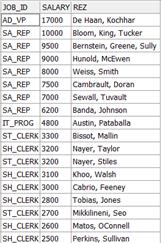
Пример вывода:
| JOB_ID | SALARY | EMP_LIST |
| SA_REP | Banderberg, Maligan | |
| SA_REP | Coreando, McCartney, Silman | |
| FI_ACCOUNT | Cabrioninni, Finley, Santana, Yarsuoto | |
| ... | ||
| ST_CLERK | McLaughlin, Philling |
with tab as (select distinct e1.job_id job_id,e1.salary salary,e2.last_name last_name
from employees e1 inner join employees e2
on e1.department_id = e2.department_id
where e1.job_id = e2.job_id and e1.salary = e2.salary)
select job_id, salary, rez from
(select job_id, salary, trim(max(ltrim(sys_connect_by_path(last_name,', '),', '))) rez from
(select job_id,salary,last_name, row_number() over (partition by job_id,salary order by last_name) rn
from tab)
start with rn = 1
connect by prior rn = rn-1 and prior salary = salary
group by job_id,salary)
where regexp_count(rez,', ',1) > 0
order by salary desc,job_id
Комментарий:
Сначала выводим всех сотрудников компании, имеющих коллег с таким же идентификатором должности и окладом, после чего группируем их по равенству отделов и окладов (partition by job_id,salary order by last_name)
Выводим список сотрудников в отдельной колонке через запятую с помощью sys_connect_by_path
19. Создать запрос для проверки сложности пароль. Сложным считается пароль, содержащий более 10 символов. Обязательно наличие букв в разных регистрах, цифр и спецсимволов. Пароль не должен содержать трех последовательных цифр (т.е. пароль не должен содержать цифр 1,2,3 или 5,6,7 и т.д.). Пример пароля, не удовлетворяющего условию сложности: tT21#1yhj7ii3.
with tab as
(select '&password' str from dual)
select str, case when length(str) >=10 and regexp_count(str,'[[:digit:]]') >0 and
regexp_count(str,'[[:lower:]]') >0 and regexp_count(str,'[[:upper:]]') >0 and
regexp_count(str,'[[:punct:]]') >0 and
length(regexp_substr(str,'[0123456789]+',1,1)) <=1 then 'GOOD' else 'BAD' end rez from tab;
Undefine password
STR REZ
------------ ----
Дата добавления: 2015-08-18; просмотров: 145 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Main_Table PK User_Constraints 19 страница | | | Main_Table PK User_Constraints 21 страница |