|
Читайте также: |
with tab
as(
select s.ФАМИЛИЯ,
count(decode(u.оценка, 5, s.номер_студента)) as Кол_во5,
count(decode(u.оценка, 4, s.номер_студента)) as Кол_во4,
count(decode(u.оценка, 3, s.номер_студента)) as Кол_во3,
count(decode(u.оценка, 2, s.номер_студента)) as Кол_во2,
count(оценка) as Итого
from студенты s left join (select distinct u1.номер, u1.оценка, u1.дата, u1.номер_студента, u1.номер_дисциплины
from успеваемость u1 join успеваемость u2
on u1.номер_студента = u2.номер_студента and u1.номер_дисциплины = u2.номер_дисциплины
minus
select distinct u1.номер, u1.оценка, u1.дата, u1.номер_студента, u1.номер_дисциплины
from успеваемость u1 join успеваемость u2
on u1.номер_студента = u2.номер_студента and u1.номер_дисциплины = u2.номер_дисциплины
where u1.оценка!= u2.оценка
union
select u1.номер, u1.оценка, u1.дата, u1.номер_студента, u1.номер_дисциплины
from успеваемость u1 join успеваемость u2
on u1.номер_дисциплины = u2.номер_дисциплины and u1.номер_студента = u2.номер_студента and u1.оценка!= u2.оценка and u1.дата > u2.дата) u
on s.номер_студента = u.номер_студента
group by s.ФАМИЛИЯ)
select * from tab
union all
select 'Итого', sum(Кол_во5), sum(Кол_во4), sum(Кол_во3), sum(Кол_во2), sum(Итого)
from tab
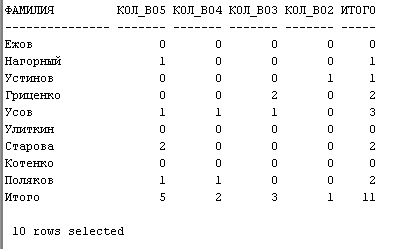
Комментарий:
Для каждого студента поочередно подсчитываем количество опеределенных оценок с помощью функций count и decode, для чего объединяем таблицы «студенты» и «успеваемость». Далее объединяем нашу получившуюся таблицу с «итоговым» селектом, в котором находятся суммы по наим найденым столбцам с оценками.
Наверняка есть более просто способ учета последней даты сдачи экзамена, но я его не нашел. Я добавил запись 1021 в таблицу успеваемость (для удобства),

в которой студент Гриценко переписал один экзамен, по которому получил 2 на 3. Для получения той таблицы успеваемости, которая нам нужна (одна запись для одного студента по рассматриваемой дисциплине) я сделал следующее:
- убрал из таблицы успеваемость все записи, где для одного студента стоит несколько оценок за 1 экзамен
- выделил те записи, которые содержат данные о последней оценке за экзамен (если оценок было больше 1)
- объединил п.1 и п.2. В итоге получили желаемую таблицу (с учетом добавления еще 1 записи).
11. Создать запрос для получения информации о кафедрах в виде:
| Кол-во сотрудников | Средняя зарплата | Максимальная зарплата | |
| Кафедра1 | |||
| Кафедра2 | |||
| В целом: |
select distinct кафедра as " ",
count(*)OVER(PARTITION BY кафедра) as "Кол-во сотрудников",
avg(зарплата) OVER(PARTITION BY кафедра) as "Средняя з.п.",
min(зарплата)OVER(PARTITION BY кафедра) as "Минимальная з.п."
from ПРЕПОДАВАТЕЛИ
UNION all
SELECT 'В целом:', COUNT(*), AVG(зарплата), Min(зарплата)
FROM преподаватели;

Комментарий:
Находим количество преподавателей, среднюю и минимальную з.п. для каждой кафедры и объединяем с селектом, в котором общее кол-во преподавателей, общая средняя и минимальная з.п. по всем преподавателям.
