|
Читайте также: |
5. Создать запрос для вывода списка дисциплин, по которым на сессии было получено максимальное количество пятерок.
WITH fives AS
(
SELECT название, COUNT(*) SumFives
FROM Успеваемость NATURAL JOIN Дисциплины
WHERE оценка = 5
GROUP BY название
)
SELECT название
FROM fives
WHERE SumFives IN (SELECT MAX(SumFives) FROM fives)
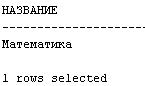
Комментарий:
В разделе WITH соединяем две таблицы: “Успеваемость” и “Дисциплины”, находим количество пятерок по дисциплинам. Из полученного результата выбираем максимальное количество пятерок и выводим название этой дисциплины.
6. Есть таблица с парами значений, связанными отношением. Одно значение может быть связано с несколькими, те в свою очередь могут быть связаны друг с другом. В результате, значения транзитивно образуют связанные множества. На входе имеем некое значение, нужно получить все элементы множества, к которому оно относится. Результат вывести в виде строки с запятой в качестве разделителя.
CREATE TABLE task6(znach1 number(3), znach2 number(3));
INSERT INTO task6 VALUES (1, 1);
INSERT INTO task6 VALUES (1, 2);
INSERT INTO task6 VALUES (2, 3);
INSERT INTO task6 VALUES (4, 1);
INSERT INTO task6 VALUES (7, 10);
INSERT INTO task6 VALUES (7, 9);
INSERT INTO task6 VALUES (2, 5);
INSERT INTO task6 VALUES (6, 11);
INSERT INTO task6 VALUES (7, 1);
INSERT INTO task6 VALUES (5, 12);
INSERT INTO task6 VALUES (6, 10);
INSERT INTO task6 VALUES (8, 2);
SELECT *
FROM task6

undefine insert_number;
WITH tab AS (SELECT length(y) z,y
FROM (SELECT Ltrim(sys_connect_by_path(znach2, ', '), ', ') y
FROM (SELECT znach2, rownum x
FROM (
SELECT DISTINCT znach2
FROM task6
WHERE znach2!= &&insert_number
START WITH znach2 = &&insert_number
CONNECT BY NOCYCLE znach1 = PRIOR znach2 ORDER BY 1))
CONNECT BY PRIOR x +1 = x))
SELECT y FROM tab WHERE z = (SELECT max(z) FROM tab)
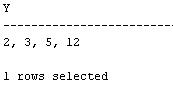
Комментарий:
Создаем необходимую таблицу и заполняем ее данными. Выводим всех связанные сущности. В таблице возможны циклы, чтобы вывести данные в случае возникновения циклов используем опцию NOCYCLE. Далее приводим результат к нужному виду, разграничиваем значения запятыми, отсекаем первый символ и выводим результат.
7. Имеется таблица с тремя столбцами: именем, фамилией и коэффициентом размножения. Требуется написать запрос, выводящий таблицу, содержащую строки с именами и фамилиями двух сотрудников. Число строк для каждого сотрудника должно определяться коэффициентом размножения. То есть, если Иван Петров имел коэффициент размножения 3, а Сергей Сидоров – коэффициент размножения 5, то в результатах запроса должны быть 3 строки для сотрудника Петрова и 5 строк для Сидорова.
Строки должны быть объединены в группы и отсортированы по фамилии и имени.
Кроме того, должны быть пронумерованы элементы внутри группы и должна присутствовать сквозная нумерация. Этот запрос должен работать для произвольного количества строк в исходной таблице.
CREATE TABLE task7(first_name varchar2(25), last_name varchar2(25), k number(2));
INSERT INTO task7 values ('Иван','Петров',3);
INSERT INTO task7 values ('Сергей','Сидоров',5);
SELECT *
FROM task7

SELECT rownum "Сквозной №", n "№ в группе", first_name "Имя", last_name "Фамилия"
FROM
(
SELECT distinct n,first_name,last_name from
(
SELECT level n,first_name,last_name
FROM task7
CONNECT BY level <= k
)
ORDER BY first_name, n
) 
Пример выходного отчёта:
| Сквозной № | № в группе | Имя | Фамилия |
| Иван | Петров | ||
| Иван | Петров | ||
| Иван | Петров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров |
8 rows selected.
8. Создать запрос для вывода списка фамилий студентов, которые не сдали ни одного экзамена в сессию, т.е. они могли делать попытки, но эти попытки были неудачными.
