|
Читайте также: |
WITH tab_s
AS (SELECT str, ROWNUM rn
FROM (SELECT DISTINCT str
FROM (SELECT '&str' str
FROM dual)
MODEL
DIMENSION BY (0 d)
MEASURES (str)
RULES ITERATE (1000) UNTIL (ITERATION_NUMBER = LENGTH(str[0])) (str[ITERATION_NUMBER + 1] = REPLACE(str[ITERATION_NUMBER], ' ', ' '))))
SELECT str
FROM tab_s
WHERE rn = (SELECT MAX(rn)
FROM tab_s);
Ввел: сине бело голубые
Получил:
STR
--------------------------------------------
сине бело голубые
17. Показать в одном отчете для каждого отдела: его номер, наименование, количество работающих сотрудников, средний оклад вместе со следующими данными по каждому сотруднику – фамилия, оклад и должность.
| Номер отдела | Название отдела | Количество сотрудников | Средний оклад | Фамилия | Оклад | Должность |
| Purchasing | ||||||
| Khoo | Purchasing Clerk | |||||
| Baida | Purchasing Clerk | |||||
| Tobias | Purchasing Clerk | |||||
| Himuro | Purchasing Clerk | |||||
| Colmenares | Purchasing Clerk | |||||
| Human Resources | ||||||
| Mavris | Human Resources Representative | |||||
| Shipping | 3475,56 | |||||
| Weiss | Stock Manager | |||||
| Fripp | Stock Manager | |||||
| Kaufling | Stock Manager | |||||
| … | …… | …… | ……. |
SELECT
DECODE(ddept_id, NULL, ' ', ddept_id) AS "Номер отдела",
DECODE(dept_name, NULL, ' ', dept_name) AS "Название отдела",
DECODE(col, NULL, ' ', col) AS "Количество сотрудников",
DECODE(ROUND(avgsal,2), NULL, ' ', ROUND(avgsal,2)) AS "Средний оклад",
DECODE(last_name, NULL, ' ', last_name) AS "Фамилия",
DECODE(salary, NULL, ' ', salary) AS "Оклад",
DECODE(jt, NULL, ' ', jt) AS "Должность"
FROM (SELECT ddept_id, dept_name, col, avgsal, last_name, salary, jt, edept_id
FROM (SELECT d.department_id AS ddept_id, d.department_name AS dept_name, COUNT(e.employee_id) OVER (PARTITION BY d.department_id) AS col,
AVG(e.salary) OVER (PARTITION BY d.department_id) AS avgsal, e.last_name AS last_name, e.department_id AS edept_id, e.salary AS salary, j.job_title AS jt
FROM employees e JOIN departments d ON e.department_id = d.department_id
JOIN jobs j ON e.job_id = j.job_id)
GROUP BY GROUPING SETS ((ddept_id, dept_name, col, avgsal),(last_name, salary, jt, edept_id))
ORDER BY ddept_id, edept_id)
ORDER BY
(CASE WHEN ddept_id IS NOT NULL
THEN ddept_id
ELSE edept_id END), ddept_id;

18. В произвольной строке, состоящей из символьных элементов, разделенных запятыми, отсортировать элементы по алфавиту. Например, символьную строку
abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe
преобразовать к виду:
abc,cde,df,ef,ewe, fw,gh,mn,ss,test,wwe.