12. Определить отделы, в которых суммарная зарплата сотрудников выше средней суммарной зарплаты по отделам, расположенным в том же городе. Вывести информацию о наименовании отдела, суммарной заработной плате отдела и средней заработной плате города, где расположен отдел.
select d.department_name, sumSal as "Сумма по отделу", avgSum "Средняя по городу"
from (select e.department_id, sum(salary) as sumSal,
(select avg(SUM(salary)) as avgSum
from employees
WHERE DEPARTMENT_ID in
(select department_id from departments d2 where
d2.location_id in (select d3.location_id
from departments d3 inner join locations l3 on d3.location_id = l3.location_id
where d3.department_id = e.department_id))
group by department_id) as avgSum
from employees E
group by e.department_id) t join departments d on t.department_id = d.department_id
having sumSal > avgSum
group by d.department_name,sumSal,avgSum;

Комментарий:
В подзапросах вычисляем департаменты, которые находятся в одном городе и, соответственно, находим среднюю суммарную зарплату по этим отделам и суммарную зарплату по отделу.
13. Создать запрос для вывода информации о студентах, у которых интервал между датами сдачи экзаменов составляет менее трех дней. Информацию вывести в виде:
| Фамилия | Дисциплина 1 | Дата сдачи1 | Дисциплина 2 | Дата сдачи 2 |
select с.фамилия "Фамилия", д1.название "Дисциплина1", у1.дата "Дата сдачи 1",
д2.название "Дисциплина2", у2.дата "Дата сдачи 2"
from студенты с join успеваемость у1
on с.номер_студента = у1.номер_студента
join успеваемость у2 on у1.номер_студента=у2.номер_студента
join дисциплины д1 on у1.номер_дисциплины = д1.номер_дисциплины
join дисциплины д2 on у2.номер_дисциплины = д2.номер_дисциплины
where (у2.дата - у1.дата)>0 and (у2.дата - у1.дата)<3;
where (у2.дата - у1.дата)>= 0 and (у2.дата - у1.дата)<3 and у2.дата!= у1.дата

Комментарий:
Объединяя таблицы «дисциплины» и «успеваемость» сами с собой по номерам дисциплины и по номерам студентов соответственно и задавая условие на разность дат, получаем те дисциплины и даты, которые соответствуют нашему условию.
14. Вывести сведения о сотрудниках, которые подчиняются тем же непосредственным руководителям, что и сотрудники Rajs или Abel, работают в тех же подразделениях компании, что и указанные сотрудники.
Требуется вывести: Фамилию сотрудника, Название должности сотрудника, Фамилию непосредственного руководителя сотрудника, Название подразделения компании, где работает сотрудник. Сведения о сотрудниках Rajs и Abel выводить не нужно
Сведения должны быть отсортированы по возрастанию: по названию подразделения компании, где работает сотрудник; по фамилии сотрудника.
SELECT t.last_name, jobs.job_title, e.last_name manager, d.department_name
FROM
(select last_name,, job_id, manager_id, department_id
from employees
where (manager_id, department_id) in
(select manager_id, department_id
from employees
where last_name in ('Rajs', 'Abel'))
and last_name not in ('Rajs', 'Abel'))t
INNER JOIN employees e
ON t.manager_id = e.employee_id
INNER JOIN jobs
ON jobs.job_id = t.job_id
INNER JOIN departments d
ON d.department_id = t.department_id
ORDER BY d.department_name, t.last_name;
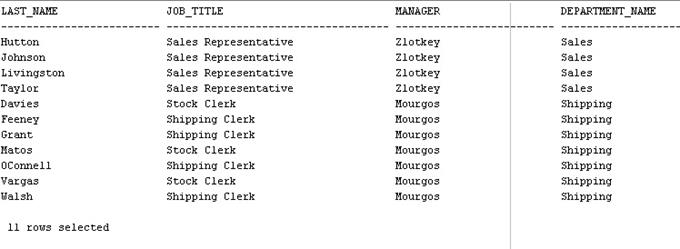
Комментарий:
В подзапросах находим сотрудников:
- у которых начальники такие же как у Rajs или Abel;
- которые работают в тех же отделах, что и Rajs или Abel и указываем, что записи о Rajs и Abel нам в таблице не нужны. Далее получившуюся таблицу объединяем с таблицами «employees», «jobs» и «departments» для нахождения фамилий, должностей и названий подразделений соответственно.
