|
Читайте также: |
a@sAs2Q15fs* GOOD
Комментарий:
Проверяем длину пароля: length(str) >=10
Наличие цифр: regexp_count(str,'[[:digit:]]') >0
Наличие букв в разных регистрах: regexp_count(str,'[[:lower:]]') >0 and regexp_count(str,'[[:upper:]]') >0
Наличие знаков препинания: regexp_count(str,'[[:punct:]]') >0
Исключаем содержание трех последовательных символов: length(regexp_substr(str,'[0123456789]+',1,1)) <=1
20. Банкомат обналичивает кредитные карточки. Номиналы денег:$1, $2, $5, $50, $100. В столбце q_id таблицы utQ содержится сумма выдачи денег по каждой операции за текущий день. Для каждого q_id найти возможный оптимальный (с наименьшим использованием денежных купюр) вариант выдачи денег. Также найти оптимальный вариант обналичивания денег, в случае, когда в банкомате отсутствуют купюры одного из номиналов. При этом учесть, что максимальное количество купюр, выдаваемое банкоматом за один раз, ограничено 20-ю.Вывод: сумма выдачи; оптимальный вариант выдачи (список купюр через запятую в порядке возрастания номиналов); вариант выдачи при отсутствии купюр с номиналом $1,..., вариант выдачи при отсутствии купюр с номиналом $100; общее возможное число вариантов выдачи денег. При невозможности выдать определенную сумму имеющимися номиналами вывести надпись "NON-DIVISIBLE AMOUNT" с учетом ограничения на 20 купюр.
Задачу решить без использования иерархических запросов, аналитических функций, регулярных выражений, раздела Model.
Результат правильного выполнения:
| sm | fl | n1 | n2 | n5 | n50 | n100 | cnt1 |
| NON-DIVISIBLE AMOUNT | |||||||
| 1,1 | |||||||
| 1,2 | NON-DIVISIBLE AMOUNT | 1,1,1 | 1,2 | 1,2 | 1,2 | ||
| 2,2 | 2,2 | 1,1,1,1 | 2,2 | 2,2 | 2,2 | ||
| 1,2,2 | |||||||
| 1,5 | 2,2,2 | 1,5 | 2,2,2 | 1,5 | 1,5 | ||
| 2,5 | 2,5 | 1,1,5 | 1,2,2,2 | 2,5 | 2,5 | ||
| 1,2,5 | 2,2,2,2 | 1,1,1,5 | 2,2,2,2 | 1,2,5 | 1,2,5 | ||
| 2,2,5 | 2,2,5 | 1,1,1,1,5 | 1,2,2,2,2 | 2,2,5 | 2,2,5 | ||
| 5,5 | 5,5 | 5,5 | 2,2,2,2,2 | 5,5 | 5,5 | ||
| 1,5,5 | 2,2,2,5 | 1,5,5 | 1,2,2,2,2,2 | 1,5,5 | 1,5,5 | ||
| 2,5,5 | 2,5,5 | 1,1,5,5 | 2,2,2,2,2,2 | 2,5,5 | 2,5,5 | ||
| 1,2,5,5 | 2,2,2,2,5 | 1,1,1,5,5 | 1,2,2,2,2,2,2 | 1,2,5,5 | 1,2,5,5 | ||
| 2,2,5,5 | 2,2,5,5 | 1,1,1,1,5,5 | 2,2,2,2,2,2,2 | 2,2,5,5 | 2,2,5,5 | ||
| 5,5,5 | 5,5,5 | 5,5,5 | 1,2,2,2,2,2,2,2 | 5,5,5 | 5,5,5 | ||
| 1,5,5,5 | 2,2,2,5,5 | 1,5,5,5 | 2,2,2,2,2,2,2,2 | 1,5,5,5 | 1,5,5,5 | ||
| 2,5,5,5 | 2,5,5,5 | 1,1,5,5,5 | 1,2,2,2,2,2,2,2,2 | 2,5,5,5 | 2,5,5,5 | ||
| 1,2,5,5,5 | 2,2,2,2,5,5 | 1,1,1,5,5,5 | 2,2,2,2,2,2,2,2,2 | 1,2,5,5,5 | 1,2,5,5,5 | ||
| 2,2,5,5,5 | 2,2,5,5,5 | 1,1,1,1,5,5,5 | 1,2,2,2,2,2,2,2,2,2 | 2,2,5,5,5 | 2,2,5,5,5 | ||
| 5,5,5,5 | 5,5,5,5 | 5,5,5,5 | 2,2,2,2,2,2,2,2,2,2 | 5,5,5,5 | 5,5,5,5 | ||
| 1,5,5,5,5 | 2,2,2,5,5,5 | 1,5,5,5,5 | 1,2,2,2,2,2,2,2,2,2,2 | 1,5,5,5,5 | 1,5,5,5,5 | ||
| 2,5,5,5,5 | 2,5,5,5,5 | 1,1,5,5,5,5 | 2,2,2,2,2,2,2,2,2,2,2 | 2,5,5,5,5 | 2,5,5,5,5 | ||
| 1,2,5,5,5,5 | 2,2,2,2,5,5,5 | 1,1,1,5,5,5,5 | 1,2,2,2,2,2,2,2,2,2,2,2 | 1,2,5,5,5,5 | 1,2,5,5,5,5 | ||
| 5,5,5,5,5 | 5,5,5,5,5 | 5,5,5,5,5 | 1,2,2,2,2,2,2,2,2,2,2,2,2 | 5,5,5,5,5 | 5,5,5,5,5 |
ВАРИАНТ 22
(Базы данных HR и OE)
1. Одной командой SELECT вывести сведения обо всех столбцах таблиц текущей схемы, которые используются во внешних ключах.
В результат вывести пять столбцов:
1. Имя ссылочного ограничения целостности (внешнего ключа)
2. Имя таблицы, которой принадлежит данное ссылочное ограничение целостности (внешний ключ)
3. Имя столбца таблицы, который входит во внешний ключ (foreign key)
4. Имя таблицы, на которую ссылается данный внешний ключ
5. Имя столбца таблицы, на которую ссылается данный внешний ключ, которому соответствует столбец, указанный в п.3
Результат отсортировать по возрастанию по столбцам 1, 2 и 3, перечисленным выше.
Select Distinct Uc.Constraint_Name, Uc.Table_Name, Ucc.Column_Name, A.Table_Name As "Dest_Table_Name", B.Column_Name As "Dest_Column_Name"
From User_Constraints Uc Join User_Cons_Columns Ucc
On Uc.Constraint_Name = Ucc.Constraint_Name
Join User_Constraints A
On A.Constraint_Name = Uc.R_Constraint_Name
Join User_Cons_Columns B On A.Constraint_Name = B.Constraint_Name
Where Uc.Constraint_Type = 'R' And Ucc.Position = B.Position
Order By Uc.Constraint_Name,Uc.Table_Name, Ucc.Column_Name;