SELECT MAX(LTRIM(SYS_CONNECT_BY_PATH(str, ','),',')) AS "Res"
FROM (SELECT str, ROW_NUMBER() OVER (ORDER BY str) rn
FROM (SELECT regexp_substr('abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe','[a-z]+',1,level) str
FROM dual
CONNECT BY regexp_substr('abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe','[a-z]+',1,level) IS NOT NULL
ORDER BY 1))
START WITH rn = 1
CONNECT BY PRIOR rn = rn-1;
Res
---------------------------------------------
abc,cde,df,ef,ewe,fw,gh,mn,ss,test,wwe
19. Выделить в HTML разметке содержимое блоков с установленными атрибутами:
· тег <p> с CSS классом content
· тег <li> с CSS классом content
Например, для разметки:
<p>Абзац 1</p>
<p class="content">Абзац 2</p>
<ul>
<li>Элемент 1</li>
<li class="content">Элемент 2</li>
</ul>
Должно быть выделено:
<p class="content">Абзац 2</p>
<li class="content">Элемент 2</li>
WITH tab_tag
AS (SELECT '<p>Абзац 1</p>
<p class="content">Абзац 2</p>
<ul>
<li>Элемент 1</li>
<li class="content">Элемент 2</li>
</ul>
' tag
FROM dual)
SELECT LTRIM(subtag) AS "Результат"
FROM (SELECT regexp_substr(tag, '.*<p class="content">.*', 1, level) AS subtag
FROM tab_tag
CONNECT BY regexp_substr(tag, '.*<p class="content">.*', 1, level) IS NOT NULL
UNION ALL
SELECT regexp_substr(tag, '.*<li class="content">.*', 1, level) AS subtag
FROM tab_tag
CONNECT BY regexp_substr(tag, '.*<li class="content">.*', 1, level) IS NOT NULL);
Результат
------------------------------------------------
<p class="content">Абзац 2</p>
<li class="content">Элемент 2</li>
20. Создать запрос для получения списка городов и отделов, расположенных в них. Результаты представить в виде:
| Город | Отдел |
| Seattle | Accounting, Administration,Benefits, Construction,Control And Credit |
| Toronto | Marketing |
Список отделов в каждом городе должен быть отсортирован по алфавиту.
WITH tab
AS (SELECT d.location_id, l.city,d.department_name,
ROW_NUMBER () OVER (PARTITION BY l.city ORDER BY d.department_name) rn
FROM departments d INNER JOIN locations l
ON d.location_id=l.location_id
ORDER BY 2,3)
SELECT city город, MAX(LTRIM(sys_connect_by_path(department_name, ', '), ', ')) AS Dept
FROM tab
START WITH rn-1=0
CONNECT BY PRIOR rn = rn-1 AND PRIOR location_id = location_id
GROUP BY city;
Результат:
London Human Resources
Seattle Accounting,Administration,Benefits,Construction,Contracting,Corporate Tax,Executive,Finance,Government Sales,IT Helpdesk,IT Support,Manufacturing,NOC,Operations,Payroll,Purchasing,Recruiting, Retail Sales,Shareholder Services,Treasury,1 Control And Credit
Munich Public Relations
South San Francisco Shipping
Toronto Marketing
Southlake IT
Oxford Sales
ВАРИАНТ 19
(Базы данных Студент и Human Resources)
1. Билеты для проезда в городском транспорте имеет шестизначный десятичный номер и буквенно-цифровую серию. Нумерация каждой серии билетов начинается с 000001.
Существует примета, что билет, у которого сумма трех первых цифр равна сумме трёх последних цифр - это "Счастливый билет".
Одной командой SELECT вывести количество "счастливых билетов" в каждой серии (одно число).
SELECT count(l) lucky_tickets
FROM(
SELECT CASE
WHEN substr(lpad(level,6,'0'),1,1)+substr(lpad(level,6,'0'),2,1)+substr(lpad(level,6,'0'),3,1)= substr(lpad(level,6,'0'),4,1)+substr(lpad(level,6,'0'),5,1)+substr(lpad(level,6,'0'),6,1)
THEN level
END as l
FROM dual
CONNECT BY level<=999999)
Результат:
LUCKY_TICKETS
----------------------
Комментарий:
Запрос перебирает все числа от одного до 999999, при этом считая количество таких, в которых сумма первых 3-х цифр равна сумме последних 3-х.
2. Имеется таблица TRIP, в которой хранятся данные о рейсах, выполняемых транспортом компании.
CREATE TABLE trip(
id NUMBER
, per_beg DATE NOT NULL
, per_end DATE NOT NULL
, CONSTRAINT trip PRIMARY KEY(id)
, CONSTRAINT trip#C#per_beg#per_end CHECK(per_end >= per_beg)
, CONSTRAINT trip#C#per_beg CHECK(per_beg = TRUNC(per_beg))
, CONSTRAINT trip#C#per_end CHECK(per_end = TRUNC(per_end)));
ID - идентификатор рейса,
PER_BEG - дата начала рейса,
PER_END - дата окончания рейса.
Все даты хранятся с точностью до суток (время не хранится).
В некоторые периоды времени выполняется один или несколько рейсов, в другие периоды времени компания никаких рейсов не выполняет.
Два рейса называются смежными по времени, когда второй рейс начинается на следующий день после окончания первого рейса.
Два рейса называются пересекающимися по времени, когда есть дни, в которые одновременно выполнялся и первый и второй рейс.