15. Из произвольной символьной строки удалить лишние пробелы между словами, оставив только по одному. Задачу решить при помощи раздела Model без использования регулярных выражений.
WITH y as
(SELECT x, rownum rn
FROM (select distinct x
from (select '&x' x from dual)
model
dimension by (0 d)
measures (x)
rules iterate (1000) UNTIL (iteration_number=length(x[0])) (x[iteration_number+1] = replace(x[iteration_number], ' ', ' '))))
SELECT x
FROM y
WHERE rn = (SELECT max(rn) FROM y);
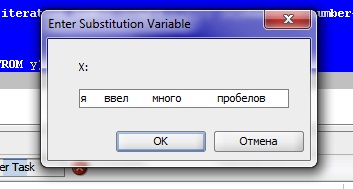
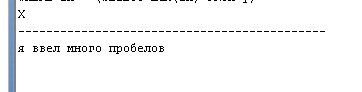
Комментарий:
Сначала задаем исходную строку, затем в разделе RULES организуем цикл, для которого задаем количество итераций ITERATE (1000). При это в каждой итерации цикла новая строка получается из предыдущей путем замены двойного пробела на одиночный. Так, мы в конце концов получим строчку только с одиночными пробелами, которая будет самой последней после выполнения цикла. Присвоив каждой строке свой номер с помощью ROWNUM, и выдернув затем строку с самым большим номером, мы и найдем искомую.
16. Показать в одном отчете для каждого отдела: его номер, наименование, количество работающих сотрудников, средний оклад вместе со следующими данными по каждому сотруднику – фамилия, оклад и должность.
| Номер отдела | Название отдела | Количество сотрудников | Средний оклад | Фамилия | Оклад | Должность |
| Purchasing | ||||||
| Khoo | Purchasing Clerk | |||||
| Baida | Purchasing Clerk | |||||
| Tobias | Purchasing Clerk | |||||
| Himuro | Purchasing Clerk | |||||
| Colmenares | Purchasing Clerk | |||||
| Human Resources | ||||||
| Mavris | Human Resources Representative | |||||
| Shipping | 3475,56 | |||||
| Weiss | Stock Manager | |||||
| Fripp | Stock Manager | |||||
| Kaufling | Stock Manager | |||||
| … | …… | …… | ……. |
SELECT
DECODE(ddept_id, NULL, ' ', ddept_id) AS "Номер отдела",
DECODE(dept_name, NULL, ' ', dept_name) AS "Название отдела",
DECODE(col, NULL, ' ', col) AS "Количество сотрудников",
DECODE(ROUND(avgsal,2), NULL, ' ', ROUND(avgsal,2)) AS "Средний оклад",
DECODE(last_name, NULL, ' ', last_name) AS "Фамилия",
DECODE(salary, NULL, ' ', salary) AS "Оклад",
DECODE(jt, NULL, ' ', jt) AS "Должность"
FROM (SELECT ddept_id, dept_name, col, avgsal, last_name, salary, jt, edept_id
FROM (SELECT d.department_id AS ddept_id, d.department_name AS dept_name,
COUNT(e.employee_id) OVER (PARTITION BY d.department_id) AS col,
AVG(e.salary) OVER (PARTITION BY d.department_id) AS avgsal, e.last_name AS last_name,
e.department_id AS edept_id, e.salary AS salary, j.job_title AS jt
FROM employees e JOIN departments d ON e.department_id = d.department_id
JOIN jobs j ON e.job_id = j.job_id)
GROUP BY GROUPING SETS ((ddept_id, dept_name, col, avgsal),(last_name, salary, jt, edept_id))
ORDER BY ddept_id, edept_id)
ORDER BY
(CASE WHEN ddept_id IS NOT NULL
THEN ddept_id
ELSE edept_id END), ddept_id;
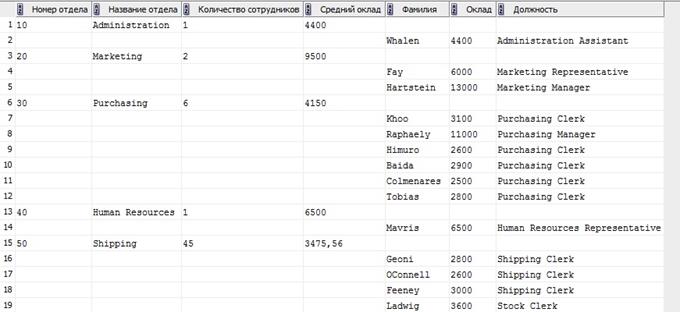
Комментарий:
