|
Читайте также: |
Комментарий:
Первым временным представлением создаем текстовые цепочки сумм с помощью sys_connect_by_path. То же самое, что в итоговом столбце «сумма», но с лидирующим знаком «+».
Во втором временном представлении организовываем основной вывод результата: от результата предыдущего представления убираем лидирующий «+». Для того, чтобы сосчитать сумму из строки con_by_path используем подзапрос: каждое число столбца “A” проверяем на наличие в строке +'||A||, и если находим, то суммируем.
14. Создать запрос для получения сведений (Фамилия, Группа, Специальность, Отличник/Хорошист) обо всех отличниках в группе, а если таковых нет, то обо всех хорошистах. (Под отличниками понимаем студентов, сдавших все предусмотренные учебные планом экзамены на отлично с первого раза. Под хорошистами понимаем студентов, сдавших все предусмотренные учебные планом экзамены на отлично или хорошо с первого раза).
WITH otl AS
(SELECT номер_студента, 'отличник' "SM"
FROM
(SELECT DISTINCT номер_студента
FROM успеваемость
MINUS
SELECT номер_студента
FROM
(SELECT номер_студента, номер_дисциплины
FROM студенты
INNER JOIN группы
USING (номер_группы)
INNER JOIN учебные_планы
USING (код_специальности)
MINUS
SELECT номер_студента, номер_дисциплины
FROM успеваемость
WHERE оценка=5)
MINUS
SELECT номер_студента
FROM успеваемость t1
WHERE номер_дисциплины IN
(SELECT номер_дисциплины
FROM студенты
INNER JOIN группы
USING (номер_группы)
INNER JOIN учебные_планы
USING (код_специальности)
WHERE номер_студента=t1.номер_студента) AND оценка<5)),
hor AS
(SELECT номер_студента, 'хорошист' "SM"
FROM
(SELECT DISTINCT номер_студента
FROM успеваемость
MINUS
SELECT номер_студента
FROM
(SELECT номер_студента, номер_дисциплины
FROM студенты
INNER JOIN группы
USING (номер_группы)
INNER JOIN учебные_планы
USING (код_специальности)
MINUS
SELECT номер_студента, номер_дисциплины
FROM успеваемость
WHERE оценка>=4)
MINUS
SELECT номер_студента
FROM успеваемость t1
WHERE номер_дисциплины IN
(SELECT номер_дисциплины
FROM студенты
INNER JOIN группы
USING (номер_группы)
INNER JOIN учебные_планы
USING (код_специальности)
WHERE номер_студента=t1.номер_студента)
AND оценка<4
MINUS
SELECT номер_студента
FROM otl)),
groups_otl AS
(SELECT студенты.фамилия Фамилия, студенты.номер_группы Группа, sp.название_специальности Специальность, otl.SM "Отличник/Хорошист"
FROM otl
LEFT JOIN студенты
ON (otl.номер_студента=студенты.номер_студента)
LEFT JOIN группы gr
ON студенты.номер_группы=gr.номер_группы
LEFT JOIN специальности sp
ON gr.код_специальности=sp.код_специальности),
groups_hor AS
(SELECT студенты.фамилия Фамилия, студенты.номер_группы Группа, sp.название_специальности Специальность, hor.SM "Отличник/Хорошист"
FROM hor
LEFT JOIN студенты
ON (hor.номер_студента=студенты.номер_студента)
LEFT JOIN группы gr
ON студенты.номер_группы=gr.номер_группы
LEFT JOIN специальности sp
ON gr.код_специальности=sp.код_специальности)
SELECT Фамилия, Группа, Специальность, "Отличник/Хорошист"
FROM groups_otl
UNION ALL
SELECT *
FROM groups_hor
WHERE Группа NOT IN
(SELECT DISTINCT Группа
FROM groups_otl)
ORDER BY Группа
Результат:
ФАМИЛИЯ ГРУППА СПЕЦИАЛЬНОСТЬ Отличник/Хорошист
--------------- --------------- ---------------------------------------- -----------------
Старова 121 СИСТЕМЫ АВТОМАТИЧЕСКОГО отличник
УПРАВЛЕНИЯ
Комментарий:
C помощью временных представлений находим номера студентов, которые являются отличниками и хорошистами. Отличники: выбираем номера студентов и помечаем как «отличник» из временной таблицы отличников (В подзапросе сначала выбираем всех студентов, затем из них выкидываем тех, что учатся не на 5 по своему учебному плану). Из того, что получилось убираем тех, кто не круглый отличник по специальности. Для хорошистов делаем так же, но из них убираем всех отличников (отличник не является хорошистом).
