|
Читайте также: |
SELECT department_name,last_name,round(sum(sal)*100,2) sal
FROM
(SELECT department_name,last_name,ratio_to_report(salary) over () sal
FROM employees join departments using(department_id)
)
GROUP BY GROUPING SETS ((department_name,last_name),(department_name))
ORDER BY department_name, grouping_id(last_name) desc, last_name
Результат:

Комментарий:
Для вычисления доли зарплаты сотрудников в общем фонде зарплаты использовалась аналитическая функция ratio_to_report(), результат умножался на 100, для вывода результата в процентах, при этом записи группируются в наборы ((department_name,last_name),(department_name)) для расчета доли зарплаты одного сотрудника к общему фонду зарплат и доли подразделения.
13. Одной командой SELECT вывести наиболее часто встречающиеся имена сотрудников. Если несколько имен встречаются чаще всего, то вывести все эти имена.
SELECT first_name
FROM (SELECT first_name, COUNT(first_name) AS k
FROM employees
GROUP BY first_name)
WHERE k=(SELECT k
FROM(SELECT first_name, COUNT(first_name) AS k
FROM employees
GROUP BY first_name
ORDER BY k desc)
WHERE rownum=1)
Результат:
FIRST_NAME
--------------------
Peter
John
David
3 rows selected
Комментарий:
Сотрудники группируются по имени, вычисляется количество человек с одинаковыми именами, после чего строки сортируются по количеству человек в группе по убыванию. Количество человек в первой строке- -максимальное количество человек с одинаковым именем. После чего выбираются те строки, в которых количество имен равно максимальному.
14. Одной командой SELECT вывести всех сотрудников, которые приняты на работу раньше руководителя подразделения компании, к которому они приписаны в данный момент. В результате вывести следующие данные:
1. Название подразделения компании
2. Имя сотрудника
3. Фамилия сотрудника
4. На сколько суток раньше руководителя подразделения данный сотрудник был принят на работу
SELECT department_name, e1.first_name, e1.last_name, e2.hire_date-e1.hire_date AS difference
FROM departments JOIN employees e1 ON (departments.department_id=e1.department_id) INNER JOIN employees e2 On (e1.manager_id=e2.employee_id and e1.department_id=e2.department_id and e1.hire_date<e2.hire_date)
В этом запросе таблица employees соединяется сама с собой по равенству идентификатора сотрудника и идентификатора менеджера сотрудника, причем также должны быть равны идентификаторы подразделений, в которых они работают, и дата принятия сотрудника на работу должна быть меньше даты принятия на работу его менеджера.
Результат:

15. Создать запрос для определения всех ветвей от начальных вершин до всех конечных вершин по направленному дереву. В пределах одной ветви необходимо перемножить поле Количество и просуммировать результат по веткам от одной начальной вершины до одной конечной вершины. Пример исходной таблицы:
| Номер дочерней вершины | Номер родительской вершины | Количество |
Результат:
| Начальная вершина | Конечная вершина | Количество ветвей | Сумма произведентй |
INSERT INTO tree values (2,1,2);
INSERT INTO tree values (5,1,2);
INSERT INTO tree values (3,2,1);
INSERT INTO tree values (4,2,2);
INSERT INTO tree values (4,6,2);
INSERT INTO tree values (6,5,3);
INSERT INTO tree values (4,3,2);
WITH ch AS (SELECT child_number
FROM tree
MINUS
SELECT parent_number
FROM tree),
p as (SELECT distinct parent_number FROM tree
MINUS
SELECT distinct child_number FROM tree),
max_level as
(SELECT max(LEVEL)
FROM tree
WHERE child_number IN (SELECT * FROM ch)
START WITH parent_number IN (SELECT * FROM p)
CONNECT BY parent_number= PRIOR child_number)
SELECT T.start_node "Начальная_вершина", T.child_number "Конечная вершина", COUNT(*)
Количество ветвей", k.kol "Сумма произведений"
FROM(SELECT CONNECT_BY_ROOT (parent_number) AS start_node, child_number
FROM tree
WHERE child_number IN (SELECT * FROM ch)
START WITH parent_number IN (SELECT * FROM p)