Комментарий:
Свяжем user_constraints с user_cons_columns по названию ограничения потом свяжем с user_constraints по ограничению равному ссылочному, чтобы узнать Имя таблицы, на которую ссылается данный внешний ключ. Далее опять связываем с user_cons_columns по названию ограничения чтобы узнать Имя Столбца Таблицы, На Которую Ссылается Данный Внешний Ключ, Которому Соответствует Столбец, Указанный В П.3 (условие Ucc.Position = B.Position)
В разделе Where укажем тип 'R' соответствует foreign key
Сортируем по Uc.Constraint_Name,Uc.Table_Name, Ucc.Column_Name
2. Вывести название отдела и фамилии сотрудников с минимальным окладом по департаменту (при одинаковом минимальном окладе фамилии должны выводиться через запятую). Не учитывать людей, не привязанных ни к одному департаменту.
With List as (Select Department_Name, Last_Name, Salary, Min_Sal
From(
Select Department_Name, Last_Name, Salary, Min(salary) over (partition by Department_Name) min_sal
From Departments Join Employees Using(Department_Id)
)
Where Salary = Min_Sal)
Select Department_Name, Max(Ltrim(Sys_Connect_By_Path(Last_Name,', '),', ')) Last_Name
--Sys_Connect_By_Path возвращает путь знач. от корня до узла (сотрудников с один. Min_sal через запятую)
From (Select Department_Name, Last_Name, Row_Number () Over (Partition By Department_Name order by Last_name) Rownumindept
From List
ORDER BY Department_Name) T --пронумеруем сотрудников с Min_sal по отделам
GROUP BY Department_Name
Start With Rownumindept = 1
Connect By Prior Rownumindept+1 = Rownumindept And Prior Department_Name = Department_Name;
Комментарий:
Подзапрос List выдает информацию о минимальных зарплатах в каждом отделе и фамилии кому эти зарплаты принадлежат.
Использовалась Аналитическая итоговая функция Min()