Временные представления групп отличников и групп хорошистов нужны для получения информации о студенте (группа, специальность). В главном запросе выбираем всю информацию из временного представления groups_otl об отличниках и из информации о хорошистах groups_hor, объединяем выборки в одну, сортируем вывод информации по группе.
15. Создать запрос для определения сотрудников, которые имеют перерыв в стаже работы в фирме (Таблицы Employees и Job_History).
SELECT e.employee_id
FROM employees e JOIN
(SELECT DISTINCT first_value(start_date) OVER (PARTITION BY employee_id ORDER BY employee_id, start_date) st, employee_id
FROM job_history) t
ON t.employee_id = e.employee_id
WHERE e.hire_date!= t.st
UNION
SELECT employee_id
FROM job_history j1
HAVING (MAX(end_date)-MIN(start_date)+1)!=(SELECT SUM(end_date-start_date+1)
FROM job_history j2
WHERE j1.employee_id=j2.employee_id)
GROUP BY employee_id
Результат:
EMPLOYEE_ID
-----------
Комментарий:
Выбираем всех сотрудников, чьи номера присутствуют в таблице job_history и соединяем по номеру сотрудника с таблицей employees с условием равенство даты найма и даты начала работы. Объединем по номеру сотрудника с результатом вычисления MAX(end_date)-MIN(start_date)+1)!=(SELECT SUM(end_date-start_date+1 (Если у сотрудника был перерыв в стаже, то разница между последней датой окончания и первой датой начала работы не будет совпадать с суммой промежутков работы.)
16. Создать запрос для вывода информации о студентах, у которых интервал между датами сдачи экзаменов составляет менее трех дней. Информацию вывести в виде:
| Фамилия | Дисциплина 1 | Дата сдачи1 | Дисциплина 2 | Дата сдачи 2 |
| Поляков | Математика | 15.04.1998 | Физика | 17.04.1998 |
SELECT distinct с1.фамилия "Фамилия", д1.название "Дисциплина1", у1.дата "Дата сдачи 1", д2.название "Дисциплина2", у2.дата "Дата сдачи 2"
FROM успеваемость у1
JOIN успеваемость у2
ON у1.номер_студента=у2.номер_студента
JOIN студенты с1
ON у1.номер_студента = с1.номер_студента
JOIN дисциплины д1
ON у1.номер_дисциплины = д1.номер_дисциплины
JOIN дисциплины д2
ON у2.номер_дисциплины = д2.номер_дисциплины
WHERE (у2.дата - у1.дата)>=0 AND (у2.дата - у1.дата)<3 AND д2.название!= д1.название
Результат:
Фамилия Дисциплина1 Дата сдачи 1 Дисциплина2 Дата сдачи 2
--------------- ------------------------------ ------------ ------------------------------ ------------
Поляков Физика 10.06.99 Математика 12.06.99
Старова Физика 10.06.99 Математика 12.06.99
Комментарий:
Выбираем нужные в итоговом выводе столбцы. Первым соединением соединяем таблицу успеваемости саму с собой, чтобы определить все интервалы между экзаменами. Вторым соединением получаем фамилию студента. Третьим левым соединяем со списком дисциплин (определяем дисциплину 1).
Четвертым правым соединяем со списком дисциплин (определяем дисциплину 2). В разделе WHERE фильтруем половину экзаменов (т.к. экзамены дублируются) и проверяем на соответствие интервалу менее трех дней в отобранном списке экзаменов.
17. Создать запрос для определения списка студентов, сдавших экзамены по дисциплинам, не предусмотренным учебным планом специальности, на которой учатся студенты.
WITH stud AS
(SELECT DISTINCT ст.Фамилия last_name, спец.код_специальности job_id, усп.номер_дисциплины d_number
FROM СТУДЕНТЫ ст
JOIN ГРУППЫ гр
ON ст.номер_группы = гр.номер_группы
JOIN СПЕЦИАЛЬНОСТИ спец
ON гр.код_специальности = спец.код_специальности
JOIN УСПЕВАЕМОСТЬ усп
ON ст.номер_студента=усп.номер_студента)
SELECT DISTINCT last_name AS "Студент"
FROM stud t1
WHERE d_number NOT IN
(SELECT номер_дисциплины
FROM учебные_планы
WHERE код_специальности=t1.job_id)
Результат:
Студент
---------------
Гриценко
Комментарий:
Соединяем таблицы так же, как в задании 16, но сейчас получаем: имя, номер специальности, номер дисциплины (у каждого студента столько строк, сколько дисциплин.)