CONNECT BY parent_number= PRIOR child_number) T
JOIN (SELECT par, fin, SUM(kol) kol
FROM (SELECT k.par par, k.l,k.finish_node fin, temp, round(exp(sum(ln(LTRIM(regexp_substr(K.KOL,',[0-9]+',1,t.n), ','))))) kol
FROM (SELECT LEVEL l, CONNECT_BY_ROOT(parent_number) par, sys_connect_by_path(child_number,'--> ') temp, REGEXP_SUBSTR(sys_connect_by_path(child_number,'--> '),'[^(-->)]*$') finish_node, sys_connect_by_path(KOLVO,',') KOL
FROM tree
WHERE child_number IN (SELECT * FROM ch)
START WITH parent_number IN (SELECT * FROM p)
CONNECT BY parent_number= PRIOR child_number
ORDER BY 2,1) k,(SELECT level n FROM dual
CONNECT BY level <= (SELECT * FROM max_level)) t
WHERE t.n<=k.l
GROUP BY k.par, k.l, k.finish_node, temp)
GROUP BY par, fin) k
ON k.par=t.start_node AND k.fin=t.child_number
GROUP BY T.start_node, T.child_number, k.kol;
Результат:
Начальная_вершина Конечная вершина Количество ветвей Сумма произведений
------------------------------- ------------------------- ---------------------- ----------------------
1 4 3 20
Комментарий:
Ch – вершины, не являющиеся родительскими
P – вершины, не являющиеся потомками
Max_level- количество уровней дерева
Первоначально определяются все возможные ветви дерева от начальных вершин до конечных.
Для одинаковых начала и конца считается количество ветвей. Для каждой ветви строится последовательность весов, разделенных запятыми. Вспомогательный столбец temp показывает путь от начальной вершины к конечной для каждой ветви. По этому параметру группируются записи для вычисления произведения весов на каждой ветви, после чего эти произведения суммируются для каждой пары (начальная вершина, конечная вершина). Произведение вершин ищется по формуле: exp(sum(ln(x)). Для вычленения весов из последовательности используется регулярное выражение LTRIM(regexp_substr(K.KOL,',[0-9]+',1,t.n), ',').
16. Создать запрос для замены в символьном выражении запятых, стоящих в самых глубоких двойных кавычках, на дефисы. Вложенные двойные кавычки выделяются нечетным количеством слэшей. Например, из исходного символьного выражения:
Раз 2 Три “ 5678 /“hhhh /“273,34,567///” двести семьдесят три/” 234 “
должно быть получено:
Раз 2 Три “ 5678 “hhhh “273-34-567 двести семьдесят три” 234 “
SELECT regexp_replace((substr(str,1,regexp_instr(str, '"[^"]*//')-1)||regexp_replace(regexp_substr(str, '"[^"]*//'), ',','-')||
substr(str,regexp_instr(str, '"[^"]*//')+length(regexp_substr(str, '"[^"]*//')), length(str))),'/','') as new_str
FROM (SELECT '" 5678 /"hhhh /"273,34,567///" двести семьдесят три/" 234 "' str
FROM dual)
Результат:
NEW_STR
-----------------------------------------------------
" 5678 "hhhh "273-34-567" двести семьдесят три" 234 "
Комментарий:
Первоначально вычисляется местоположение открывающихся внутренних кавычек, после чего строка делится на три части: до этих кавычек, выражение в кавычках и после закрывающейся кавычки. В выражении, стоящем во внутренних кавычках запятые меняются на ‘ -’, после чего строка вновь собирается вместе, и из нее удаляются слэши.
17. Создать запрос для вывода информации о студентах, у которых интервал между датами сдачи экзаменов составляет менее трех дней. Информацию вывести в виде:
| Фамилия | Дисциплина 1 | Дата сдачи1 | Дисциплина 2 | Дата сдачи 2 |
SELECT фамилия, disc1 as "Дисциплина1",d2 as "Дата сдачи1",название as "Дисциплина2",d1 as "Дата сдачи1"
FROM (
SELECT фамилия,дата d1,название,lag(дата,1,null)over(partition by номер_студента order by дата) as d2,lag(название,1,null)over(partition by номер_студента order by номер_дисциплины) as disc1
FROM успеваемость join студенты using(номер_студента) join дисциплины using(номер_дисциплины)
ORDER BY номер_студента,дата)
WHERE (d2 is not null) and d1-d2<3
Результат:

Комментарий:
Для того, чтобы в одной таблице размещались все необходимые столбцы были соединены таблицы: Успеваемость, Студенты и Дисциплины.