В самом вложенном подзапросе соединяем таблицы Employees и Departments и, применяя аналитические функции, получаем необходимую нам информацию. Выборку группируем по отделам. В следующем селекте, данные для которого выбираем из только что полученной информации, используем наборы группировок GROUPING SETS, чтобы группировать данные по определенным группам. После этого применяем функции DECODE для различных столбцов, чтобы задать им то, что они должны выводить при определенных значениях. Ну и напоследок задаем сортировку с помощью ORDER BY по номеру отдела.
17. В произвольной строке, состоящей из символьных элементов, разделенных запятыми, отсортировать элементы по алфавиту. Например, символьную строку
abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe
преобразовать к виду:
abc,cde,df,ef,ewe, fw,gh,mn,ss,test,wwe.
SELECT wm_concat(my_string) AS "Result"
FROM (SELECT regexp_substr('abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe', '[a-z]+', 1, level) my_string
FROM dual
CONNECT BY regexp_substr('abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe', '[a-z]+', 1, level) IS NOT NULL
ORDER BY my_string);
Другой вариант:
SELECT MAX(LTRIM(SYS_CONNECT_BY_PATH(str, ','),',')) AS "Res"
FROM (SELECT str, ROW_NUMBER() OVER (ORDER BY str) rn
FROM (SELECT regexp_substr('abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe','[a-z]+',1,level) str
FROM dual
CONNECT BY regexp_substr('abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe','[a-z]+',1,level) IS NOT NULL
ORDER BY 1))
START WITH rn = 1
CONNECT BY PRIOR rn = rn-1;
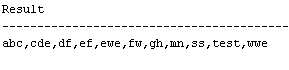
Комментарий:
Во внутреннем запросе применяем регулярное выражение regexp_substr и цикл.
Каждая итерация цикла- это нахождение очередной подстроки до знака «,». Результат итераций будет записываться в столбик. С помощью ORDER BY отсортируем этот столбик, а затем командой sys_connect_by_path соберем уже отсортированный как надо столбик в одну строку.
18. Выделить в HTML разметке содержимое блоков с установленными атрибутами:
· тег <p> с CSS классом content
· тег <li> с CSS классом content
Например, для разметки:
<p>Абзац 1</p>
<p class="content">Абзац 2</p>
<ul>
<li>Элемент 1</li>
<li class="content">Элемент 2</li>
</ul>
Должно быть выделено:
<p class="content">Абзац 2</p>
<li class="content">Элемент 2</li>
WITH tab_tag
AS (SELECT '<p>Абзац 1</p>
<p class="content">Абзац 2</p>
<ul>
<li>Элемент 1</li>
<li class="content">Элемент 2</li>
</ul>
' tag
FROM dual)
SELECT LTRIM(subtag) AS "Результат"
FROM (SELECT regexp_substr(tag, '.*<p class="content">.*', 1, level) AS subtag
FROM tab_tag
CONNECT BY regexp_substr(tag, '.*<p class="content">.*', 1, level) IS NOT NULL
UNION ALL
SELECT regexp_substr(tag, '.*<li class="content">.*', 1, level) AS subtag
FROM tab_tag
CONNECT BY regexp_substr(tag, '.*<li class="content">.*', 1, level) IS NOT NULL);
Результат
------------------------------------------------
<p class="content">Абзац 2</p>
<li class="content">Элемент 2</li>
Комментарий:
Сначала просто выбираем введенный нами тэг из таблицы Dual и сохраняем его как tab_tag с помощью WITH. Во внутренних запросах применяем регулярные выражения regexp_substr для искомых частей <p class="content и li class="content, при этом указывая, что до и после них могут стоять любые символы. Затем из этих «подтэгов» (subtag) обрезаем лишние пробелы и выводим результат.