В подзапросе Т используя аналитическую функцию Row_Number() мы пронумеруем сотрудников с минимальными зарплатами по отделам.

Затем произведем иерархическую выборку данных по отделам, если в отделе больше одного человека с мин. Зарплатой, то благодаря функции Sys_Connect_By_Path(Last_Name,', ') мы выведем всех нужных сотрудников в отделе через запятую
Итог:

3. Используются таблицы стандартной схемы HR.
Одной командой SELECT вывести список сотрудников компании, имеющих коллег с таким же идентификатором должности и окладом.
Если данный идентификатор должности и размер оклада имеет один единственный сотрудник, то сведения о нём в результат попадать не должны.
В результат вывести:
1. Идентификатор должности
2. Размер оклада
3. Список фамилий сотрудников, имеющих данный идентификатор должности и данный оклад.
Фамилии в списке должны быть:
a. Упорядочены по алфавиту (по возрастанию)
b. Разделены символами ', ' ("запятая" и "пробел")
c. Перед первой фамилией не должно быть символов-разделителей
d. После последней фамилии символов-разделителей быть не должно
Результат упорядочить:
1. По размеру оклада (по убыванию)
2. По идентификатору должности (по возрастанию)
Пример вывода:
| JOB_ID | SALARY | EMP_LIST |
| SA_REP | Banderberg, Maligan | |
| SA_REP | Coreando, McCartney, Silman | |
| FI_ACCOUNT | Cabrioninni, Finley, Santana, Yarsuoto | |
| ... | ||
| ST_CLERK | McLaughlin, Philling |
Select Job_Id, Salary, Emp_List
From (Select A1.Y, A1.Job_Id, A1.Salary, A1.Emp_List
From
(Select Rownum X,Level Y, Job_Id, Salary, Ltrim(Sys_Connect_By_Path(Last_Name,', '),', ') Emp_List
From (Select Job_Id, Salary, Last_Name, Row_Number () Over (Partition By Job_Id, Salary Order By Last_Name) Row_Num
From Employees)
Start With Row_Num = 1
Connect By Prior Row_Num+1 = Row_Num And Prior Job_Id =Job_Id And Prior Salary =Salary) A1
Full Join
(Select Rownum X,Level Y, Job_Id, Salary, Ltrim(Sys_Connect_By_Path(Last_Name,', '),', ') Emp_List
From (Select Job_Id, Salary, Last_Name, Row_Number () Over (Partition By Job_Id, Salary Order By Last_Name) Row_Num
From Employees)
Start With Row_Num = 1
Connect By Prior Row_Num+1 = Row_Num And Prior Job_Id = Job_Id And Prior Salary = Salary) A2
On A1.X+1 = A2.X
Where A1.Y >= A2.Y Or A2.Y Is Null)
Where Y!=1
Order By Salary Desc, Job_Id Asc;
Комментарий:
A1 и А2 одинаковые подзапросы выдающие сотрудников с одинаковой зарплатой по специальности
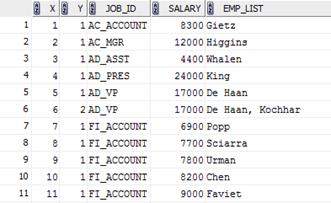
Связываем А1 и А2 Full Join On A1.X+1 = A2.X
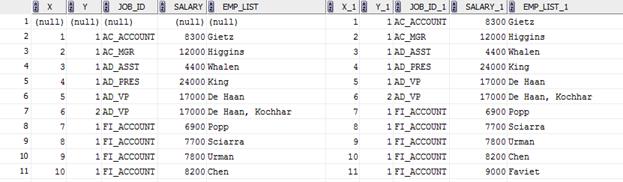