WITH f_stud AS
(
SELECT номер_студента
FROM Студенты
MINUS
SELECT номер_студента
FROM Успеваемость
WHERE оценка > 2
)
SELECT фамилия
FROM f_stud NATURAL JOIN Студенты;

Комментарий:
Находим разность между всеми студентами и студентами, у которых оценка больше двух баллов. Cвязываем полученный результат с таблицей “Студенты”, чтобы получить фамилии студентов.
9. Используя обращение только к таблице DUAL, построить SQL-запрос, возвращающий один столбец, содержащий календарь на текущий месяц текущего года:
номер дня в месяце (две цифры),
полное название месяца по-английски заглавными буквами (в верхнем регистре),
год (четыре цифры),
полное название дня недели по-английски строчными буквами (в нижнем регистре).
Каждое "подполе" должно быть отделено от следующего одним пробелом. В результате не должно быть начальных и хвостовых пробелов. Количество возвращаемых строк должно точно соответствовать количеству дней в текущем месяце. Строки должны быть упорядочены по номерам дней в месяце по возрастанию.
WITH res AS (SELECT trunc(sysdate,'mm')+level-1 d
FROM dual connect by level <=to_char(last_day(sysdate),'dd'))
SELECT to_char(d,'dd fmMONTH yyyy day','NLS_DATE_LANGUAGE=AMERICAN') "This Month"
FROM res
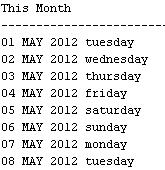
…

Комментарий:
В разделе WITH выбираем дату, усеченную до месяца и запускаем цикл. Далее приводим дату к виду, прописанному в задании.
10. Создать запрос для вывода списка фамилий студентов-хвостистов с указанием дисциплин, которые им необходимо еще досдать в данную сессию.
SELECT фамилия, название
FROM Студенты JOIN Группы USING (номер_группы)
JOIN Специальности USING (код_специальности)
JOIN Учебные_планы USING (код_специальности)
JOIN Дисциплины USING (номер_дисциплины)
MINUS
SELECT фамилия, название
FROM Студенты JOIN Успеваемость USING (номер_студента)
JOIN Дисциплины USING (номер_дисциплины)
WHERE оценка > 2

Комментарий:
Находим для студентов список тех дисциплин, которые необходимо сдавать, соединяя таблицы: “Студенты”, “ Группы”, ”Специальности”, ”Учебные_планы”, ”Дисциплины ”, находим для студентов список тех дисциплин, которые уже сданы, соединяя таблицы: “Студенты”, ”Успеваемость”, “Дисциплины” при условии, что оценка больше двух. Находим разность.
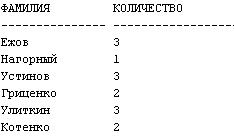
11. Создать запрос для вывода списка фамилий студентов с указанием количества несданных ими в сессию дисциплин.
SELECT фамилия, COUNT(название)
FROM
(SELECT фамилия, название
FROM Студенты JOIN Группы USING (номер_группы)
JOIN Специальности USING (код_специальности)
JOIN Учебные_планы USING (код_специальности)
JOIN Дисциплины USING (номер_дисциплины)
MINUS
SELECT фамилия, название
FROM Студенты JOIN Успеваемость USING (номер_студента)
JOIN Дисциплины USING (номер_дисциплины)
WHERE оценка > 2)
GROUP BY фамилия
Комментарий:
Из данных, полученных в прошлом запросе, находим для каждого студента количество несданных в сессию экзаменов
12. Создать запрос для вывода списка названий специальностей, по которым учится максимальное количество групп.
WITH spec_sum AS
(
SELECT название_специальности, COUNT(*) AS Num
FROM Специальности NATURAL JOIN Группы
GROUP BY название_специальности
)
SELECT название_специальности
FROM spec_sum
WHERE Num IN (SELECT MAX(Num) FROM spec_sum)

Комментарий:
В разделе WITH соединяем две таблицы: “Специальности” и “Группы”, находим количество групп по специальностям. Из полученного результата выбираем максимальное количество групп и выводим название этой специальности.
13. Создать запрос для вывода списка групп, в которых нет должников.