Одной командой SELECT вывести сведения обо всех периодах, когда компания выполняла какие-либо рейсы, то есть смежные и/или пересекающиеся по времени рейсы должны быть объединены в один период.
Каждый период должен встречаться в результате только один раз.
В результат должны быть выведены:
1. Дата начала периода,
2. Дата окончания периода.
Результаты отсортировать по дате начала периода по возрастанию.
INSERT ALL
INTO trip values(1,'1.05.2012','2.05.2012')
INTO trip values(2,'3.05.2012','3.05.2012')
INTO trip values(3,'5.05.2012','6.05.2012')
INTO trip values(4,'6.05.2012','7.05.2012')
INTO trip values(5,'7.05.2012','7.05.2012')
INTO trip values(6,'7.05.2012','7.05.2012')
INTO trip values(7,'7.05.2012','8.05.2012')
SELECT * FROM dual;

SELECT per_beg, max(per_end) per_end
FROM (
SELECT connect_by_root(per_beg) per_beg, per_end
FROM trip
WHERE connect_by_isleaf=1
START WITH per_beg in
(SELECT t1.per_beg
FROM trip t1
WHERE not exists (
SELECT *
FROM trip
WHERE (t1.per_beg-1) between per_beg and per_end
)
)
CONNECT by nocycle(prior per_end between (per_beg-1) and per_end)
)
GROUP BY per_beg
ORDER BY per_beg
Результат:
PER_BEG PER_END
------------------------- -------------------------
01.05.12 03.05.12
05.05.12 08.05.12
Комментарий:
Первоначально выбираются даты начала рейса, которые не являются датами окончания других рейсов. После чего, начиная с этих дат, при помощи иерархического подзапроса выбираются даты окончания рейсов, которые не являются датами начала других рейсов. При группировке записей по датам начала рейсов, выбирается максимальная дата окончания, для выбора максимального по длине периода когда компания выполняла рейсы.
3. Одной командой SELECT вывести список сотруднике компании, имеющих наименьшие оклад среди сотрудников подразделения, в котором они работают.
Сведения о сотрудниках, для которых неизвестно подразделение компании, к которому они приписаны выводить не нужно.
В результат вывести:
a. Идентификатор подразделения компании, к которому приписан сотрудник.
b. Фамилию сотрудника.
c. Оклад, установленный сотруднику.
В команде SELECT запрещается использовать:
· Фразы WITH, GROUP BY,HAVING, ORDER BY, CONNECT BY, START WITH,
· Условия IN, =ANY, =SOME, NOT IN, <> ALL, EXISTS, NOT EXISTS,
· Подзапросы (subqueries), в том числе подзапросы во фразе FROM,
· Иерархические запросы (hierarchical queries),
· Скалярное выражение подзапроса (scalar subquery expression),
· Агрегатные функции (aggregate functions) – MIN,MAX, SUM,COUNT, AVG и др.
· Аналитические функции (analytic functions)
SELECT emp2.DEPARTMENT_ID, emp2.LAST_NAME, emp2.SALARY
FROM EMPLOYEES emp0 JOIN EMPLOYEES emp1 on (emp0.DEPARTMENT_ID=emp1.DEPARTMENT_ID AND emp0.SALARY>emp1.SALARY)
RIGHT JOIN EMPLOYEES emp2 on (emp0.EMPLOYEE_ID=emp2.EMPLOYEE_ID)
WHERE emp0.SALARY is null and DEPARTMENT_ID is not null
Результат:
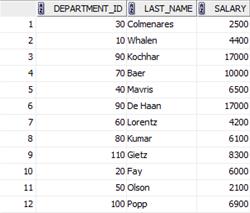
Комментарий:
Первоначально соединяем таблицу EMPLOYEES саму с собой по номеру подразделения, причем условие emp0.SALARY>emp1.SALARY позволяет отсеять служащих с минимальными зарплатами. После этого снова соединяем полученную таблицу с таблицей EMPLOYEES по идентификатору служащего, записи выбираются по условию emp0.SALARY is null, т.е. служащие с минимальными размерами окладов.
4. Из произвольной символьной строки удалить лишние пробелы между словами, оставив только по одному. Задачу решить при помощи раздела Model без использования регулярных выражений.