и благодаря условию Where A1.Y >= A2.Y Or A2.Y Is Null отсечем промежуточные результаты
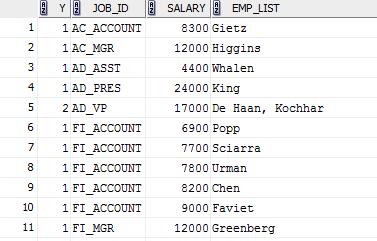
От этого соединения селектом возьмем Job_Id, Salary, Emp_List и не забудем откинуть записи с единственным сотрудником (условие Where Y!=1)

4. Используются таблицы стандартной схемы OE.
Одной командой SELECT вывести список покупателей, в информации о которых хранятся два или более телефонных номера.
В результат вывести пять столбцов:
1. Идентификатор покупателя
2. Имя покупателя
3. Фамилию покупателя
4. Количество хранящихся телефонных номеров покупателя
5. Список хранящихся телефонных номеров покупателя. Телефонные номера в списке должны быть:
a. Упорядочены по алфавиту, как строковые данные (по возрастанию)
b. Разделены символами ', ' ("запятая" и "пробел")
c. Перед первым номером телефона не должно быть символов-разделителей
d. После последнего номера телефона символов-разделителей быть не должно.
Результат упорядочить по идентификатору покупателя по возрастанию.
With T as (
Select distinct Customer_Id, Cust_First_Name, Cust_Last_Name, Get_Phone_Number_F(level,PHONE_NUMBERS) as a1
From Customers
Where Get_Phone_Number_F(Level,Phone_Numbers) Is Not Null
Connect By Level<=2
Order By Customer_Id)
Select Customer_Id, Cust_First_Name, Cust_Last_Name, CNNUM, ListPhone
From(
Select Customer_Id, Cust_First_Name, Cust_Last_Name, Count(A1) As Cnnum
From T
Group By Customer_Id, Cust_First_Name, Cust_Last_Name
Order By Customer_Id)
Join
(Select Customer_Id, Max(Ltrim(Sys_Connect_By_Path(A1,', '),', ')) ListPhone
FROM (Select Customer_Id, A1, Row_Number () Over (Partition By Customer_Id Order By A1) Rownum1
From T
Order By Customer_Id)
Group By Customer_Id
Start With Rownum1 = 1
Connect By Prior Rownum1+1 = Rownum1 And Prior Customer_Id =Customer_Id) Using(Customer_Id)
Where Cnnum>=2
Order by Customer_Id;
Комментарий:
Подзапрос Т возвращает Customer_Id, Cust_First_Name, Cust_Last_Name и соответствующие им номера телефона(Для извлечения номеров из столбца типа PHONE_LIST_TYP использовалась функция Get_Phone_Number_F). (Connect By Level<=2) тут нужно указать <=5, т.к в типе phone_list_typ может храниться до 5 номеров, но судя по таблице можно указать 2(т.к. на быстродействии выполнения запроса это значительно скажется, и тем более ни у кого больше 2 номеров нет)
В основном селекте свяжем два подзапроса основанные на T, один подсчитывает Количество Хранящихся Телефонных Номеров Покупателя, второй выводит Список хранящихся телефонных номеров покупателя, связываем по Идентификатору покупателя. Отбираем покупателей с количеством номеров >= 2, сортируем по идентификатору покупателя, и получаем результат:
CUSTOMER_ID CUST_FIRST_NAME CUST_LAST_NAME CNNUM LISTPHONE
----------- -------------------- -------------------- ----- ----------------------------------------------------------
235 Edward Oates 2 +1 410 012 4715, +1 410 083 4715
323 Goetz Falk 2 +91 80 012 4123, +91 80 083 4833