19. Создать запрос для получения списка городов и отделов, расположенных в них. Результаты представить в виде:
| Город | Отдел |
| Seattle | Accounting, Administration,Benefits, Construction,Control And Credit |
| Toronto | Marketing |
Список отделов в каждом городе должен быть отсортирован по алфавиту.
WITH tab AS
(SELECT t.*,
LAG (t.rn) OVER (PARTITION BY t.location_id ORDER BY t.rn) prev
FROM(SELECT d.location_id, l.city,d.department_name,
ROW_NUMBER () OVER (PARTITION BY l.city ORDER BY d.department_name) rn
FROM departments d INNER JOIN locations l
ON d.location_id=l.location_id
ORDER BY 2,3) t)
SELECT city город, max(dept) отделы
FROM (SELECT city, rn, LTRIM(sys_connect_by_path(department_name, ', '), ', ') As Dept
FROM tab
START WITH prev IS NULL
CONNECT BY PRIOR rn = prev AND PRIOR location_id = location_id)
GROUP BY city;

Комментарий:
В первом запросе соединяем таблицы Locations и Departments для получения информации о названиях городов и отделов, а также присваиваем им номера с помощью применения аналитической функции row_number. Командой WITH сохраняем полученные значения в tab. А затем к полученным данным применяем функцию sys_connect_by_path с условиями start with и connect by prior и получаем искомый результат.
20. Создать запрос для получения информации о количестве преподавателей, работающих на кафедрах в разных должностях. Результат запроса должен быть представлен в виде:
| Кафедра1 | Кафедра2 | Итого | |
| Профессор | |||
| Доцент | |||
| ……. | |||
| Итого: |
with
aux_tbl as(select distinct должность,
(select count(номер_преподавателя)
from преподаватели
where кафедра = 'Кафедра 1' and должность = п.должность) as "Кафедра 1",
(select count(номер_преподавателя)
from преподаватели
where кафедра = 'Кафедра 2' and должность = п.должность) as "Кафедра 2",
(select count(номер_преподавателя)
from преподаватели
where должность = п.должность) as "Итого:"
from преподаватели п
order by должность desc)
select *
from aux_tbl
union all
select 'Итого:', sum("Кафедра 1"), sum("Кафедра 2"), sum("Итого:")
from aux_tbl;

Комментарий:
Сначала для первой кафедры находим количество каждых должностей на этой кафедре, затем делаем то же самое для второй кафедры, затем четвертым столбиком выводим количество каждых должностей для обеих кафедр. Далее объединяем получившуюся таблицу с «итоговым» селектом.
ВАРИАНТ 8
(Базы данных Студент и Human Resources)
1. В таблицу Специальности добавить столбец Шифр Специальности. Написать и выполнить команду, позволяющую внести в этот столбец сокращенное наименование специальности, состоящее из первых букв каждого слова названия специальности.
ALTER TABLE СПЕЦИАЛЬНОСТИ ADD(шифр VARCHAR2(20));
MERGE INTO специальности sp1
USING (SELECT код_специальности, название_специальности,
replace(translate(initcap(название_специальности), 'йцукенгшщзхъфывапролджэячсмитьбю', '_'), '') as шифр
FROM специальности) sp2
ON (sp1.код_специальности = sp2.код_специальности)
WHEN MATCHED THEN
UPDATE SET sp1.шифр = sp2.шифр;
SELECT * FROM специальности;
Результат:
1 СИСТЕМЫ АВТОМАТИЧЕСКОГО УПРАВЛЕНИЯ
2 МАТЕМАТИЧЕСКОЕ ОБЕСПЕЧЕНИЕ ЭВМ
3 ВЫЧИСЛИТЕЛЬНЫЕ СЕТИ И СИСТЕМЫ
4 ЭКОНОМИКА ПРЕДПРИЯТИЙ
Комментарий:
С помощью команды MERGE INTO в пустой столбец «шифр» добавляем сокращенное наименование специальности.
