Читайте также:
|
Поскольку в данном случае БД является информационной моделью определенной предметной области, существенной особенностью всякой БД является структура или, как принято говорить, модель данных (МД).
Рассмотрим некоторые наиболее известные (или «замечательные» [1, 5]) модели данных.
Иерархическая МД (ИМД). Впервые реализована в СУБД IBM -— IMS (Information Management System), разработанной для поддержки банка данных по программе Apollo. При данном подходе предметная область представляется в виде совокупности структур иерархического типа (граф — «дерево»).
Основные понятия ИМД:
• поле — минимальная единица данных;
• сегмент (узел) — совокупность полей, являющаяся единицей
обмена между БД и прикладной программой. Сегмент (узел иерархического графа) более высокого уровня называется исходным (родительским) по отношению к ниже расположенному порожденному (отпрыску). Может использоваться также терминология «узел, принадлежащий вышестоящему узлу». Конкретные данные, входящие в сегмент называются экземпляром сегмента.
В ИМД существуют также следующие понятия:
• брат — узел, имеющий того же родителя, что и другой узел;
• ветвь — узел дерева вместе со всеми его отпрысками, отдаленными потомками и родительскими источниками;
• лист — узел, у которого нет отпрысков;
• обход дерева — процесс обследования по очереди каждого узла
дерева в иерархической модели данных, и пр.
Преимущества IMS и реализованной в ней иерархической модели:
1. Простота модели. Принцип построения IMS легок для пони
мания. Иерархия базы данных напоминает структуру компании или
генеалогическое дерево.
2. Использование отношений предок/потомок. СУБД IMS позволяла легко представлять отношения предок/потомок, например: «А
является частью В» или «А владеет В».
3. Быстродействие. В СУБД IMS отношения предок/потомок
были реализованы в виде физических указателей от одной записи к
другой, вследствие чего перемещение по базе данных происходило
быстро. Поскольку структура данных в этой СУБД отличалась простотой, IMS могла размещать записи предков и потомков на диске
рядом друг с другом, что позволяло свести к минимуму количество
операций записи-чтения.
Существенно то, что физическая организация БД в этом случае такова, что выбрать конкретные сведения об объектах можно, лишь пройдя всю цепочку групп (сегментов) сверху вниз (путь на иерархическом дереве). Данная схема наиболее проста, но не лишена очевидных недостатков.
В частности, в связи с полииерархичностью связей объектов в реальном мире в подобных БД необходимо создавать и поддерживать несколько иерархических отношений, что нарушает основную идею модели данных. Далее, рассматриваемая модель обладает рядом т. н. «парадоксов», наиболее очевидным из которых является «парадокс исключения». Удаление из БД некоторого вышестоящего сегмента приводит к автоматическому удалению и всех зависимых (порожденных сегментов).
Сетевая модель данных (модель CODASYL). В предложенной CODASYL модификации иерархической модели одна запись могла участвовать в нескольких отношениях предок/потомок. В сетевой модели такие отношения называются множествами (set). В 70-е гг. независимые производители программного обеспечения реализовали сетевую модель в таких продуктах, как IDMS компании Cullinet, Total компании Cincom, которые приобрели большую популярность. Сетевые БД обладали рядом преимуществ:
1. Гибкостью. Множественные отношения предок/потомок позволяют сетевой БД хранить данные, структура которых сложнее
обычной иерархии.
2. Стандартизованностъю. Появление стандарта CODASYL.
3. Быстродействием. Вопреки своей сложности, сетевые БД достигали быстродействия, сравнимого с быстродействием иерархических БД. Множества были представлены указателями на физические записи данных, и в некоторых системах администратор мог задать кластеризацию данных на основе множества отношений.
Недостаток — жесткость БД, наборы отношений и структуру записей приходилось задавать заранее. Изменение структуры данных означало перестройку всей БД.
Реляционная модель данных (РМД). В то время как иерархическая модель в своей основе является формализацией и обобщением пользовательских свойств некоторой конкретной системы (IMS), в случае реляционной модели сначала были разработаны некоторые математические основы и лишь через 5—10 лет появились первые коммерчески эффективные системы. В рамках реляционной модели предметная область представлена совокупностью таблиц (отношений, файлов).
Строки таблицы называются экземплярами отношения, столбцы — атрибутами] каждый атрибут имеет область значений, называемую доменом.
Важным отличием РМД от ИМД является возможность применения формального аппарата, описывающего преобразование и обработку данных в РМД — реляционной алгебры.
Операндами реляционной алгебры являются отношения, как постоянные, так и переменные.
Операции реляционной алгебры включают следующие преобразования отношений.