326 Hal Olin 2 +49 89 012 4129, +49 89 083 4839
327 Hannah Kanth 2 +49 90 012 4131, +49 90 083 4131
328 Hannah Field 2 +49 91 012 4133, +49 91 083 4133
347 Kelly Quinlan 2 +39 10 012 4371, +39 10 083 4371
348 Kelly Lange 2 +39 49 012 4373, +39 49 083 4373
349 Ken Glenn 2 +39 49 012 4375, +39 49 083 4375
350 Ken Chopra 2 +39 49 012 4377, +39 49 083 4377
852 Amanda Tanner 2 +41 69 012 3581, +41 69 083 3581
911 Bo Dickinson 2 +91 80 012 3699, +91 80 083 3699
912 Bo Ashby 2 +91 80 012 3701, +91 80 083 3701
928 Burt Spielberg 2 +91 80 012 3733, +91 80 083 3733
929 Burt Neeson 2 +91 80 012 3735, +91 80 083 3735
59 rows selected
5. Используются таблицы стандартной схемы OE.
Проанализировать продажи товаров различного статуса в разрезе семейного положения покупателей.
Одной командой SELECT вывести результат в виде таблицы, содержащей пять столбцов:
Столбец 1: Статус товара,
Столбец 2: Сумма продаж товаров с данным статусом женатым мужчинам,
Столбец 3: Сумма продаж товаров с данным статусом неженатым мужчинам,
Столбец 4: Сумма продаж товаров с данным статусом замужним женщинам,
Столбец 5: Сумма продаж товаров с данным статусом незамужним женщинам.
То есть строчки относятся к товарам определенного статуса, столбцы – к различному семейному положению, а в ячейках приведены денежные суммы продаж товаров из соответствующих заказов.
Статус товара определяется по значениям в поле PRODUCT_STATUS таблицы PRODUCT_INFORMATION.
Семейное положение покупателей определить по полям GENDER и MARITAL_STATUS таблицы CUSTOMERS.
Результат отсортировать по статусу продукта по возрастанию.
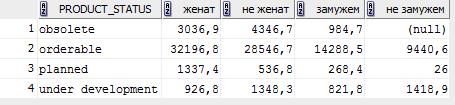
Пример вывода (значения условные):
| PRODUCT_STATUS | женат | не женат | замужем | не замужем |
| obsolete | 12345,6 | 789101,2 | 6789,1 | |
| orderable | 7890,1 | 23456,7 | 89102,3 | 45678,9 |
| planned | 234567,8 | |||
| under development | 34567,8 | 456,7 |
With T as (Select distinct Product_Status, Sum(UNIT_PRICE) as Sums,Marital_Status, Gender
From Product_Information Join Order_Items Using(Product_Id)
Join Orders Using(Order_Id)
Join Customers Using(Customer_Id)
Group by Product_Status, Marital_Status, Gender
Order By Product_Status)
Select Product_Status, A1.Sums "Женат",A2.Sums "не женат",A3.Sums "замужем",A4.Sums "не замужем"
From(
(Select Product_Status, Sums
From T
Where Marital_Status = 'married' And Gender = 'M') a1
Left Outer Join
(Select Product_Status, Sums
From T
Where Marital_Status = 'single' And Gender = 'M') a2 Using(Product_Status)
Left Outer Join
(Select Product_Status, Sums
From T
Where Marital_Status = 'married' And Gender = 'F') a3 Using(Product_Status)
Left Outer Join
(Select Product_Status, Sums
From T
Where Marital_Status = 'single' And Gender = 'F') A4 Using(Product_Status))
Order by Product_Status;
Комментарий:
В подзапросе T связываем таблицы Product_Information, Order_Items, Orders, Customers и подсчитываем суммы продаж товаров определенного статуса по людям с разным семейным положением и полом

