Читайте также:
|
Система Irbis разработана в РГГУ (при участии таких организаций, как ВИНИТИ, ВНТИЦЕНТР, ИНИОН, осуществлявших тестирование и опытную эксплуатацию промежуточных версий ИПС). Программный комплекс Irbis ориентирован на работу как в полностью локальном режиме (в том числе для поддержки баз данных, выпускаемых на CD ROM, — Winlrbis, рис. 2.14), так и в сетевых режимах, в том числе в локальной сети, в составе BBS и в составе Web-сервера для доступа по каналам Интернет (Weblrbis — см.
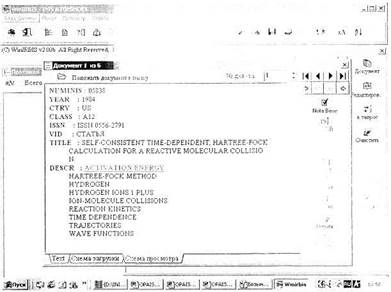
Рис. 2.14. Документ БД INIS в АИПС WinIrbis
рис. 2.16—2.19). АИС Irbis предназначена для многоцелевой обработки больших, в том числе полнотекстовых баз данных разнородных документов неограниченной длины с нерегулярной структурой. Система имеет развитые средства поиска, сортировки и вывода информации, обеспечивая гибкость и эффективность технологий информационного поиска.
Логическая структура данных IRBIS. База данных документальной ИПС IRBIS — это именованная совокупность массива документов и структурированных справочников, обеспечивающих эффективность поиска. Логическая структура БД представлена на рис. 2.15.
Документ базы данных есть структурированная форма представления информации, определяется своим уникальным (в массиве документов базы данных) идентификатором и составом полей.
Поле как часть документа представляет собой однозначно идентифицируемый в информационном массиве фрагмент, для которого определены тип, имя и характер обработки.
Слово как фрагмент поля, выделяемый по формальным (заданным в схеме представления документа) правилам, является единицей информации в операциях поиска.

Рис. 2.15. Логическая структура БД документальной ИПС1
Логическая связь именования, физического размещения и наполнения полей, образующих документ, а также стратегия поиска определяются схемой представления документа. Для одной базы данных может быть определено несколько разных схем, причем их количество не ограничено. Все схемы, используемые для работы с конкретной базой данных, в принципе равноправны. Каждая из них имеет свое имя, хранится в библиотеке схем и может быть одновременно использована для определения документов в нескольких базах данных.
Документ характеризуется в схеме перечислением описаний отдельных полей, для каждого из которых задается:
• идентификация материала в базе данных, обеспечивающая
пользователю доступ средствами документального поиска;
• представление материала при вводе и выводе (формат и длина
поля, размещение и оформление материала при отображении
и т. д.);
• спецификация стратегии документального поиска (прямое
сканирование данных или использование справочников). Для
полей, специфицированных как ключевые, т. е. имеющих по
исковые справочники, дополнительно определяются правила
формирования дескрипторов (заданием списков символов-разделителей слов и списков стоп-слов).
Логически непрерывный массив документов в общем случае размещается в нескольких физических файлах, данные в которых связаны через указатель логического следования. Справочник базы данных размещается отдельно от массива документов и имеет специализированную структуру (частотный словарь, алфавитный индекс и инвертированные списки). Поисковые справочники являются производным по отношению к массиву документов.
Физическая структура базы данных Irbis. В ИПС Irbis используется следующая иерархия понятий:
База данных — некоторый объем файлового физического пространства для размещения данных, принадлежащих одной логической базе.
Файлы БД. Каждая база данных состоит не менее чем из двух типов файлов:
• файлов данных;
• файлов инвертированных структур.
Отдельный файл может принадлежать только одной базе данных.
Экстент. Пространство для хранения данных в БД выделяется блоками (экстентами) по 8 следующих друг за другом страниц размером 8 Кб. Экстент является единицей выделения пространства.
Страница. Файлы делятся на страницы размером по 8 Кб каждая. Логический номер страницы складывается из номера файла и номера страницы в файле (в простейшем случае логический номер равен номеру страницы в файле). В рамках БД файлы нумеруются, начиная с 1, и так же нумеруются страницы в рамках файла.
Словарные инвертированные структуры БД хранятся в отдельной области и включают три типа страниц:
• индексные страницы;
• страницы текстового представления словарных структур;
• страницы инвертированных списков.