SELECT distinct номер_группы
FROM группы
MINUS
(
SELECT DISTINCT номер_группы FROM
(
SELECT номер_дисциплины,фамилия фам, номер_группы
FROM Студенты JOIN Группы USING (номер_группы)
JOIN Специальности USING (код_специальности)
JOIN Учебные_планы USING (код_специальности)
JOIN Дисциплины USING (номер_дисциплины)
MINUS
SELECT номер_дисциплины,фамилия,номер_группы
FROM успеваемость NATURAL JOIN студенты
WHERE оценка>2
)
)

Комментарий:
Находим для всех студентов список всех экзаменов и отнимаем от него не двоечников. Если в группе хотя бы один человек сдал на 2, то она будет в этом списке.
14. Создать запрос для получения информации о группах:
| Группа | Кол-во студентов | Название Специальности | Кол-во круглых отличников | Кол-во должников |
| …… |
WITH dol AS
(
SELECT distinct номер_студента,группы.номер_группы
FROM УЧЕБНЫЕ_ПЛАНЫ join ("ГРУППЫ" join "СТУДЕНТЫ"
ON группы.номер_группы=студенты.номер_группы)
ON учебные_планы.код_специальности=Группы."КОД_СПЕЦИАЛЬНОСТИ"
WHERE (номер_студента,номер_дисциплины) not in
(
SELECT номер_студента,номер_дисциплины
FROM успеваемость NATURAL JOIN студенты
WHERE оценка>2
)
),
ne_otl AS
(
SELECT distinct nom,групп
FROM
(
SELECT номер_студента nom,номер_дисциплины,студенты.номер_группы групп
FROM УЧЕБНЫЕ_ПЛАНЫ JOIN ("ГРУППЫ" JOIN "СТУДЕНТЫ"
ON группы.номер_группы=студенты.номер_группы)
ON учебные_планы.код_специальности=Группы."КОД_СПЕЦИАЛЬНОСТИ"
MINUS
SELECT номер_студента,номер_дисциплины,номер_группы
FROM успеваемость NATURAL JOIN студенты
WHERE оценка=5
)
)
SELECT номер_группы,
(
SELECT COUNT(номер_студента)
FROM студенты
WHERE студенты.Номер_группы=группы.номер_группы
) AS "количество_студентов",
название_специальности,
(
(
SELECT COUNT(номер_студента)
FROM студенты
WHERE студенты.Номер_группы=группы.номер_группы
) -
(
SELECT COUNT(*)
FROM ne_otl
WHERE ne_otl.групп=группы.номер_группы
)
) AS "кол-во отличников",
(
SELECT COUNT(*)
FROM dol
WHERE dol.номер_группы=группы.номер_группы
) AS "кол-во должников"
FROM группы NATURAL JOIN специальности;

Комментарий:
В разделе WITH находим должников(сдали на 2 или не сдавали), людей, которые не являются круглыми отличниками. Далее считаем количество студентов, круглых отличников и должников.
колво отличников=колво-студентов и неотличники.
15. Создать три таблицы Системы Автоматического Управления, Математическое Обеспечение ЭВМ, Вычислительные Сети и Системы. Используя возможности многотабличной вставки, записать в эти таблицы информацию о студентах в соответствии со специальностью, на которой они учатся.
CREATE TABLE "Системы Автомат-ого Управления"
(номер_студента number(5),
фамилия varchar2(15),
имя varchar2(15),
отчество varchar2(15),
стипендия number(7,2),
номер_группы varchar2(15));
CREATE TABLE "Математическое Обеспечение ЭВМ"
(номер_студента number(5),
фамилия varchar2(15),
имя varchar2(15),
отчество varchar2(15),
стипендия number(7,2),
номер_группы varchar2(15));
CREATE TABLE "Вычислительные Сети и Системы"
(номер_студента number(5),
фамилия varchar2(15),
имя varchar2(15),
отчество varchar2(15),
стипендия number(7,2),
номер_группы varchar2(15));
commit;
INSERT ALL
WHEN код_специальности = 1
THEN INTO "Системы Автомат-ого Управления" VALUES (номер_студента, фамилия, имя, отчество, стипендия, номер_группы)
WHEN код_специальности = 2
THEN INTO "Математическое Обеспечение ЭВМ" VALUES (номер_студента, фамилия, имя, отчество, стипендия, номер_группы)
WHEN код_специальности = 3
THEN INTO "Вычислительные Сети и Системы" VALUES (номер_студента, фамилия, имя, отчество, стипендия, номер_группы)
SELECT *
FROM студенты NATURAL JOIN группы NATURAL JOIN специальности;
SELECT *
FROM "Системы Автомат-ого Управления"

Комментарий:
Создаем нужные таблицы. В зависимости от номера специальности расфасовываем студентов по таблицам.