При решении задачи я использовала аналитическую функцию lag() для того чтобы сместить значение в столбцах ДАТА и ДИСЦИПЛИНА на 1 строку вниз, при этом группируя записи по номеру студента. В результате, у студентов, сдававших 2 и более экзаменов все столбцы оказались заполненными, а у остальных – нет. После чего была произведена выборка записей, где значение Дата сдачи2-d2 Дата сдачи1<3, т.е. между экзаменами прошло менее 3 дней.
18. Для каждого отдела из таблицы Departments отобразить в виде одной строки с запятой в качестве разделителя фамилии сотрудников, работающих в нем. Фамилии сотрудников должны быть отсортированы по алфавиту.
SELECT department_id, max(ltrim(sys_connect_by_path(last_name, ', '), ', ')) employees
FROM (SELECT department_id, last_name,
row_number () over (partition by department_id order by last_name) rown
FROM employees)
WHERE department_id is not null
START WITH rown=1
CONNECT BY PRIOR rown = rown-1 and PRIOR department_id = department_id
GROUP BY department_id
Результат:
DEPARTMENT_ID EMPLOYEES
---------------------- ----------------------------------------------------------------------------------------------------------------
10 Whalen
20 Fay, Hartstein
30 Baida, Colmenares, Himuro, Khoo, Raphaely, Tobias
40 Mavris
50 Atkinson, Bell, Bissot, Bull, Cabrio, Chung, Davies, Dellinger, Dilly, Everett, Feeney, Fleaur,
Fripp, Gates, Gee, Geoni, Grant, Jones, Kaufling, Ladwig, Landry, Mallin, Markle, Marlow,
Matos, McCain, Mikkilineni, Mourgos, Nayer, OConnell, Olson, Patel, Perkins, Philtanker,
Rajs, Rogers, Sarchand, Seo, Stiles, Sullivan, Taylor, Vargas, Vollman, Walsh, Weiss
60 Austin, Ernst, Hunold, Lorentz, Pataballa
70 Baer
80 Abel, Ande, Banda, Bates, Bernstein, Bloom, Cambrault, Cambrault, Doran, Errazuriz, Fox,
Greene, Hall, Hutton, Johnson, King, Kumar, Lee, Livingston, Marvins, McEwen, Olsen, Ozer,
Partners, Russell, Sewall, Smith, Smith, Sully, Taylor, Tucker, Tuvault, Vishney, Zlotkey
90 De Haan, King, Kochhar
100 Chen, Faviet, Greenberg, Popp, Sciarra, Urman
110 Gietz, Higgins
11 rows selected
Комментарий:
При помощи функции sys_connect_by_path строится дерево зависимостей служащих по каждому подразделению, при этом фамилии служащих сортируются по возрастанию, а затем, выбираются максимальные деревья по каждому подразделению – они то и будут содержать в себе список всех служащих в подразделении.
19. Для двух заданных сотрудников найти их ближайшего общего начальника.
SELECT distinct last_value(last_name) over() as last_name
FROM
(
SELECT last_name
FROM employees
WHERE last_name!='&&Name1'
START WITH last_name='&&Name1'
CONNECT BY PRIOR manager_id=employee_id
INTERSECT
(
SELECT last_name
FROM employees
WHERE last_name!='&&Name2'
START WITH last_name='&&Name2'
CONNECT BY PRIOR manager_id=employee_id
))
Результат:
Name1=Davies
Name2=Matos
LAST_NAME
---------------------
Mourgos
Комментарий:
В задаче используются 2 переменные подстановки: Name1 (фамилия первого сотрудника) и Name2 (фамилия второго сотрудника). Для каждого из них выводится иерархия менеджеров, которым подчиняется этот сотрудник. После чего при помощи оператора INTERSECT для них выбираются общие. Последним в списке будет ближайший общий начальник для этих сотрудников. Его находим при помощи аналитической функции Last_Value().