С помощью команды initcap(название_специальности) делаем первые буквы слов в названии специальности заглавными.
С помощью команды translate(initcap(название_специальности),'йцукенгшщзхъэждлорпавыфячсмитьбю',' ') заменяем все строчные буквы на пробелы.
С помощью команды replace(translate(initcap(название_специальности),'йцукенгшщзхъэждлорпавыфячсмитьбю',' '),' ','') as шифр заменяем все пробелы на пустые значения.
2. Создать запрос для определения дат начала проведения Уимблдонского турнира в ближайшие сто лет, зная, что турнир начинается за шесть недель до последнего понедельника августа.
SELECT CASE
WHEN TO_CHAR(NEXT_DAY(LAST_DAY('1.08.'||TO_CHAR(TO_DATE(sysdate),'YYYY'))-7, 'ПОНЕДЕЛЬНИК')-42, 'dd.mm.yyyy') > TO_CHAR(sysdate, 'dd.mm.yyyy')
THEN TO_CHAR(NEXT_DAY(LAST_DAY('1.08.'||(TO_CHAR(TO_DATE(sysdate),'YYYY')+level))-7, 'ПОНЕДЕЛЬНИК')-42, 'dd.mm.yyyy')
ELSE TO_CHAR(NEXT_DAY(LAST_DAY('1.08.'||(TO_CHAR(TO_DATE(sysdate),'YYYY')+level-1))-7, 'ПОНЕДЕЛЬНИК')-42, 'dd.mm.yyyy')
END Даты
FROM DUAL
CONNECT BY level <= 100;
Результат:
Даты
16.07.2012
15.07.2013
14.07.2014
20.07.2015
18.07.2016
17.07.2017
16.07.2018
15.07.2019
20.07.2020
19.07.2021
18.07.2022
17.07.2023
15.07.2024
14.07.2025
20.07.2026
Комментарий:
С помощью команды '1.08.'||TO_CHAR(TO_DATE(sysdate),'YYYY') задаем 1 августа текущего года.
С помощью команды LAST_DAY('1.08.'||TO_CHAR(TO_DATE(sysdate),'YYYY'))-7 находим последний день недели и отнимаем 7 для получения понедельника.
С помощью команды NEXT_DAY(LAST_DAY('1.08.'||(TO_CHAR(TO_DATE(sysdate),'YYYY')+level))-7, 'ПОНЕДЕЛЬНИК')-42 находим последний понедельник августа и отнимаем от него 42 дня (т.е. 6 недель), чтобы узнать дату начала турнира.
С помощью CONNECT BY level <= 100 выводим результаты на ближайшие сто лет.
3. Создать внешнюю таблицу для чтения данных из текстового файла, содержащего информацию в виде:
Номер ФИО Дата Оценка Дисциплина
1 Петров С.С. 12-05-2008 4 Математика
2 Сомов Л.Л. 4-05-2008 5 Физика
3 Амосов Д.Г. 3-05-2008 4 Физика
CREATE TABLE EXT_STUD
(Номер NUMBER(6),
ФИО VARCHAR2(50),
Дата DATE,
Оценка NUMBER(1),
Дисциплина VARCHAR2(50));
ORGANIZATION EXTERNAL
(TYPE ORACLE_LOADER
DEFAULT DIRECTORY student
ACCESS PARAMETERS
(RECORDS DELIMITED BY NEWLINE
BADFILE 'bad_stud.bad'
LOGFILE 'log_stud.log'
FIELDS TERMINATED BY WHITESPACE)
LOCATION ('stud.dat'))
REJECT LIMIT 100;
DESCRIBE EXT_STUD;
Комментарий:
С помощью CREATE TABLE создаем нужную таблицу, после чего организовываем считывание файла: директория по умолчанию student, ACCESS PARAMETERS – параметры, по которым таблица должна быть заполнена, строки разделены переходом на новую строку с помощью RECORDS DELIMITED BY NEWLINE, файл ошибок 'bad_stud.bad', файл логов 'log_stud.log', в строке данные разделены пробелом (FIELDS TERMINATED BY WHITESPACE), разрешается 100 ошибок при занесении данных из файла (REJECT LIMIT 100).