16. Создать представление для получения информации по специальностям: Средняя оценка среди студентов специальности, сдавших экзамены; Количество студентов специальности, сдавших экзамены, Общее количество студентов на специальности.
CREATE VIEW myView ("Название специальности", "Средняя оценка", "Количество сдавших", "Всего студентов") as
(
SELECT название_специальности, avg_Score, COUNT(*), all_Stud
FROM
(
SELECT distinct название_специальности, номер_студента, avg(оценка) over (partition by название_специальности) avg_Score,
(
SELECT COUNT(*)
FROM специальности NATURAL JOIN группы NATURAL JOIN студенты
WHERE специальности.название_специальности = tMain.название_специальности
) all_Stud
FROM
(
SELECT номер_студента, название_специальности, оценка, min(nvl(оценка,0)) over (partition by номер_студента) min_Score
FROM студенты NATURAL JOIN группы NATURAL JOIN специальности LEFT JOIN учебные_планы USING(код_специальности)
LEFT JOIN успеваемость USING(номер_студента)
) tMain
WHERE min_Score > 2
)
GROUP BY название_специальности, avg_Score, all_Stud
)

Комментарий:
Находим число студентов на специальности, считаем среднюю оценку и объединяем все записи для одного студента. Затем считаем число студентов на каждой специальности, выводим информацию о студентах и их оценке. Сдавшие студенты – это те, у кого минимальная оценка больше двух.
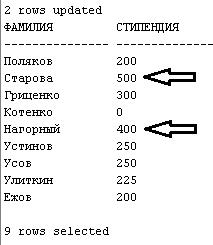
17. Увеличить вдвое стипендию студентам, которые сдали все предусмотренные учебным планом для их специальности экзамены с первого раза на отлично.
UPDATE студенты
SET стипендия = стипендия * 2
WHERE номер_студента IN
(SELECT s.номер_студента
FROM студенты s INNER JOIN группы g ON s.номер_группы=g.номер_группы
INNER JOIN учебные_планы tp ON tp.код_специальности=g.код_специальности
INNER JOIN успеваемость pr ON pr.номер_студента=s.номер_студента
GROUP BY s.номер_студента
HAVING avg(nvl(оценка,2))=5);
SELECT фамилия, стипендия
FROM Студенты
Комментарий:
Соединяем таблицы, чтобы выбрать студентов, которые сдали все предусмотренные учебным планом для их специальности экзамены с первого раза на отлично. Если студенты не сдали экзамен, то будем считать этот результат как двойку nvl(оценка,2), Находим среднее по полученным оценкам. Если у студента хоть одна не пятерка или он хоть раз пересдавал экзамен, то средний бал будет ниже пяти. Мы выбираем только те значения, где средняя оценка = 5. Увеличиваем студентам с полученными номерами удвоенную стипендию.
18. Создать запрос для определения среднего интервала между датами сдачи экзаменов для каждого студента.
SELECT фамилия,avg(intervals)"Средний интервал"
FROM(
SELECT s.фамилия, pr2.дата-pr1.ДАТА AS intervals
FROM (успеваемость pr1 INNER JOIN успеваемость pr2
ON pr1.номер_студента = pr2.номер_студента) JOIN СТУДЕНТЫ s ON pr1.номер_студента = s.номер_студента
WHERE pr1.номер_дисциплины!= pr2.номер_дисциплины AND pr2.дата-pr1.дата > 0
ORDER BY pr1.номер_студента)
GROUP BY фамилия

Комментарий:
Соединяем таблицу саму с собой, так чтобы получить все возможные комбинации студента и его экзаменов. Вычисляем разницы дат в этих комбинациях, оставляем только те, что больше нуля, чтобы избежать дублирования записей. Находим среднее.