Информационно-поисковый язык документальной ИПС Irbis. Информационно-поисковый запрос документальной ИПС представляет собой совокупность отдельных предложений запроса, в общем случае синтаксически и семантически не связанных между собой. Однако, само понятие «Запрос» предполагает объединенную общей тематикой последовательность поисковых действий, направленных на получение обобщенного результата, что позволяет разрешать ссылки на результаты отдельных предложений в рамках текущего запроса, объединять поисковые результаты, выделять общее множество релевантных документов и т. п.
Предложение запроса. Структурной единицей «Запроса» в рассматриваемом ИПЯ является Предложение запроса. Синтаксис Предложения запроса в нотациях Бэкуса-Наура следующий:
<Предложение запроса>::= <Условие поиска> |
<Предложение запроса><Логическая операция><Предложение запроса> |
<Предложение запроса><Логическая операция><Предложение запроса>)
<Логическая операция>::= И | AND | _ | ИЛИ | OR |, | НЕ | NOT | ^
Предложение запроса в общем случае состоит из произвольного числа Условий поиска, связанных логическими операциями И (AND, «пробел»), ИЛИ (OR, «,») и НЕ (NOT, «/ч»). Внутри предложения допускается использование скобок, задающих дополнительные приоритеты выполнения условий поиска.
Условие поиска. Условие поиска устанавливает критерии соответствия поисковых дескрипторов запроса некоторой области поиска, представляющей собой совокупность структурных единиц документа — полей.
<Условие поиска>::=<Область поиска>Оператор критерия><Выражение условия> | <Результат поиска>
Область поиска внутри документа задается именем отдельного поля или логическим выражением, объединяющим имена нескольких полей.
Выражение условия — набор терминов (поисковых дескрипторов), объединенных с помощью булевых или контекстных операторов в логическое выражение.
Оператор критерия задает условие включения или сравнения дескрипторов запроса и терминов, содержащихся в указанных полях документов.
В простейшем случае предложение запроса состоит из имени поля, оператора вхождения и одного дескриптора, например:
KW: РОССИЯ
Область поиска. Область поиска задается именами структурных единиц документа — полей.
<Область поиска>::= <Имя поля>|
(<Область поиска> <Логическая операция> <Область поиска>)
Из нотации видно, что допускается использование логических операций при формировании области поиска. Например:
(АВ OR TI): (РОССИЯ NOT СССР)
означает, что в результат поиска включаются все документы, в которых хотя бы в одном из заданных полей (или в обоих) встречается дескриптор РОССИЯ, но не встречается дескриптор СССР.
Отличительная особенность ИПЯ Irbis — возможность использования логического выражения как в правой, так и в левой части условия поиска.
Оператор критерия. Для связи области поиска с терминами запроса используются следующие операторы критерия (вхождения, сравнения):
<Оператор критерия>::=: | = | EQ | о | NE | > I GT | >= | GE | < | LT | <= | LE
«:» (условие вхождения) — позволяет найти документы, которые содержат в указанной области поиска результат вычисления выражения условия;
«=» (условие «равно», или EQ) — позволяет найти документы, для которых указанная область поиска равна результату вычисления выражения условия;
«О» (условие «не равно», или NE) — позволяет найти документы, которые не содержат в указанной области поиска результат вычисления выражения условия;
«>» (условие «больше», или gt) — позволяет найти документы, которые содержат в указанной области поиска значения большие, чем результат вычисления выражения условия;
«>=» (условие «больше или равно», или GE) — позволяет найти документы, которые содержат в указанной области поиска значения, большие или равные результату вычисления выражения условия;
«<» (условие «меньше», или lt) — позволяет найти документы, которые содержат в указанной области поиска значения, меньшие, чем результат вычисления выражения условия;
«<=>> (условие «меньше или равно», или LE) — позволяет найти документы, которые содержат в указанной области поиска значения, меньшие или равные результату вычисления выражения условия.
Выражение условия. Синтаксис выражения условия в ИПЯ следующий:
<Выражение условия>::= <Дескриптор> |
<Выражение условия> <Операция> <Выражение условия> | (<Выражение условия> <Операция> <Выражение условия>)
<Операция>::= Логическая операция> <Контекстная операция>
<Контекстная операция>::=
CTX|CTX[N]|+|NEAR|NEAR[N]|SENT|CON[N]
 При использовании в запросе нескольких дескрипторов они должны быть связаны контекстными или логическими операторами и помещены в круглые скобки.
При использовании в запросе нескольких дескрипторов они должны быть связаны контекстными или логическими операторами и помещены в круглые скобки.