20. Создать запрос для получения информации о группах:
| Группа | Кол-во студентов | Название Специальности | Кол-во круглых отличников | Кол-во должников |
| …… |
SELECT номер_группы,название_специальности,nvl(kol_otl,0) as kol_otl, nvl(kol_dolg,0) as kol_dolg
FROM
((SELECT номер_группы,название_специальности
FROM группы join специальности using(код_специальности)) left join
(SELECT *
FROM
(SELECT distinct номер_группы,count(номер_студента) over(partition by номер_группы,оценка) as kol_otl
FROM(
SELECT номер_группы,название_специальности,номер_студента,оценка,count(номер_студента) over(partition by номер_группы) as kolvo,avg(оценка) over(partition by номер_студента) as otl
FROM(
SELECT номер_группы,название_специальности, номер_студента,оценка
FROM СТУДЕНТЫ join ГРУППЫ using(номер_группы)join специальности using(код_специальности) join УСПЕВАЕМОСТЬ using (номер_студента)))
WHERE otl=5)t1 full join
(SELECT distinct номер_группы, count(номер_студента) over(partition by номер_группы,оценка) AS kol_dolg
FROM (
SELECT номер_группы,count(номер_студента) over(partition by номер_группы) as kolvo, название_специальности,номер_студента,оценка,avg(оценка) over(partition by номер_студента) as otl
FROM(
SELECT номер_группы,название_специальности, номер_студента,оценка
FROM студенты join ГРУППЫ using(номер_группы)join специальности using(код_специальности) join УСПЕВАЕМОСТЬ using (номер_студента)))
WHERE оценка=2) t2 using(номер_группы)) using(номер_группы))
Результат:
НОМЕР_ГРУППЫ НАЗВАНИЕ_СПЕЦИАЛЬНОСТИ KOL_OTL KOL_DOLG
--------------- --------------------------------------------------------------- ---------------------- ----------------------
122 СИСТЕМЫ АВТОМАТИЧЕСКОГО УПРАВЛЕНИЯ 1 0
121 СИСТЕМЫ АВТОМАТИЧЕСКОГО УПРАВЛЕНИЯ 2 1
123 ЭКОНОМИКА ПРЕДПРИЯТИЙ 0 1
124 ЭКОНОМИКА ПРЕДПРИЯТИЙ 0 0
Комментарий:
Отдельно друг от друга из таблицы, полученной при объединении таблиц СТУДЕНТЫ, ГРУППЫ и УСПЕВАЕМОСТЬ, выбираются записи о круглых отличниках (это студенты, средний балл которых равен 5) и о должниках (студенты, оценка которых равна 2). После чего обе таблицы объединяются с таблицей ГРУППЫ, для получения информации об отличниках и должниках во всех группах.
ВАРИАНТ 21
(Базы данных HR и OE)
1. Используя только таблицу DUAL вычислить и вывести в результат все числа Фибоначчи в диапазоне от 1 до 1000 (1 <= n_fib <= 1000). Числа в результате не должны повторяться и должны быть отсортированы по возрастанию.
В результате должен получиться список из 15 чисел, отсортированных по возрастанию:
| N_FIB |
| 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987 |
SELECT ltrim(Max(SYS_CONNECT_BY_PATH(fib, ' ')), ' ') fiblist
FROM (
SELECT n, fib, ROW_NUMBER()
OVER (ORDER BY n) r
FROM (select n, round((power((1+sqrt(5))*0.5, n)-power((1-sqrt(5))*0.5, n))/sqrt(5)) fib
from (select level n
from dual
connect by level <= 16) t1) t2
)
START WITH r=2
CONNECT BY PRIOR r = r-1;
FIBLIST
--------------------------------------------
1 2 3 5 8 13 21 34 55 89 144 233 377 610 987
Комментарий:
С помощью row_number() получаем номер записи
Каждый раз считаем числа Фибоначчи по формуле, используя level.
Connect by - выполняем расчет пока истинно условие
Отобрали максимальную строчку, чтобы вывести 15 чисел
2. Создайте таблицу с именем ROW_DOUBLES, содержащую 5-7 столбцов типов VARCHAR2 / CHAR / DATE / NUMBER, используя команду CREATE TABLE … AS SELECT …;
Например:
CREATE TABLE row_doubles
AS
SELECT col_1, col_2, col_3, …, col_n
FROM so me_table
WHERE <необязательное_условие_отбора_строк>;
Здесь:
· SOME_TABLE – это какая-либо из доступных вам таблиц схемы HR или словаря данных Oracle Database,
· col_1, col_2, col_3, …, col_n – имена столбцов, выбираемых из таблицы SOME_TABLE.
· <необязательное_условие_отбора_строк> - какое-либо условие отбора строк из выбранной вами таблицы SOME_TABLE.