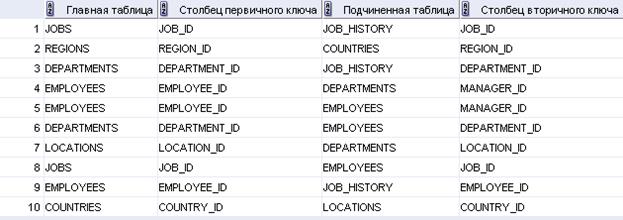
19. Создать запрос, который позволит получить информацию о таблицах схемы HR в виде:
| Главная таблица | Столбец первичного ключа | Подчиненная таблица | Столбец вторичного ключа |
WITH info AS
(
SELECT DISTINCT a1.table_name tab1,a1.constraint_name con1, a2.table_name tab2, a2.constraint_name con2
FROM all_constraints a1 JOIN all_constraints a2
ON a1.constraint_name = a2.r_constraint_name
AND a1.owner = 'HR' AND a2.owner = 'HR'
)
SELECT DISTINCT i.tab1 "Главная таблица", a1.column_name "Столбец первичного ключа", i.tab2 "Подчиненная таблица", a2.column_name "Столбец вторичного ключа"
FROM info i JOIN all_cons_columns a1
ON i.con1 = a1.constraint_name
JOIN all_cons_columns a2
ON i.con2 = a2.constraint_name
Комментарий:
Выводим имена ограничений и имена таблиц,соединив таблицу саму с собой, так чтобы имя ограничения главной таблицы было равно имени ограничения подчиненной.
На основе данных в all_cons_columns, получаем название столбцов по названию ограничений.
20. Для произвольной строки, состоящей из чисел, разделенных указанным разделителем, получить строку, отображающую эти числа в обратном порядке. Например, для исходной строки: 0|0|1|2|1|2|10|22|34|15|0|105|66|73 должна быть получена строка: 73|66|105|0|15|34|22|10|2|1|2|1|0|0. Задачу решить: с использованием регулярных выражений;с использованием раздела Model.
SELECT ltrim(REPLACE(MAX(sys_connect_by_path(s, ' ')), ' ', ''), '\') Res
FROM (SELECT s,t, lag(t) OVER (ORDER BY t) lg
FROM (SELECT s, ROWNUM t
FROM (SELECT s
FROM (SELECT '0|0|1|2|1|2|10|22|34|15|0|105|66|73' x from dual)
MODEL
RETURN UPDATED ROWS
DIMENSION BY (0 d)
MEASURES (x t, '\' s)
RULES ITERATE(1000000) UNTIL (iteration_number = length(t[0]))
(s[iteration_number+1] = substr(reverse(t[0]), iteration_number,1))
)))
START WITH lg IS NULL
CONNECT BY PRIOR t = lg

Комментарий:
В разделе Model записываем символы строки через пробел, а в начало строки записываем символ “\”. Далее из всех вариантов составления символов из строки выбираем максимум, затем заменяем пробелы и символ “\” на пустое значение. В итоге получаем строку с разделителями в обратном порядке.
ВАРИАНТ 12
(Базы данных Студент и Human Resources)
1. Получить информацию о подчиненности таблиц в схеме в виде:
ИмяТаблицы1(ИмяFK1 ссылается на ИмяТаблицы2/ИмяPK2)
ИмяТаблицы2(ИмяFK2 ссылается на ИмяТаблицы3/ИмяPK3) ……
SELECT ucc1.table_name || '(' || ucc1.column_name || ' ссылается на ' || ucc2.table_name || '/' || ucc2.column_name || ')' rnFROM user_constraints uc, user_cons_columns ucc1, user_cons_columns ucc2WHERE uc.constraint_name = ucc1.constraint_nameAND uc.r_constraint_name = ucc2.constraint_nameAND ucc1.position = ucc2.positionAND uc.constraint_type = 'R' Соединяем таблицы пользовательских ограничений и пользовательских колонок (эту два раза, так как нам нужны таблицы и колонки «по обе стороны» ограничения) ucc1.position = ucc2.position – для исключения дублей RN -------------------------------------------------------------------------------------…ГРУППЫ(КОД_СПЕЦИАЛЬНОСТИ ссылается на СПЕЦИАЛЬНОСТИ/КОД_СПЕЦИАЛЬНОСТИ) ДИСЦИПЛИНЫ(НОМЕР_ПРЕПОДАВАТЕЛЯ ссылается на ПРЕПОДАВАТЕЛИ/НОМЕР_ПРЕПОДАВАТЕЛЯ) ПРЕПОДАВАТЕЛИ(ПОДЧИНЯЕТСЯ ссылается на