4. Создать запрос для вывода всех дат из заданного диапазона, отсутствующих в датах приема на работу преподавателей. Даты начала и окончания диапазона задаются параметрически.
SELECT date_not
FROM (SELECT d1 + level -1 date_not
FROM (SELECT TO_DATE('&dt1') d1, TO_DATE('&dt2') d2 FROM DUAL)
CONNECT BY level <= d2 - d1 + 1)
WHERE date_not NOT IN (SELECT "ДАТА_КОНТРАКТА" FROM "ПРЕПОДАВАТЕЛИ")
ORDER BY date_not;
Результат:
02.11.95
03.11.95
04.11.95
05.11.95
06.11.95
07.11.95
08.11.95
09.11.95
10.11.95
11.11.95
12.11.95
13.11.95
14.11.95
15.11.95
16.11.95
Комментарий:
С помощью SELECT TO_DATE('&dt1') d1, TO_DATE('&dt2') d2 FROM DUAL вводим начальную и конечную даты.
С помощью CONNECT BY level <= d2 - d1 + 1 получаем все данные из заданного диапазона.
Из условия WHERE date_not NOT IN (SELECT "ДАТА_КОНТРАКТА" FROM "ПРЕПОДАВАТЕЛИ") получаем даты, не содержащиеся в датах приема на работу преподавателей.
5. Создать запрос, позволяющий выводить информацию о студентах и преподавателях (Фамилия с инициалами, Зарплата/Стипендия, Статус – преподаватель или студент).
SELECT CAST(фамилия ||' '|| SUBSTR(имя, 0, 1) ||'. '|| SUBSTR(отчество, 0, 1)||'.' AS VARCHAR2(30))ФИО,
зарплата AS "Зарплата/Стипендия", 'Преподаватель' AS "Статус"
FROM преподаватели
UNION
SELECT фамилия ||' '|| SUBSTR(имя, 0, 1) ||'. '|| SUBSTR(отчество, 0, 1)||'.' ФИО,
стипендия AS "Зарплата/Стипендия", 'Студент' AS "Статус"
FROM студенты;
Результат:
Абдулов С. А. 3000 Преподаватель
Викулина В. И. 3000 Преподаватель
Гриценко В. Н. 300 Студент
Ежов А. П. 200 Студент
Загарийчук И. Д. 2000 Преподаватель
Казанко В. В. 2000 Преподаватель
Костыркин О. В. 4000 Преподаватель
Котенко А. Н. 0 Студент
Нагорный Е. В. 200 Студент
Позднякова Л. А. 2500 Преподаватель
Комментарий:
С помощью CAST приводим тип данных VARCHAR2(30), добавляем столбец Зарплата/Стипендия и мнимый столбец Статус, содержащий значение преподавателя, затем добавляем столбец Зарплата/Стипендия и мнимый столбец Статус, содержащий значение студента и соединяем полученные таблицы.
6. Создать запрос для вывода фамилий трех самых высокооплачиваемых преподавателей. К списку добавить преподавателей, которые получают такую же зарплату, как и самый низкооплачиваемый из трех высокооплачиваемых. Задачу решить с использованием аналитических функций.
Дата добавления: 2015-08-18; просмотров: 169 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Main_Table PK User_Constraints 5 страница | | | Main_Table PK User_Constraints 7 страница |