Читайте также:
|
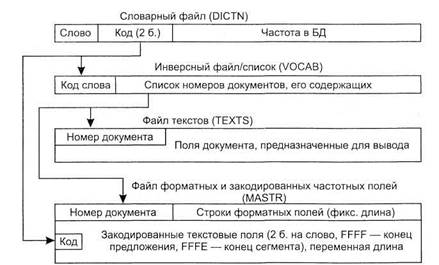
Физическая структура БД рассматриваемой нами «условной» системы приведена на рис. 2.12. и включает в себя четыре файла операционной системы:
DICTN — файл частотного словаря, устанавливающий соответствие между словом, встречающимся в БД, его кодом и частотой (используется при текстовом поиске);
VOCAB — инверсный (инвертированный, обратный) для каждого слова БД список его содержащих документов (используется при текстовом поиске);
TEXTS — текстовый файл, содержащий собственно документы, используется при выдаче (просмотре) документов;
MASTR — прямой, последовательный файл, содержащий «собранные» с одну строку фиксированной длины форматные поля и список двухбайтовых кодов слов, находящихся в тексте данного документа и прошедших входную обработку (см. ниже). При необходимости в соответствующих местах находятся разделители сегментов и/или предложений. Файл используется при форматном поиске и при наличии в запросах конструкций SENT, SEGM, СТХ.
Вопрос о происхождении содержания файлов рассматривается ниже, здесь же рассмотрим взаимодействие указанных файлов при проведении поиска (навигация в физической БД).
|
Рис. 2.12. Физическая структура БД STAIRS/DPS
Простой текстовый поиск:
000001>THERMAL AND REACTOR;
• обращение к файлу DICTN и определение кодов слов запроса:
CT{THERMAL) и CR(REACTOR);
• обращение к файлу VOCAB и извлечение списков документов:
LT(THERMAL) и lR(REACTOR);
• пересечение списков, образование результирующего списка:
Lc = LT n LR;
• обращение к файлу TEXTS, извлечение документов списка Lc
и предоставление пользователю.
Текстовый поиск с расширением:
000002>THERNAL AND REACT$;
• обращение к файлу DICTN и определение кодов слов запроса:
CT(THERMAL), Сm(REACTION), СR2(REACTIONS),
СR3(REACTIVE), С R4(REACTOR), СR5(REACTORS);
• обращение к файлу VOCAB и извлечение списков документов:
LT(THERMAL\ LR](REACTION), LR2(REACT IONS),
LR3(REACTIVE), LR4(REACTOR), LR5(REACTORS);
• объединение списков, относящихся к REACTS:
LR = LRX u LR2 u LR3 u LR4 u LR5;
• пересечение списков, образование результирующего списка
Lc = LT n LR,
• обращение к файлу TEXTS, извлечение документов списка 1е
и предоставление пользователю.
Текстовый поиск с учетом контекста:
000001>THERMAL CTX REACTOR;
• обращение к файлу DICTN и определение кодов слов запроса:
CT{THERMAL) и CR(REACTOR);
• обращение к файлу VOCAB и извлечение списков документов:
LT{THERMAL) и LR(REACTOR);
• пересечение списков, образование списка Lcn = LT n LR\
• обращение к файлу MASTR, извлечение документов, входящих в список Lcn;
• сканирование закодированных текстов, выявление документов, в которых коды Ст и CR находятся рядом. Составление результирующего списка 1е;
• обращение к файлу TEXTS, извлечение документов списка Lc
и предоставление пользователю.
Аналогично строятся траектории навигации при сканировании форматных полей (в режиме..SELECT).
Обработка входного потока документов (загрузка БД)
Формирование содержания физической БД на основе продуктов служб-генераторов БД (или загрузка документов, рис. 2.13) является весьма важной операцией, за которую ответственность несет администратор базы данных (АБД). Основным средством администратора при проектировании логической структуры документальной БД является совокупность таблиц, описывающих внутренний формат документа и его связь с внешним (входным) форматом. Такие таблицы получили обобщенное название DBD (database definition — определение базы данных).

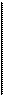

Рис. 2.13. Информационные потоки при загрузке БД
Входным форматом STAIRS является картонный формат (см. рис. 1.11, БД INIS), в котором поток документов представляет собой последовательность 80-байтовых строк, разделенных на три зоны — номер документа, метку поля (полей) документа, содержание.
Первая колонка содержит номер документа (последовательность строк с одинаковыми номерами образует документ), вторая колонка — метки полей (длинное поле может содержаться в нескольких строках с одинаковой меткой). Наоборот, несколько коротких (форматных) полей могут содержаться в одной строке.