ПРЕПОДАВАТЕЛИ/НОМЕР_ПРЕПОДАВАТЕЛЯ) ПРЕПОДАВАТЕЛИ2(ПОДЧИНЯЕТСЯ ссылается на ПРЕПОДАВАТЕЛИ/НОМЕР_ПРЕПОДАВАТЕЛЯ) СТУДЕНТЫ(НОМЕР_ГРУППЫ ссылается на ГРУППЫ/НОМЕР_ГРУППЫ) УСПЕВАЕМОСТЬ(НОМЕР_СТУДЕНТА ссылается на СТУДЕНТЫ/НОМЕР_СТУДЕНТА) УСПЕВАЕМОСТЬ(НОМЕР_ДИСЦИПЛИНЫ ссылается на ДИСЦИПЛИНЫ/НОМЕР_ДИСЦИПЛИНЫ) УЧЕБНЫЕ_ПЛАНЫ(КОД_СПЕЦИАЛЬНОСТИ ссылается на СПЕЦИАЛЬНОСТИ/КОД_СПЕЦИАЛЬНОСТИ) УЧЕБНЫЕ_ПЛАНЫ(НОМЕР_ДИСЦИПЛИНЫ ссылается на ДИСЦИПЛИНЫ/НОМЕР_ДИСЦИПЛИНЫ) 33 rows selected Другой вариант решения задачи: SELECT LPAD(' ', level, ' ')||rn p FROM (SELECT ucc1.table_name t1, ucc2.table_name t2, ucc1.table_name || '(' || ucc1.column_name || ' ссылается на ' || ucc2.table_name || '/' || ucc2.column_name || ')' rnFROM user_constraints uc, user_cons_columns ucc1, user_cons_columns ucc2WHERE uc.constraint_name = ucc1.constraint_nameAND uc.r_constraint_name = ucc2.constraint_nameAND ucc1.position = ucc2.positionAND uc.constraint_type = 'R')CONNECT BY NOCYCLE PRIOR t2 = t1 Фактически, тут делается то же самое, что и в предыдущем решении, но добавляется иерархичность с помощью connect by.
2. Вывести список сотрудников с указанием плотного ранга его зарплаты в отделе, в котором работает сотрудник. Решить без использования аналитических функций.
SELECT e1.department_id, e1.employee_id, e1.last_name, COUNT (e2.salary) + 1 rFROM employees e1 LEFT JOIN employees e2ON e1.department_id = e2.department_id AND e1.salary > e2.salaryGROUP BY e1.department_id, e1.employee_id, e1.last_nameORDER BY e1.department_id, r Соединяем таблицу сотрудников саму с собой (left join) формируя порядок по зарплате. Потом вычисляем количество зарплат меньше, которое и будет плотным рангом. В вывод на всякий случай добавил фамилии DEPARTMENT_ID EMPLOYEE_ID LAST_NAME R------------- ----------- ------------------------- - 10 200 Whalen 1 20 202 Fay 1 20 201 Hartstein 2 30 119 Colmenares 1 30 118 Himuro 2 30 117 Tobias 3 30 116 Baida 4 30 115 Khoo 5 30 114 Raphaely 6 40 203 Mavris 1 50 132 Olson 1 50 136 Philtanker 2 50 128 Markle 2 50 127 Landry 4 50 135 Gee 4 50 140 Patel 6
3. Определить коэффициент корреляции между средними оценками, полученными студентами на экзамене, и их стипендией.
WITH таб AS (SELECT AVG(оценка) оц, стипендия стип FROM студенты ст JOIN успеваемость у ON ст.номер_студента = у.номер_студента GROUP BY ст.номер_студента, стипендия)SELECT TRUNC (AVG (кор), 8) корелляция FROM (SELECT CORR(стип, оц) OVER (ORDER BY стип) кор FROM таб) Использовал аналитическую функцию corr() over() КОРЕЛЛЯЦИЯ-----------0,52037599
4. Написать запрос для определения количества 29-х февраля между двумя произвольными датами.
UNDEFINE firstdate;UNDEFINE seconddate; SELECT COUNT(DateL)FROM (SELECT TO_DATE(LEAST('&&seconddate', '&&firstdate')) - 1 + level DateL, level --TO_DATE('&&firstdate'), TO_DATE('&&seconddate')FROM dualCONNECT BY LEVEL < ABS(TO_DATE('&&seconddate') - TO_DATE('&&firstdate')) + 2) WHERE TO_CHAR(DateL, 'dd-mm') = '29-02' Для вычисления я выстраиваю список всех дат между введенными, а потом подсчитываю в них количество нам необходимых. Для seconddate = 01.01.01 и firstdate = 10.10.10 COUNT(DATEL)------------ 2
5. Создать запрос для вывода фамилий преподавателей, имеющих общих непосредственных начальников.