-В основном селекте свяжем таблицы T c определенными условиями при помощи Left Outer Join
Итог:
6. Используются таблицы стандартной схемы OE.
Вывести информацию обо всех товарах (всего 32 столбца):
1. Идентификатор товара,
2. Цена товара по каталогу,
3. Название товара на английском языке (US),
4. Название товара на русском языке (RU),
5-32. Название товара на всех остальных языках.
Порядок столбцов определяется значениями идентификаторов национальных языков –
они должны быть упорядочены по возрастанию:
'AR', 'CA', 'CS','D','DK', 'E', 'EL','ESA', 'F', 'FRC', 'HU',
'I', 'IW', 'JA', 'KO', 'N', 'NL', 'PL', 'PT', 'PTB', 'RO',
'S', 'SF','SK', 'TH', 'TR', 'ZHS', 'ZHT'.
Результат должен быть отсортирован по идентификатору товара по возрастанию.
Select *
From(Select Product_Id, List_Price, Translated_Name As Us
From Product_Descriptions Join Product_Information Using(Product_Id) Where Language_Id='US')
Left Outer Join
(Select Product_Id, Translated_Name As Ru From Product_Descriptions Where Language_Id='RU') Using(Product_Id)
--сначало как указано в условии выведем названия на US и RU
Left Outer Join
(Select * From (Select Product_Id, Translated_Name, D
From Product_Descriptions Join
(Select Language_Id, Rownum As D -- пронумеруем все оставшиеся идентификаторы языков и отсортируем
From (
Select Distinct Language_Id
From Product_Descriptions
Where Language_id not in('US', 'RU')
Order By Language_Id
)) Using(Language_Id)) --напротив названия товара на каком-то языке поставим соотв. номер идентификатора
Pivot (--с помощью функции pivot разобьем столбец с названиями товаров по отдельным столбцам(по знач. id)
Max(Translated_Name)
For D In (1 AR, 2 CA, 3 CS, 4 D, 5 DK, 6 E, 7 EL, 8 ESA, 9 F, 10 FRC, 11 HU, 12 I, 13 IW, 14 JA, 15 KO, 16 N, 17 NL, 18 PL, 19 PT, 20 PTB, 21 RO, 22 S, 23 SF, 24 SK, 25 TH, 26 TR, 27 ZHS, 28 ZHT)
)
Order By 1
) Using(Product_Id);
Комментарий:
Пронумеруем все оставшиеся идентификаторы языков и отсортируем

28 rows selected
Напротив названия товара на каком-то языке поставим соотв. номер идентификатора

После применения pivot()
 288 rows selected
288 rows selected
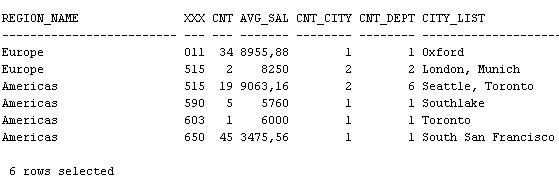
7. Создать запрос для определения информации по сотрудникам, исходя из региона и первых трех цифр телефона:
1. Регион
2. Первые три цифры номера телефона
3. Количество сотрудников
4. Средняя зарплата
5. Количество городов
6. Количество отделов
7. Список городов через запятую
With T As (Select R.Region_Id, R.Region_Name, Substr(E.Phone_Number, 1, 3) Xxx, Salary, City, D.Department_Id
From Regions R Inner Join Countries C
On R.Region_Id=C.Region_Id Inner Join Locations L
On L.Country_Id=C.Country_Id Inner Join Departments D
On D.Location_Id=L.Location_Id Inner Join Employees E
On E.Department_Id=D.Department_Id),
Tab1 As (Select Region_Id, Region_Name, Xxx, Max(Ltrim(Sys_Connect_By_Path(City,', '),', ')) City_List
From (Select Region_Id, Region_Name, Xxx, City, Row_Number () Over (Partition By Region_Id, Region_Name, Xxx Order By City) Rn
From (Select Distinct Region_Id, Region_Name, Xxx, City From T) T1
Order By Region_Id, Region_Name, Xxx) T1
Group By Region_Id, Region_Name, Xxx
Start With Rn = 1
Connect By Prior Rn+1 = Rn And Prior Region_Id =Region_Id And Prior Xxx=Xxx),
Tab2 As (Select Region_Id, Region_Name, Xxx, Count(Xxx) Cnt, Round(Avg(Salary),2) Avg_Sal,
Count(Distinct City) Cnt_City, Count(Distinct Department_Id) Cnt_Dept
From T
Group By Region_Id, Region_Name, Xxx)
Select Tab1.Region_Name, Tab1.Xxx, Cnt, Avg_Sal, Cnt_City, Cnt_Dept, City_List
From Tab1 Inner Join Tab2
On Tab1.Region_Id=Tab2.Region_Id And Tab1.Xxx=Tab2.Xxx
Комментарий:
t возвращает информацию о каждой зарплате и соответствующие ей город, департамент, номер региона, регион и последние три цифры номера телефона