Определение БД для случая, представленного на рис. 1.4, может иметь следующий вид и состоять из таблиц:
• описания форматных полей (ТОФП, табл. 2.3.);
© текстовых полей (ТОТП, табл. 2.4).
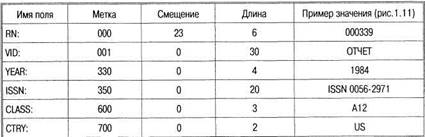
Описание форматных полей.Каждая строка таблицы содержит описание поля: имя с точки зрения пользователя, метка во входном потоке, начальная позиция в строке содержания, длина поля. Фактически это полная информация для извлечения подстроки поля из входного потока с целью помещения в определенные позиции записи файла MASTR.
Таблица 2.3. Описание форматных полей для БД INIS
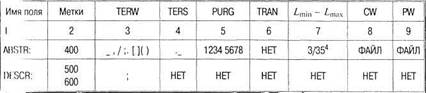
Описание текстовых полей. Строки таблицы содержат информацию для анализа содержания документа и заполнения файлов DICTN и VOCAB. Поясним содержание таблицы:
1) имя поля — то же, что и для форматных полей;
2) метки поля — допускается указание нескольких меток, с целью
объединения нескольких текстовых полей, например в данном при
мере (500) — первоначально приписанные дескрипторы (IAD, Initialy
Added Descriptors), в то время как (600) — автоматически приписанные дескрипторы, на основе тезауруса INIS (Computer Added
Descriptors) может использоваться групповая нотация типа 50$;
3) разделители (терминаторы) слов — символы, позволяющие
выделить слова из входного потока — пробел и знаки препинания;
4) разделители (терминаторы) предложений — как правило, точка с пробелом; иногда учитываются разделители сегментов, если
кжстовое поле содержит внутренние сегменты (абзацы);
5) удаляемые символы (в данном случае — цифры);
6) транслитерация — используется при необходимости глобальной замены некоторых входных символов на другие;
7) максимальная и минимальная длина слова — используется для
выделения из текста значащих слов. Очевидно, что короткие слова
обычно представляют собой предлоги или артикли, а слишком длинные — ошибочные строки или «склеившиеся» слова. И те и другие не
должны попадать в словарные файлы системы (DICTN, VOCAB);
8) ссылка на файл общих слов (Common Words, отрицательный
словарь), или слов, которые хотя и имеют «нормальную» длину, но
все же для данной предметной области не информативны или являются вспомогательными частями речи (КОТОРЫЙ, ВСЕХ, ОДНАКО
и пр.). Включение подобных слов в файлы системы нецелесообразно;
9) ссылка на положительный словарь или список слов, которые
могут не пройти через фильтр Lmin - lmax, но являются информативными для данной предметной области (например, для юридических
ЬД (см. Jurius) в такой словарь могут войти: СУД, ЛИЦ, ГОД, ЛЕТ,
УК, ГКи др., которые будучи короткими, все же существенны в очевидных контекстах!).
Таблица 2.4. Описание текстовых полей INIS
 Опишем вкратце алгоритм загрузки некоторого документа в БД STAIRS.
Опишем вкратце алгоритм загрузки некоторого документа в БД STAIRS.
Первоначальная фаза и загрузка форматных полей:
а) выделение очередного документа (с номером NR) из входного
потока и помещение его в буфер;
б) создание новой записи в файле TEXTS (NR) и размещение в
ней текста документа;
в) создание новой записи в файле MASTR (Na), в соответствии с
ТОФП извлечение из документа форматных полей и размещение их
в фиксированной строке записи файла MASTR.
Загрузка текстовых полей:
г) извлечение очередного слова (W) из текущего текстового
поля в соответствии с разделителями слов;
д) поиск W в положительном словаре. Если найдено — переход
к(з);
е) проверка на Lmin - Lmax. Если W \\t входит в интервал — переход к (г);
ж) поиск в отрицательном словаре. Если W найдено — переход
к (г);
З.) начало загрузки слова в физические файлы БД. Поиск W в
файле DICTN. Если найдено — переход к (л);
и) включение W в словарь (создание новой записи файла DICTN, назначение слову кода, обнуление частоты слова);
к) создание новой записи инверсного файла VOCAB, занесение кода W и номера текущего документа Nu;
л) увеличение частоты слова на единицу, извлечение кода слова W, занесение кода в текущую запись MASTR;
м) поиск по коду в файле VOCAB, занесение в найденный список УУД;
н) переход к (г).
Дата добавления: 2015-07-20; просмотров: 122 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Поисковые возможности ДИПС STAIRS | | | ЛИПС локального и удаленного доступа Irbis |