SELECT начальник "Id начальника", фам "Начальник", LTRIM(MAX(sys_connect_by_path(фамилия, ', ')), ', ') "Общий непосредственный для:"FROM (SELECT начальник, п3.фамилия, фам, ROW_NUMBER() OVER (PARTITION BY начальник ORDER BY п3.фамилия) ro, RANK() OVER (ORDER BY начальник) raFROM (SELECT п2.номер_преподавателя начальник, п2.фамилия фам, COUNT(п1.номер_преподавателя) колFROM преподаватели п1INNER JOIN преподаватели п2 ON п1.подчиняется = п2.номер_преподавателяGROUP BY п2.номер_преподавателя, п2.фамилия) INNER JOIN преподаватели п3 ON начальник = п3.подчиняетсяWHERE кол > 1)GROUP BY начальник, фамSTART WITH ro = 1CONNECT BY PRIOR ro = ro - 1 and prior ra = ra Внутренним запросом отсеиваем тех, у кого один подчиненный. Потом получаем строки вида: |начальник|тот_кто_ему_подчиняется|, а потом объединяем в одну строку подчиненных с помощью connect by. Дополнительно в ответ вывожу фамилию начальника Id начальника Начальник Общий непосредственный для: ------------- -------------------- --------------------------------------------- 4008 Абдулов Загарийчук, Студейкин, Тарасова Соответственно подкорректированный вариант для employees: SELECT начальник "Id начальника", фам "Фамилия", MAX(LTRIM(sys_connect_by_path(last_name, ','), ',')) "Общий непосредственный для:"FROM (SELECT начальник, e3.last_name, фам, ROW_NUMBER() OVER (PARTITION BY начальник ORDER BY e3.last_name) ro, RANK() OVER (ORDER BY начальник) raFROM (SELECT e2.employee_id начальник, e2.last_name фам, COUNT(e1.employee_id) колFROM employees e1INNER JOIN employees e2 ON e1.manager_id = e2.employee_idGROUP BY e2.employee_id, e2.last_name) INNER JOIN employees e3 ON начальник = e3.manager_idWHERE кол > 1)GROUP BY начальник, фамSTART WITH ro = 1CONNECT BY PRIOR ro = ro - 1 and prior ra = ra Id начальника Фамилия Общий непосредственный для: ------------- ------------------------- ---------------------------------------- 101 Kochhar Baer,Greenberg,Higgins,Mavris,Whalen 146 Partners Doran,King,McEwen,Sewall,Smith,Sully 148 Cambrault Bates,Bloom,Fox,Kumar,Ozer,Smith 108 Greenberg Chen,Faviet,Popp,Sciarra,Urman 147 Errazuriz Ande,Banda,Greene,Lee,Marvins,Vishney 122 Kaufling Chung,Dilly,Gates,Gee,Mallin,Perkins,Philtanker,Rogers 100 King Cambrault,De Haan,Errazuriz,Fripp,Hartstein,Kaufling,Kochhar,Mourgos,Partners,Raphaely,Russell,Vollman,Weiss,Zlotkey 120 Weiss Fleaur,Geoni,Landry,Markle,Mikkilineni,Nayer,Sullivan,Taylor 121 Fripp Atkinson,Bissot,Bull,Cabrio,Dellinger,Marlow,Olson,Sarchand 145 Russell Bernstein,Cambrault,Hall,Olsen,Tucker,Tuvault 103 Hunold Austin,Ernst,Lorentz,Pataballa 149 Zlotkey Abel,Grant,Hutton,Johnson,Livingston,Taylor 114 Raphaely Baida,Colmenares,Himuro,Khoo,Tobias 123 Vollman Bell,Everett,Jones,Ladwig,McCain,Patel,Seo,Stiles 124 Mourgos Davies,Feeney,Grant,Matos,OConnell,Rajs,Vargas,Walsh
Дата добавления: 2015-08-18; просмотров: 245 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Main_Table PK User_Constraints 8 страница | | | Main_Table PK User_Constraints 10 страница |