Главный запрос проверяет номер специальности на несуществование в данных подзапроса (который находит все номера дисциплин для данного кода специальности, который поставляется из главного запроса). Т.к. дисциплин может быть несколько, то и на вывод может попасть несколько одинаковых студентов – для вывода уникальной записи использем Distinct.
18. Получить информацию о работе кафедр в виде:
| Кафедра 1 | Кафедра 2 | Итого | |
| Количество преподавателей | |||
| Суммарный оклад | |||
| Средний оклад |
SELECT 'Количество преподавателей' " ",
sum
(CASE кафедра
WHEN 'Кафедра 1' THEN 1
ELSE 0 END) AS "Кафедра 1",
sum
(CASE кафедра
WHEN 'Кафедра 2' THEN 1
ELSE 0 END) AS "Кафедра 2",
sum (1) AS "Итого"
FROM преподаватели
UNION ALL
SELECT 'Суммарный оклад',
sum
(CASE кафедра WHEN 'Кафедра 1' THEN зарплата
ELSE 0 END),
sum
(CASE кафедра WHEN 'Кафедра 2' THEN зарплата
ELSE 0 END),
sum (зарплата) AS "Итого"
FROM преподаватели
UNION ALL
SELECT 'Средний оклад',
(SELECT avg(зарплата)
FROM преподаватели
WHERE кафедра='Кафедра 1'),
(SELECT avg(зарплата)
FROM преподаватели
WHERE кафедра='Кафедра 2'),
(SELECT avg(зарплата)
FROM преподаватели)
FROM dual
Результат:
Кафедра 1 Кафедра 2 Итого
------------------------- --------- --------- -----
Количество преподавателей 4 5 9
Суммарный оклад 10500 12000 22500
Средний оклад 2625 2400 2500
Комментарий:
Первые два select`a основываются на переводе столбца в строку с помощью case (Если данные относятся к выбираемым в данной строке – суммируем).
Третий блок select состоит из независимых подзапросов, каждый из которых считает свою ячейку.
19. Имеется таблица с колонкой, которая содержит множество значений, разделенных запятыми. Требуется создать запрос, который каждое значение выведет на отдельной строке. Например, дана таблица:
| Номер | Телефон |
| 2-78,2-89 | |
| 2-78,2-83,8-34 |
Результат:
| Номер | Телефон |
| 2-78 | |
| 2-89 | |
| 2-78 | |
| 2-83 | |
| 8-34 |
Создаём таблицу и заполняем её:
CREATE TABLE num_t (номер VARCHAR2(25), телефон VARCHAR2(25));
INSERT INTO num_t VALUES (952240,'2-78,2-89');
INSERT INTO num_t VALUES (952423,'2-78,2-83,8-34');
desc num_t
Name Null Type
------- ---- ------------
НОМЕР VARCHAR2(25)
ТЕЛЕФОН VARCHAR2(25)
SELECT decode(lvl, 1, Номер) Номер, Телефон
FROM
(SELECT distinct Номер, level lvl, regexp_substr(Телефон,'[^,]+',1,level) Телефон
FROM num_t
CONNECT BY regexp_count(Телефон, '[^,]+') >= level
ORDER BY Номер, Телефон)
Комментарий:
Разбиваем данные второго столбца таблицы на части, отделенные запятыми, а затем их последовательно извлекаем по порядку до тех пор, пока количество шагов не станет больше количества групп символов.
Повторяем эти действия для каждого номера, после чего в случае, когда шаг извлечения данных первый, пишем значение номера, иначе - оставляем поле номера пустым.
20. Задана таблица
| A | COL1 |
Требуется сгруппировать значения по группам так, чтобы сумма в группе не превышала заданное число (100).