Добавьте в таблицу ROW_DOUBLES некоторое количество строк, которые повторяют уже существующие в ней строки. Например, так:
Одной командой SELECT отберите строки, которые нужно удалить из таблицы ROW_DOUBLES, чтобы в ней осталось точно по одному экземпляру каждой строки. При этом само собой разумеется, что если какая-то строка уникальна (не дублируется), то в выборку она попасть не должна. В каждом столбце таблицы могут быть NULL-значения в произвольном числе строк.
Команда SELECT, которая будет выводить результат, должна содержать в списке выброки * (звездочку), то есть выводить все поля таблицы ROW_DOUBLES в том порядке, как они были заданы при создании этой таблицы.
... -- необязательная часть результирующей команды SELECT
SELECT * FROM row_doubles
... -- обязательная часть результирующей команды SELECT
Внимание!
Количество полей таблицы, их названий и типов неизвестно.
Решение должно быть пригодно к использованию для любой таблицы со столбцами, содержащими данные перечисленных выше типов.
CREATE TABLE row_doubles
AS
SELECT employee_id,first_name,last_name,hire_date, salary,manager_id
FROM employees
WHERE department_id=50;
Insert into row_doubles (employee_id,first_name, last_name, hire_date, salary, manager_id)
Values(120,'Mathew','Weiss', '18.07.1996',8000,100);
Insert into row_doubles (employee_id,first_name, last_name, hire_date, salary, manager_id)
Values(128,'Steven','Markle', '08.03.2000',2200,120);
Insert into row_doubles (employee_id,first_name, last_name, hire_date, salary, manager_id)
Values(140,'Joshua','Patel', '06.04.1998',2500,123);
select *
from row_doubles t1
where exists
(select * from row_doubles t2 where t2.rowid = t1.rowid
intersect
select * from row_doubles t3 where t3.rowid > t1.rowid)

Комментарий:
Создали таблицу, задав имена столбцов, выбираемых из таблицы employees, задав условие отбора строк department_id=50
Вставили еще три дополнительных строчки в таблицу, две из которых были дубликатами уже имеющихся.
Далее отобрали повторяющиеся строки с помощью операции пересечения.
3. Требуется, используя только таблицу DUAL, одной командой SELECT вывести все анаграммы четырехбуквенного слова, отсортированные по возрастанию.
Например, для слова АГАТ должно быть выведено:
АГАТ, ГАТА, АТАГ, ААГТ, ААТГ, ГААТ, ГТАА, ……..
select letters as anagram
from(
select replace(sys_connect_by_path(ch, '\'), '\') as letters, level as lvl
from
(select substr('&&word', rownum, 1) as ch from dual connect by level <= length('&word')
)
connect by
level <= length('&word') and length('&word')=4)
,
(select rownum as i from dual connect by level <= length('&word')
)
where nvl(length(replace(letters, substr('&word', i, 1))), 0) = nvl(length(replace('&word', substr('&word', i, 1))), 0)
and lvl = length('&word')
group by letters
having count(distinct i) = length('&word')
;
undefine word
ANAGRAM
--------
аагт
аатг
агат
агта
атаг
атга
гаат
гата
гтаа
тааг
тага
тгаа
Комментарий:
Вводим с клавиатуры четырехбуквенное слово.
С помощью sys_connect и connect by level производим перестановку букв и вывод всех возможных анаграмм
4. Для снижения конкуренции за ресурсы при изменении данных необходимо строить индексы по столбцам, входящим в ограничение внешнего ключа (Foreign key).
Одной командой SELECT вывести столбцы таблиц схемы данных текущего пользователя, входящие в ограничения внешних ключей, по которым не построены соответствующие индексы. Столбцы в индексе должны быть в тех же позициях, что и во внешнем ключе.
В результат вывести три столбца:
1. Название таблицы.
2. Название ссылочного ограничения целостности (внешнего ключа).
3. Название неиндексированного столбца данного ссылочного ограничения целостности.
Результат отсортировать по столбцам 1, 2 и 3 по возрастанию.
select uc.table_name,uc.constraint_name, ucc.column_name
from user_constraints uc left join user_cons_columns ucc
on uc.constraint_name = ucc.constraint_name
where uc.constraint_type = 'R' and not exists
(select * from user_ind_columns uic
where ucc.column_name = uic.column_name
and ucc.table_name = uic.table_name
and ucc.position = uic.column_position)
order by 1,2,3;
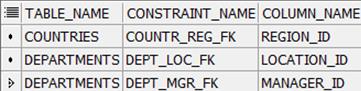
Выводим имя таблицы, и имя колонок для всех ограничений типа внешний ключ
select uc.table_name,uc.constraint_name, ucc.column_name
from user_constraints uc left join user_cons_columns ucc
on uc.constraint_name = ucc.constraint_name
where uc.constraint_type = 'R'
Затем с помощью подзапроса мы выделяем те ограничения, по которым не построены индексы
select * from user_ind_columns uic
where ucc.column_name = uic.column_name
and ucc.table_name = uic.table_name
and ucc.position = uic.column_position
5. Используются таблицы схем HR и OE.