WITH t as
(SELECT str, rownum rn
FROM(SELECT distinct str
FROM(SELECT 'a aa ssss qqq a a' str FROM dual)
MODEL
dimension by (0 d)
measures (str)
rules iterate (500) until (iteration_number=length(str[0]))
(str[iteration_number+1] = replace(str[iteration_number], ' ', ' '))))
SELECT str as “RESULT”
FROM t
WHERE rn = (SELECT max(rn) FROM t);
Результат:
RESULT
----------------
a aa ssss qqq a a
Комментарий:
При помощи раздела MODEL проходим по всем символам строки, при этом последовательно заменяя два пробела на один. После чего из всех полученных строк выбирается строка с наибольшим номером, это и будет строка, в которой остались только единичные пробелы.
5. Одной командой SELECT вывести таблицу сведений о сотрудниках, которая содержит следующие столбцы:
1. Идентификатор сотрудника
2. Идентификатор подразделения компании, к которому приписан сотрудник
3. Имя сотрудника
4. Фамилия сотрудника
5. Дата приема на работу
6. Оклад
7. Сумма окладов по подразделению компании "нарастающим итогом", то есть сумма значений в столбце оклад в текущей строке и во всех предыдущих, которые соответствуют тому же подразделению.
8. Сумма окладов "нарастающим итогом", то есть сумма значений в столбце оклад в текущей строке и во всех предыдущих.
Результат отсортировать:
1. По идентификатору подразделения, к которому приписан сотрудник по возрастанию.
2. По дате приема на работу по возрастанию.
3. По идентификатору сотрудника по возрастанию.
SELECT employee_id,department_id,first_name, last_name,hire_date,salary, sum(salary)
over (PARTITION by department_id ORDER BY DEPARTMENT_ID,hire_date,employee_id
ROWS BETWEEN UNBOUNDED preceding AND CURRENT ROW) AS SUMM_DEPT,
sum(salary)
over (ORDER BY DEPARTMENT_ID,hire_date,employee_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS SUMM
FROM employees
ORDER BY DEPARTMENT_ID,hire_date,employee_id
Результат:

Комментарий:
Для решения задачи мною была использована аналитическая функция sum(). Для расчета суммы нарастающим итогом была задана конструкция окна: ROWS BETWEEN UNBOUNDED preceding AND CURRENT ROW.
Для расчета суммы нарастающим итогом по подразделениям записи группировались по department_id: PARTITION by department_id, конструкция окна аналогично была задана первой строкой таблицы и текущей строкой таблицы.
6. Одной командой SELECT вывести список сотрудников, включающий следующие данные:
1. Идентификатор сотрудника
2. Год, когда сотрудник был принят на работу
3. Имя сотрудника
4. Фамилия сотрудника
5. Оклад
6. "Место" сотрудника в группе принятых на работу в одном и том же году, упорядоченных по убыванию зарплаты, а в случае равенства зарплат по возрастанию идентификатора сотрудника.
Например, в 1987 году на работу в компанию были приняты 3 сотрудника:
| EMPLOYEE ID | LAST NAME | SALARY |
| King | ||
| Whalen | ||
| Smith | 4400 ' |
King'y присваивается место 1, поскольку у него наибольший оклад.
Whalen и Smith имеют одинаковые оклады, меньшие, чем у King'a. Однако, идентификатор Whalen'a меньше идентификатора Smith'a, поэтому Whalen'y присваивается место 2, a Smith'y -место 3.
Результат должен быть упорядочен:
1. По года приема на работу по возрастанию.
2. По идентификатору сотрудника по возрастанию.
SELECT employee_id, to_char(hire_date, 'YYYY'), first_name, last_name, salary,
dense_rank() over (partition by to_char(hire_date, 'YYYY') order by salary desc,employee_id) As "NUMBER"
FROM employees
ORDER BY to_char(hire_date, 'YYYY'),salary desc, employee_id
Результат:
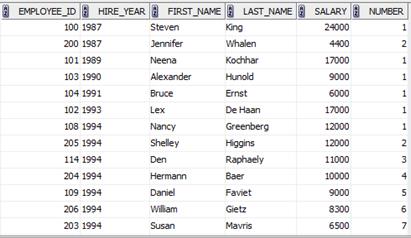
Комментарий:
Для решения задачи я использовала аналитическую функцию для расчета плотного ранга dense_rank(), который является «местом» сотрудника в группе сотрудников, принятых на работу в одном и том же году, упорядоченных по убыванию зарплаты, а в случае равенства зарплат по возрастанию идентификатора сотрудника. Для подсчета ранга записи группировались по году принятия на работу и сортировались по году принятия на работу и идентификатору сотрудника. Для получения года принятия на работу к дате принятия на работу был применен формат 'YYYY'.