| A | COL1 | GRP |
Создаём таблицу и заполняем её:
CREATE TABLE col1 (A NUMBER(8), COL1 NUMBER(8));
INSERT INTO col1 VALUES (1,10);
INSERT INTO col1 VALUES (2,90);
INSERT INTO col1 VALUES (3,1);
INSERT INTO col1 VALUES (4,5);
INSERT INTO col1 VALUES (5,5);
INSERT INTO col1 VALUES (6,50);
INSERT INTO col1 VALUES (7,99);
INSERT INTO col1 VALUES (8,2);
INSERT INTO col1 VALUES (9,0);
INSERT INTO col1 VALUES (10,50);
Name Null Type
---- ---- ---------
A NUMBER(8)
COL1 NUMBER(8)
SELECT A, Col1,GRP, Total
FROM col1
MODEL
DIMENSION BY(row_number() OVER(ORDER BY A) rn)
MEASURES(A,COL1,COL1 total,1 GRP)
RULES(total[rn > 1] ORDER BY A = CASE
WHEN total[cv() - 1] + COL1[cv()] <= 100 THEN total[cv() - 1] + COL1[cv()]
ELSE COL1[cv()] END,
GRP[rn > 1] ORDER BY A = CASE
WHEN total[cv() - 1] + COL1[cv()] <= 100 THEN GRP[cv() - 1]
ELSE GRP[cv()-1] +1 END)
ORDER BY rn
Результат:
A COL1 GRP TOTAL
- ---- --- -----
1 10 1 10
2 90 1 100
3 1 2 1
4 5 2 6
5 5 2 11
6 50 2 61
7 99 3 99
8 2 4 2
9 0 4 2
10 50 4 52
10 rows selected
Комментарий:
Решаем с помощью model. В столбце Total храним текущие суммы, если они не превышают 100. Если сумма Total и текущего значения больше или равна 100 - группируем также как и в прошлый раз, а если нет то добавляем единицу.
ВАРИАНТ 7
(Базы данных Студент и Human Resources)
1. Создать запрос для вывода 3 дисциплин, по которым на сессии было получено максимальное количество пятерок. Если по каким-то дисциплинам получено такое же количество пятерок, как и по дисциплине с наименьшим количеством пятерок из первой тройки, то она тоже должна попасть в список. Задачу решить с использованием аналитических функций.
select НАЗВАНИЕ as "Предмет", mark AS "Кол-во пятерок"
from (select d.НАЗВАНИЕ, count(u.ОЦЕНКА) mark,
RANK() over (order by count(u.ОЦЕНКА) desc) rank
from ДИСЦИПЛИНЫ d join УСПЕВАЕМОСТЬ u on d.НОМЕР_ДИСЦИПЛИНЫ = u.НОМЕР_ДИСЦИПЛИНЫ
where u.ОЦЕНКА = 5
group by d.НАЗВАНИЕ)
where rank < 4
order by mark desc;

Комментарий:
Соединяем таблицы «дисциплины» и «успеваемость», чтобы узнать по каким предметам были получены пятерки, далее считаем кол-во этих пятерок и ранжируем по этому количетсву. И выводим только те предметы ранг которых меньше 4х.
При использовании простого (неплотного) ранжирования мы можем получить ранг 4 для дисциплин из первой тройки (если, допустим, на первом месте будет две дисциплины с одинаковым количеством пятёрок).
+ не забудьте учесть, что должны быть выведены все дисциплины только с наименьшим количеством пятёрок (а с самым большим и средним – по одной дисциплине).
2. Есть таблица, в которой значения в двух столбцах Obj1 и Obj2 определяют номера объектов, между которыми имеется связь. Один объект может быть связан с несколькими, те в свою очередь могут быть связаны друг с другом. В результате, значения образуют связанные множества. На входе имеем номер некоторого объекта, нужно получить все элементы множества, к которому оно относится.
with t0 as (
select 1 value1, 2 value2 from dual
union all
select 2, 3 from dual
union all
select 2, 4 from dual
union all
select 8, 6 from dual
union all
select 5, 6 from dual
),
t as (
select value1, value2 from t0
union
select value2, value1 from t0
)
select distinct value1
from t
connect by nocycle
prior value1 = value2
start with value1 = &s;
результат = 1 2 3 4
Комментарий:
t0 имитирует исходную таблицу, создаем иерархический запрос, который проходит по связанным элементам и строит из них дерево, и по определении конца множества (попадание в бесконечный цикл) завершаем работу запроса. NOCYCLE – позволяет в запросе с предложением CONNECT BY распознать, что встретился бесконечный цикл и прекратить выполнение запроса без выдачи ошибки (вместо возврата ошибки зацикливания при выполнении предложения CONNECT BY)
3. Имеется таблица с тремя столбцами: именем, фамилией и коэффициентом, показывающим сколько раз должна повторяться запись. Требуется написать запрос, выводящий таблицу, содержащую строки с именами и фамилиями сотрудников. Число строк для каждого сотрудника должно определяться значением коэффициента. То есть, если Иван Петров имел коэффициент 3, а Сергей Сидоров – коэффициент 5, то в результатах запроса должны быть 3 строки для сотрудника Петрова и 5 строк для Сидорова.