106 rows selected
В tab1 список городов с соотв. им номерам регионов и их названием
tab2 возвращает кол-во номеров, среднюю зарплату, количество городов, количество департаментов - все это сгруппировано по номеру региона, по имени региона и по первым трем цифрам телефона

Связываем эти две таблицы по номеру региона и первым трем цифрам телефона
Итог:
8. Используются таблицы стандартной схемы HR.
Используя таблицы REGIONS, COUNTRIES, LOCATIONS, DEPARTMENTS, построить (показать) иерархию объектов "Регион - Страна - Город (населенный пункт) - Подразделение" для региона name = 'Americas'.
Иерархия должна быть построена (показана) одной командой SELECT.
В результате вывести:
номер уровня, на котором находится в иерархии данный объект (LEVEL),
имя объекта, дополненное слева (LEVEL -1)*3 пробелами.
Объекты одного уровня должны быть отсортированы по именам.
Пример результата:
Уровень Иерархия
1 Europe
2 Belgium
2 Denmark
2 France
2 Germany
3 Munich
4 Public Relations
2 Italy
3 Roma
3 Venice
2 Netherlands
Задачу решить без использования иерархических запросов.
Select Region || Country || City || Department_Name "Иерархия"
From(
Select Region_Name Region, Lpad(Country_Name, Length(Country_Name)+1, '/') Country,
Lpad(City, Length(City)+1, '/') City, Lpad(Department_Name, Length(Department_Name)+1, '/') Department_Name
From Regions
Full Join Countries Using(Region_Id)
Full Join Locations Using(Country_Id)
Full Join Departments Using(Location_Id)
Where Region_Name= 'Americas');

29 rows selected
9. Используются таблицы стандартной схемы OE.
Одной командой SELECT вывести информацию о суммарной стоимости товаров, имеющихся в наличии на складах компании.
При расчете суммарной стоимости использовать цену товаров по каталогу.
Вывести информацию только по тем складам, где есть товары.
В результат вывести три столбца:
1. Идентификатор товарного склада,
2. Название товарного склада,
3. Суммарная стоимость товаров, имеющихся в наличии на складе (округлить до целых).
Результат отсортировать:
1. По суммарной стоимости товаров, имеющихся в наличии на складе (по убыванию),
2. По названию товарного склада (по возрастанию).
Select Warehouse_Id, Warehouse_Name, Round(Sum(Unit_Price)) As Sum
From Warehouses Join Inventories Using(Warehouse_Id)
Join Order_Items Using(Product_Id)
Group By Warehouse_Id, Warehouse_Name
Order By Round(Sum(Unit_Price)) Desc, Warehouse_Name Asc;
Результат:

Комментарий:
Связываем таблицы Warehouses, Inventories, Order_Items для того чтобы подсчитать суммарную стоимость товаров, имеющихся в наличии на складе. И сортируем.
10. Вывести статистику по торговым агентам
1. Имя торгового агента
2. Фамилия торгового агента
3. Сумма выручки сделок, которые сопровождал торговый агент
Дата добавления: 2015-08-18; просмотров: 286 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Main_Table PK User_Constraints 20 страница | | | Main_Table PK User_Constraints 22 страница |