Для формулировки запроса в И ПС Irbis используются контекстные операторы ctx[N], near[n], sent. Параметр N может принимать значения от 0 до 255 (по умолчанию N равно 0). Отсутствие параметра означает следование терминов в поле непосредственно друг за другом (идентично значению 0).
Оператор СТХ позволяет найти документы, в заданной области поиска которых в одном предложении присутствуют поисковые дескрипторы, расположенные в указанном порядке на расстоянии не более N слов друг от друга. Выражение условия имеет вид:
<дескриптор1> CTX[N] <дескриптор2>
Оператор near позволяет найти документы, в заданной области поиска которых в одном предложении присутствуют поисковые дескрипторы на расстоянии N слов друг от друга (в произвольном порядке). Выражение условия имеет вид:
<дескриптор1> NEAR[N] <дескриптор2>
Оператор sent позволяет найти документы, в заданной области поиска которых поисковые дескрипторы находятся в одном предложении. Выражение условия имеет вид:
<дескриптор1> SENT <дескриптор2>
Контекстный оператор пересечения полей con[n] позволяет использовать в выражении условия имена полей (выступающие в данном случае в роли дескрипторов), содержимое которых сравнивается на предмет отыскания общих терминов.
Оператор пересечения полей служит для отбора документов, в заданных полях которых имеется не менее N одинаковых поисковых терминов. Выражение условия запроса имеет вид:
<имя поля1> CON[N] <имя поля2>
Синтаксис и семантика использования дескрипторов. Поисковые дескрипторы могут быть заданы одним из следующих способов:
• выбор из частотного словаря;
• ввод с клавиатуры;
• отметка ключевых слов в тексте документа;
• выбор терминов из рубрикаторов, словарных или тезаурусных
структур.
При задании поисковых дескрипторов допускается использование операторов (символов) маскирования, алгоритма нормализации и ссылок на ранее полученные результаты поиска.
Маскирование. ИПЯ предполагает применение двух методов:
• маскирование (или замена) произвольного числа рядом стоящих символов дескриптора (символы «*» или «$»);
• маскирование одного (непустого) символа дескриптора (символ «%»).
Символы маскирования могут использоваться вместо любого символа дескриптора, и их количество не ограничено.
Параметризированные символы маскирования произвольного количества символов (например, «*(N)») означают, что в дескрипторе на месте символа маскирования может стоять произвольная последовательность длиной не более чем N символов (где /V изменяется от 0 до 255).
Нормализация. Для расширения возможностей дескрипторного языка на этапе сопоставления ПОД и ПОЗ может быть использован аппарат нормализации дескрипторов.
Используются следующие правила нормализации дескриптора ПОЗ:
1. Три первые буквы дескриптора остаются без изменения.
2. Все следующие гласные буквы заменяются символом маскирования произвольного числа рядом стоящих букв.
3. Конечные буквы в, г, м, х в дескрипторе заменяются символом маскирования произвольного числа рядом стоящих букв.
4. В конце дескриптора проставляется символ маскирования
произвольного числа рядом стоящих букв (если после всех преобразований конечный символ дескриптора не является символом маскирования).
Лингвистическое обоснование такой замены заключается в том, что смыслоразличительная роль согласных во много раз больше, чем гласных. Начальная часть слова включается в новый дескриптор без изменения, поскольку информативность первых трех букв в слове велика. Согласные в, г, м, х могут попадать в дескриптор из окончаний существительных и прилагательных, поэтому их исключение из дескриптора и замена символом маскирования ведет к отсечению окончаний.
Нормализованный таким образом дескриптор ПОЗа позволяет обеспечить более полный дескрипторный поиск с использованием только лишь частотного словаря БД.
 Рассмотрим, например, запрос, который на естественном языке представляет собой предложение: «Частотный анализ терминов словаря». Такой запрос в системе (с применением правил нормализации) автоматически преобразуется в следующий ПОЗ:
Рассмотрим, например, запрос, который на естественном языке представляет собой предложение: «Частотный анализ терминов словаря». Такой запрос в системе (с применением правил нормализации) автоматически преобразуется в следующий ПОЗ:
част$тн$ AND анал$з$ AND терм$н$ AND слов$р$
Нормализованный таким образом ПОЗ обеспечивает поиск по логическому выражению с разрешением символов маскирования:
част$тн$ = частотность, частотности, частотный, частотные, частотных, частотного, частотной;
анал$з$ = анализ, анализа, анализе, анализу, анализируется, анализируются;
терм$н$ = термин, термина, термину, термином, термины, терминов, терминах, терминология, терминологии, терминологию, терминологические, терминологическим, терминологических, терминологической, терминологический, терминосистем, терминологичности;
слов$р$ = словарь, словаря, словаре, словарем, словарей, словарные, словарными, словарных, словарного, словоформа, словоформе, словоформы, словоформ, словарные, словарно-грамматический, словоупотреблений.