Строки должны быть объединены в группы и отсортированы по фамилии и имени. Кроме того, должны быть пронумерованы элементы внутри группы и должна присутствовать сквозная нумерация. Этот запрос должен работать для произвольного количества строк в исходной таблице.
Пример выходного отчёта:
| Сквозной № | № в группе | Имя | Фамилия |
| Иван | Петров | ||
| Иван | Петров | ||
| Иван | Петров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров |
select rownum as "Сквозной номер", grNum as "№ в группе", Имя, фамилия
from (select level grNum, t1.Имя, t1.Фамилия
from t t1 join t t2 on t1.имя!= t2.имя
connect by level < t1.Коэф + 1
and prior t1.Коэф = t1.Коэф
and prior dbms_random.value is not null
order by Имя, Фамилия, level);

Комментарий:
Используя рекурсивный запрос, генерируем последовательность из заданного количества записей (коэффициент) для каждой записи в нашей таблице. С помощью rownum организовываем сквозную нумерацию, а с помощью distinct level – нумерацию в группе.
В принципе, конечно, работать будет. Но попробуйте протестировать, например на таких данных:
with t as(
select 'Иван' имя, 'Петров' фамилия, 10 коэф from dual union all
select 'Сергей' имя, 'Сидоров' фамилия, 12 коэф from dual union all
select 'Александр' Имя, 'Сергеев' Фамилия, 14 коэф from dual)
И Вы уже будете в 9 раз дольше ждать ответа – из-за размножения строк при построении дерева (бОльшие коэффициенты даже не предлагаю задавать – ответа можно совсем не дождаться).
Т.е. задачу зачту и в этом виде после исправления сортировки, но если Вы придумаете вариант лучше – будет здорово.
4. Создать запрос для вывода всех дат из заданного диапазона, отсутствующих в датах приема на работу преподавателей. Даты начала и окончания диапазона задаются параметрически.
undefine d1
undefine d2
with d as
(select dates
from(select TRUNC(s + x) dates
from (select level x, to_date('&&d1','DD-MM-YYYY')-1 s from dual connect by level <= to_date('&&d2','DD-MM-YYYY') + 1 - to_date('&d1','DD-MM-YYYY')))
order by dates)
select * from d
minus
select distinct dates
from d inner join преподаватели п
on d.dates = п.дата_контракта and п.дата_контракта < to_date('&d2','DD-MM-YYYY')
and п.дата_контракта > to_date('&d1','DD-MM-YYYY');

результаты для диапазона от 25.04.79 до 15.05.79 (даты найма в этом диапазоне: 01.05.79 и 10.05.79)
Комментарий:
Создаем табличку состоящая и диапазона дат, границы которого мы задаем, затем вычитаем из всего кол-ва дат, те даты, которые являются датами найма сотрудников и попадают в заданный диапазон. Обе границы входят в диапазон
5. Создать запрос, позволяющий выводить информацию о студентах и преподавателях (Фамилия с инициалами, Зарплата/Стипендия, Статус – преподаватель или студент).
select to_char(ФАМИЛИЯ || ' ' ||substr(ИМЯ,1,1) || '. ' || substr(ОТЧЕСТВО,1,1) || '. ') as "Имя", ЗАРПЛАТА as "З.П./СТИПЕНДИЯ", to_char ('Преподаватель') as "Статус"
from ПРЕПОДАВАТЕЛИ
union all
select to_char(ФАМИЛИЯ || ' ' ||substr(ИМЯ,1,1) || '. ' || substr(ОТЧЕСТВО,1,1) || '. ') as "Имя", СТИПЕНДИЯ, to_char ('Студент')as "Статус"
from СТУДЕНТЫ;
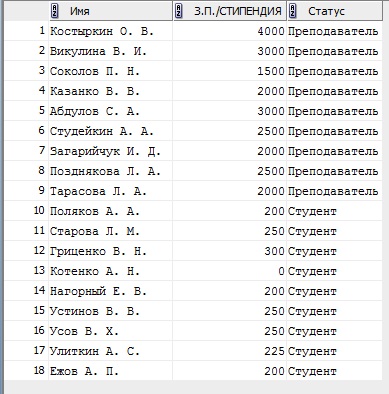
Комментарий:
Объединяем содержимое столбца «фамилия» с первой буквой имени и отчества из соответствующих столбоц, выводим з.п. и статус для преподавателей, далее объединяем с таким же селектом только для студентов.