7. Одной командой SELECT выбрать сотрудников, в именах которых встречаются две одинаковые английские буквы подряд. В результат вывести:
1. Идентификатор сотрудника
2. Имя сотрудника
3. Фамилию сотрудника
Строки результата не должны дублироваться. Результат упорядочить по идентификатору сотрудника.
SELECT employee_id, first_name, last_name
FROM employees
WHERE REGEXP_LIKE(lower(first_name), '([[:alpha:]]{1})\1')
Результат:

Комментарий:
Задание было решено при помощи регулярных выражений, для поиска был использован шаблон '([[:alpha:]]{1})\1'.
Чтобы на результат поиска не влиял регистр, имя сотрудника приводится к нижнему регистру.
8. Одной командой SELECT рассчитать, какие символы в каком количестве содержатся в именах всех сотрудников. Буквы привести к заглавным (большим). Результат вывести в виде таблицы из двух столбцов:
1. Символ
2. Суммарное количество таких символов в именах всех сотрудников.
Упорядочить по первому столбцу по возрастанию.
SELECT symbol,count(symbol) cnt
FROM(
SELECT substr(f_name, level, 1) Symbol
FROM (SELECT max(ltrim(sys_connect_by_path(upper(first_name), ', '), ',')) f_name
FROM (SELECT first_name,row_number () over (order by first_name) rn
FROM employees)
START WITH rn=1
CONNECT by prior rn = rn-1)
CONNECT by level<=length(f_name))
WHERE symbol not in (' ',',')
GROUP BY symbol
ORDER BY symbol
Результат:
SYMBOL CNT
-------------- ------
A 89
B 5
C 11
D 24
E 78
F 2
G 5
H 25
I 44
J 17
K 10
L 54
M 19
N 59
O 19
P 8
R 37
S 34
T 35
U 15
V 10
W 4
X 4
Y 12
Z 3
Комментарий:
Соединяем все имена сотрудников в одну строку, после чего выбираем из нее все символы по порядку. После этого все символы делятся на группы, и считается количество символов, кроме запятых (которыми разделены имена в строке) и пробелов,
9. Разбить всех сотрудников на следующие группы по размеру оклада:
Группа 1. До 10000 включительно
Группа 2. Свыше 10000 до 13000 включительно
Группа 3. Свыше 13000 до 16000 включительно
Группа 4. Свыше 16000 до 19000 включительно
Группа 5. Свыше 19000 до 22000 включительно
Группа 6. Свыше 22000
Вывести суммарную информацию по этим группам:
1. Номер группы
2. Минимальная зарплата в группе
3. Максимальная зарплата в группе
4. Количество сотрудников в группе
5. Общая сумма зарплат в группе
Отсортировать результат по номеру группы по возрастанию.
SELECT Group_number, min(salary),max(salary),count(employee_id), sum(salary)
FROM(
SELECT CASE
when salary<=10000 THEN 1
when salary<=13000 THEN 2
when salary<=16000 THEN 3
when salary<=19000 THEN 4
when salary<=22000 THEN 5
else 6
END Group_number, employee_id,salary
FROM employees)
GROUP BY Group_number
ORDER by Group_number
Результат:

Комментарий:
Для решения задачи использовалась конструкция CASE, при помощи которой записи о сотрудниках распределялись в группы по размеру зарплаты, после чего они были сгруппированы по номеру группы, что позволило вычислить максимальные и минимальные заработные платы в группах, количество сотрудников в группе и суммарную зарплату по группе. После чего записи были отсортированы номеру группы по возрастанию.
10. Вычислить число Пи с точностью 40 знаков после запятой.
SELECT '3'||substr(to_char(pi,'0.9999999999999999999999999999999999999999'),3) AS pi
FROM(
SELECT mod(1+4*sum(pi),1) pi
FROM (
SELECT (CASE mod(level/2,1)
WHEN 0 THEN -mod(1/(2*level -1),1)
else mod(1/(2*level -1),1)
END) pi
FROM DUAL
CONNECT BY level<=2000000))
Результат:
PI
---------------------------------------------------------------
3.1415921535897932384938933832794931185768
11. Одной командой SELECT построить таблицу, в которой отразить количество сотрудников, работающих в соответствующей должности по годам, ориентируясь по значению hire_date в таблице сотрудников.