Использование ранее полученных результатов поиска. В качестве операнда условия поиска в предложении запроса может использоваться ранее полученный результат поиска:
<Результат поиска>::= # <Идентификатор результата поиска>
Для включения в предложение поискового запроса результатов ранее проведенного поиска используются ссылки на номер предложения в текущем запросе.
Например, запрос может иметь вид:
#2 and ((KW or AB): Россия),
где #2 — ссылка на результат второго предложения запроса.
Символ «#» является индикатором ссылки. За ним указывается номер одного из предыдущих предложений текущего запроса или имя сохраненного запроса, результат поиска по последнему предложению которого используется для уточнения.
Средства формирования запросов. Поисковые механизмы построены на основе ИПЯ, однако технология и средства формирования пользователем запроса не требуют от него обязательного знания и навыков построения выражений алгебраического вида.
Поисковые интерфейсные средства системы Irbis условно можно разделить на два класса.
Первый класс (сценарии типа «укажи и выбери») — это конструкторы запросов, которые позволяют, используя термины поисковых словарей или других поисковых структур (тезаурусов, рубрикаторов, словников), в режиме диалога построить выражение той или иной сложности.
Второй класс — это средства, реализующие простейший сценарий типа «укажи и получи». В этом случае пользователь выделяет в отображаемом объекте (документе или множестве документов) значимые с его точки зрения элементы (термины в документе или словаре; документы в выборке или протоколе) и, используя механизмы поиска по сходству (поиск аналогов, эвристический поиск, поиск с использованием обратной связи), получает выдачу, минуя этап составления поискового выражения.
В основу формирования поискового запроса по технологии «укажи и выбери» в системе положено три различных подхода, ориентированных на разные степени подготовленности пользователя.
Конструктор запроса «по образцу» реализует традиционный для библиографического поиска форматно-ориентированный интерфейс, имеет жестко фиксированную модель поискового условия, предполагающую обязательное выполнение частных условий, связанных с полями, выбираемыми из предопределенного списка. По умолчанию предполагается, что отдельное условие — это список терминов (синонимов), обычно выбираемых из словаря и обозначающих одно и то же понятие.
Конструктор формирования запроса «по шагам» характеризуется большей гибкостью. Здесь поисковые термины также выбираются из словаря, но могут связываться любыми отношениями. Причем, построенные таким образом лексические выражения, относимые к отдельным полям, в свою очередь могут связываться операторами, выбираемыми из списка. Такой конструктор позволяет формировать достаточно сложные предложения запроса последовательным наращиванием либо выражения условия (путем добавления очередного термина), либо всего предложения (путем добавления нового условия поиска). Необходимо отметить, что для сложных предложений запроса необходима достаточно хорошая предварительная структуризация.
Конструктор формирования логического выражения запроса путем непосредственного набора выражения запроса с возможностью обращения в произвольном порядке к словарям, спискам имен полей и т. д.
На рис. 2.16—2.19 приведен пример последовательности экранов при простейшей формулировке запроса — один термин из общего (ALL) частотного словаря. Поиск производится в базе данных «Экономика и демография» ИНИОНРАН, Web-адрес — www.inion.ru
 Рис. 2.16.Исходная страница при доступе к БД по экономике и демографии ИНИОН посредством ППП WebIrbis
Рис. 2.16.Исходная страница при доступе к БД по экономике и демографии ИНИОН посредством ППП WebIrbis
|
|
Рис 2.17. Запрос на поиск в частотном словаре БД Irbis. Ключевое слово — РЕФОРМЫ

|
Рис. 2.18. Просмотр фрагмента частотного словаря БД начиная со слова РЕФОРМЫ

|
Рис. 2.19. Экран просмотра результатов поиска в Weblrbis (библиографическая запись, содержащая словосочетание ЭКОНОМИЧЕСКИЕ РЕФОРМЫ)
Дата добавления: 2015-07-20; просмотров: 154 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Физическая структура и навигация в документальной БД | | | Документальный информационный поиск в сети Интернет |