6. Получить информацию о подчиненности таблиц в схеме в виде:
ИмяТаблицы1(ИмяFK1 ссылается на ИмяТаблицы2/ИмяPK2)
ИмяТаблицы2(ИмяFK2 ссылается на ИмяТаблицы3/ИмяPK3) ……
select distinct uc.table_name || '(' || uc.constraint_name || ' cсылается на ' || a.table_name || '/' || uc.r_constraint_name || ')' as "Table info"
from user_constraints uc join user_cons_columns ucc
on uc.constraint_name = ucc.constraint_name
join user_constraints a
on a.constraint_name = uc.r_constraint_name
join user_cons_columns b on a.constraint_name = b.constraint_name
where uc.constraint_type like 'R' and ucc.position = b.position;

Комментарий:
Узнаем для каждой таблицы поля в которых содержится внешний ключ и его имя, далее находим на какой первичный ключ ссылается наш внешний и находим какое поле содержит этот ключ и таблицу, в котором находится это поле
7. Создать представление, которое выводит фамилию студента, оценку, дату сдачи экзамена и название предмета. Оценка должна выводиться в формате: отл, хор, удовл или неудовл. Для студентов, не сдававших экзамен, должно выводиться – Не сдавал – в столбцах Оценка, Дата сдачи экзамена и Название предмета.
create view stud_progress as
select distinct s.ФАМИЛИЯ, decode(u.оценка, null,'Не сдавал', 5, 'отл', 4, 'хор', 3, 'удвл', 2,'неудовл') as "Оценка",
decode(u.дата, null,'Не сдавал', u.дата) as "Дата сдачи",
decode (d.название, null,'Не сдавал', d.название) as "Название"
from студенты s left join успеваемость u on s.номер_студента = u.номер_студента
left join дисциплины d on d.номер_дисциплины = u.номер_дисциплины
order by s.ФАМИЛИЯ;

Комментарий:
Объединяем таблицы «студенты», «успеваемость» и «дисциплины» для того, чтобы узнать какие дисциплины, и на какую оценку сдавали студенты. Если студенты не сдавали экзамены то, с помощью функции decode мы заменяем пустые поля на «Не сдавал».
8. Создать запрос для получения списка дисциплин, которые изучаются на всех специальностях.
select distinct НАЗВАНИЕ as "Предмет"
from дисциплины d join УЧЕБНЫЕ_ПЛАНЫ up1 on d.номер_дисциплины = up1.номер_дисциплины
join УЧЕБНЫЕ_ПЛАНЫ up2 on up1.номер_дисциплины = up2.номер_дисциплины
where up1.код_специальности!= up2.код_специальности;
Предмет
------------------------------
Математика
Комментарий:
С помощью объединения таблицы «учебные_планы» c таблицей «дисциплины» узнаем какие дисциплины изучаются на разных специальностях и далее объединяем с таблицей «дисциплины», чтобы узнать название этих дисциплин.
9. Создать запрос, который выводит фамилию студента, стипендию и процент, который составляет его стипендия от суммарной стипендии студентов, обучающихся в той же группе. Задачу решить при помощи использования аналитических функций.
select a.ФАМИЛИЯ, a.СТИПЕНДИЯ, round(RATIO_TO_REPORT(a.СТИПЕНДИЯ) OVER (partition by a.НОМЕР_ГРУППЫ),2) AS "Доля", a.НОМЕР_ГРУППЫ
from СТУДЕНТЫ a
join СТУДЕНТЫ b
on a.НОМЕР_ГРУППЫ = b.НОМЕР_ГРУППЫ
group by a.НОМЕР_ГРУППЫ, a.ФАМИЛИЯ, a.СТИПЕНДИЯ
order by a.НОМЕР_ГРУППЫ

Комментарий:
С помощью объединения таблицы «студенты» с самой собой по номеру группы узнаем процентную долю стипендии студента относительно суммарной стипендии в группе
10. Создать запрос для получения информации о количестве полученных студентами пятерок, четверок, троек и двоек. Результат запроса должен быть представлен в виде:
| Фамилия | Кол-во 5 | Кол-во 4 | Кол-во 3 | Кол-во 2 | Итого |
| Поляков | |||||
| Старова | |||||
| Нагорный | |||||
| Итого: |
Дата добавления: 2015-08-18; просмотров: 161 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Main_Table PK User_Constraints 4 страница | | | Main_Table PK User_Constraints 6 страница |