Данные об адресе покупателя хранятся в столбце CUST_ADDRESS таблицы CUSTOMERS.
Атрибут CUST_ADDRESS имеет пользовательский тип данных CUST_ADDRESS_TYP:
Имя поля Описание
-------------- -------------------------------------
STREET_ADDRESS – Название улицы
POSTAL_CODE - Почтовый индекс
CITY - Название города (населенного пункта)
STATE_PROVINCE – Код штата или региона
COUNTRY_ID - Код страны
Одной командой SELECT вывести сведения о покупателях, в адресе которых указано название города, имеющееся в списке городов, где расположены подразделения компании.
В результат вывести четыре столбца:
1. Идентификатор покупателя
2. Пол покупателя
3. Дата рождения покупателя
4. Название города (населенного пункта)
Результат отсортировать по идентификатору покупателя по возрастанию.
select c.customer_id,c.gender,c.date_of_birth
from oe.customers c inner join hr.locations l
on l.city=c.cust_address.city;
CUSTOMER_ID GENDER DATE_OF_BIRTH
----------- ------ -------------
326 F 06.09.59
327 M 15.09.56
328 F 06.10.85
333 M 16.10.53
334 M 15.11.81
344 M 14.03.60
481 F 28.09.67
731 M 02.10.33
757 M 21.12.53
846 F 14.06.62
712 M 05.06.83
713 F 24.06.48
715 F 05.07.51
717 M 25.07.74
719 M 04.08.62
721 M 23.08.44
727 M 02.09.49
729 M 23.09.42
756 M 02.12.86
981 M 07.10.73
Комментарий:
Соединяем таблицу customers с таблицей locations по равенству городов.
Получаем покупателей, которые живут в городах, где расположены подразделения компании.
6. Используются таблицы стандартных схем HR и OE.
Одной командой SELECT вывести сведения о сотрудниках компании, которые являются персональными менеджерами покупателей, с которыми работает компания.
В результат вывести пять столбцов:
1. Идентификатор сотрудника
2. Имя сотрудника
3. Фамилия сотрудника
4. Оклад, установленный сотруднику.
5. Установленный размер комиссионных (в процентах от оклада).
Результат отсортировать по идентификатору сотрудника по возрастанию.
select DISTINCT EMPLOYEES.employee_ID, EMPLOYEES.FIRST_NAME, EMPLOYEES.lAST_NAME, EMPLOYEES.SALARY, EMPLOYEES.COMMISSION_PCT
FROM OE.CUSTOMERS JOIN OE.EMPLOYEES
ON EMPLOYEE_ID=account_mgr_id
ORDER BY EMPLOYEE_ID

Комментарий:
Соединяем таблицу customers с таблицей employees по равенству employee_id=account_manager_id и получаем список персональных менеджеров
7. Используются таблицы стандартной схемы HR.
Месячный доход сотрудника складывается из оклада, установленного сотруднику, и установленного для сотрудника размера комиссионных (в процентах от оклада; например, значению 0,2 соответствует сумма комиссионных, равная 20% от оклада).
Если для сотрудника не указан размер комиссионных, то следует считать, что комиссионные данному сотруднику не выплачиваются.
Одной командой SELECT вывести сведения о месячном доходе сотрудников по странам.
В результат вывести два столбца:
1. Название страны, в которой расположено подразделение компании, к которому приписан сотрудник
2. Сумма месячных доходов сотрудников, приписанных к подразделениям компании, расположенных в данной стране.
Результат упорядочить по названиям стран по возрастанию.
В предпоследней строке вывести сумму месячных доходов сотрудников, для которых невозможно определить страну. Вместо названия страны в этой строке вывести строку 'N/A' (в верхнем регистре).
Дата добавления: 2015-08-18; просмотров: 277 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Main_Table PK User_Constraints 18 страница | | | Main_Table PK User_Constraints 20 страница |