Строки таблицы результата должны соответствовать годам с 1987 до 2001.
Столбцы таблицы результата:
Первый столбец - год, остальные количество сотрудников, работавших в данном году в соответствующей должности.
Второй столбец - количество сотрудников, работавших в должности с кодом AC_ACCOUNT,
Третий столбец - количество сотрудников, работавших в должности с кодом AC_MGR,
Четвертый столбец - количество сотрудников, работавших в должности с кодом AD_ASST, и так далее по всем должностям, упорядоченным по возрастанию кода.
В последнем столбце вывести общее количество сотрудников, работавших в компании в данном году.
Таблица результата должна быть упорядочена по году по возрастанию.
SELECT to_char(hire_date,'YYYY') AS "HIRE_YEAR",
sum(CASE when job_id = 'AC_ACCOUNT' then 1 else 0 END) AS "AC_ACCOUNT",
sum(CASE when job_id = 'AC_MGR' then 1 else 0 END) AS "AC_MGR",
sum(CASE when job_id = 'AD_ASST' then 1 else 0 END) AS "AD_ASST",
sum(CASE when job_id = 'AD_PRES' then 1 else 0 END) AS "AD_PRES",
sum(CASE when job_id = 'AD_VP' then 1 else 0 END) AS "AD_VP",
sum(CASE when job_id = 'FI_ACCOUNT' then 1 else 0 END) AS "FI_ACCOUNT",
sum(CASE when job_id = 'FI_MGR' then 1 else 0 END) AS "FI_MGR",
sum(CASE when job_id = 'HR_REP' then 1 else 0 END) AS "HR_REP",
sum(CASE when job_id = 'IT_PROG' then 1 else 0 END) AS "IT_PROG",
sum(CASE when job_id = 'MK_MAN' then 1 else 0 END) AS "MK_MAN",
sum(CASE when job_id = 'MK_REP' then 1 else 0 END) AS "MK_REP",
sum(CASE when job_id = 'PR_REP' then 1 else 0 END) AS "PR_REP",
sum(CASE when job_id = 'PU_CLERK' then 1 else 0 END) AS "PU_CLERK ",
sum(CASE when job_id = 'PU_MAN' then 1 else 0 END) AS "PU_MAN",
sum(CASE when job_id = 'SA_MAN' then 1 else 0 END) AS "SA_MAN ",
sum(CASE when job_id = 'SA_REP' then 1 else 0 END) AS "SA_REP",
sum(CASE when job_id = 'SH_CLERK' then 1 else 0 END) AS "SH_CLERK ",
sum(CASE when job_id = 'ST_CLERK' then 1 else 0 END) AS "ST_CLERK ",
sum(CASE when job_id = 'ST_MAN' then 1 else 0 END) AS "ST_MAN",
count(*) AS "SUMMARY"
FROM employees
WHERE to_char(hire_date,'YYYY') between 1987 and 2001
GROUP BY to_char(hire_date,'YYYY')
ORDER BY to_char(hire_date,'YYYY')
Результат:

Комментарий:
В этом запросе сотрудники проверяются на принадлежность к одной из должностей (если принадлежит должности, то 1, иначе 0). После этого полученные результаты суммируются по годам, что позволяет получить количество сотрудников, работающих в соответствующей должности и принятых на работу в определенном году.
12. Вывести в виде таблицы доли зарплаты сотрудников в общем фонде зарплаты в виде строк по каждому из сотрудников, предваряемых строкой по отделу в целом.
1. Название отдела
2. Фамилия сотрудника или пусто, если строка относится к отделу в целом
3. Доля зарплаты сотрудника или отдела в процентах с точностью 2 знака после запятой
Общую зарплату считать для всех сотрудников, у которых есть указание о принадлежности к отделу, выводить только отделы, в которых есть сотрудники. Следует обеспечить общую сумму долей отделов равной 100%, а в каждом отделе сумма долей сотрудников должна быть равна доле отдела в целом. Для выравнивания использовать последних по алфавиту сотрудников в отделе и последний по алфавиту отдел.
Таблица должна быть упорядочена по названию отдела, фамилии сотрудника.
Дата добавления: 2015-08-18; просмотров: 149 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Main_Table PK User_Constraints 17 страница | | | Main_Table PK User_Constraints 19 страница |