А. Теоретико-множественные операции над несколькими подобными (имеющими одинаковую структуру — число атрибутов, их имен, домен и т. д.), отношениями, в том числе объединение, пересечение, разность.
Б. Операции над одним отношением:
• селекция, или построение отношения-результата из отношения-источника путем отбора экземпляров, удовлетворяющих
некоторому критерию отбора. Операция селекции соответствует поиску информации в БД по логическим условиям (см.
табл. 2.2 - FIND... WITH, FIND...WHERE, LOCATE);
• проекция, или построение результирующего отношения путем
отбора части атрибутов всех экземпляров исходного отноше
ния. Данной операции в реальных СУБД соответствует поня
тие пользовательской подсхемы и операции выдачи необходи
мых данных (см. табл. 2.2 - DISPLAY, VIEW, SET FORM TO,
REPORT FORM...).
В. Операции над несколькими различными отношениями.
Рассмотрим только естественное соединение (в дальнейшем — соединение). Операция заключается в поиске в паре (или большем числе) отношений строк, содержащих общий атрибут, и создания из этих строк экземпляра результирующего отношения.
В СУБД соединению соответствует поиск связанных данных или логическое (физическое) связывание файлов (см. табл. 2.2 — FIND...COUPLED, SET RELATION TO, JOIN).
Реляционная алгебра позволяет рассматривать операции ввода, вывода, поиска коррекции и удаления данных в БД как вычисление отношений-результатов через исходные отношения. При этом исходным отношением может быть внешний (входной) формат данных, а результирующим — внутренний (хранимый) или, наоборот, исходным — внутренний, а результирующим — внешний (выходной).
Модель «сущность—связь» (Entity—Relationship, ER) [5], представляет собой обобщение РМД путем разделения отношений, описывающих предметную область на две группы — сущностей и связей.
Сущность (Entity) является первичным, устойчивым объектом, описываемым некоторой совокупностью атрибутов.
Связь (Relationship) является вторичным понятием, характеризующим взаимодействие в пространстве и времени двух или более сущностей, и также задается рядом атрибутов, среди которых присутствуют идентификаторы взаимосвязанных сущностей. При проектировании БД на основе ER-моделей используют ЕR-диаграммы. Модель ER является удобным средством описания предметной области перед тем, как перейти к ее представлению в реляционной модели данных.
Иерархическая МД в настоящее время представляет лишь исторический интерес, хотя ряд ее элементов и" поддерживается некоторыми из рассматриваемых далее конкретными СУБД.
Наиболее распространенными являются подходы, базирующиеся на ER-модели и РМД.
Основные представления о структуре БД в рамках указанных моделей заключаются в следующем:
а) совокупность сущностей и связей образует концептуальную
схему базы данных и отражает структуру предметной области. Элементами схемы являются типы (классы) сущностей и связей; типы
состоят из экземпляров, описывающихся значениями атрибутов.
На рис. 2.1 приведен пример фрагмента диаграммы «сущность—связь», описывающей учебный процесс вуза. Здесь сущностями являются ФАКУЛЬТЕТ, ДИСЦИПЛИНА, СПЕЦИАЛЬНОСТЬ (с возможными атрибутами, например, НАИМЕНОВАНИЕ, ПРОДОЛЖИТЕЛЬНОСТЬ ОБУЧЕНИЯ, ЧИСЛО ЧАСОВ и пр.) Связями являются ВЫПУСКАЕТ, ВКЛЮЧАЕТ (возможные атрибуты - КВАЛИФИКАЦИЯ, СЕМЕСТР ОБУЧЕНИЯ и пр.);
б) концептуальная схема трансформируется в логическую схему,
в которой сущностям и связям соответствуют отношения или логические файлы, состоящие соответственно из экземпляров отношений и
логических записей.
Логическая запись является более общим образом, чем отношение (строка данных), поскольку допускает появление групповых полей (или агрегатных данных), соответствующих некоторым зависимым сущностям (или связям).
В повторяющемся групповом поле экземпляр группы есть описание экземпляра сущности (связи) посредством соответствующих атрибутов. Групповые повторяющиеся поля представляют собой элемент иерархической модели данных, который при желании может применяться пользователями;
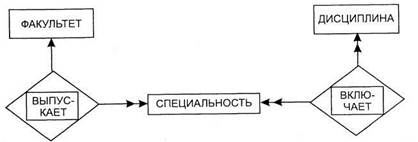
|
| Рис. 2.1 Пример диаграммы «сущность—связь» |
в) следующий уровень — физическая реализация БД в форме
файлов операционной системы ЭВМ. При этом в различных конкретных системах логическому файлу может отвечать один или более физических файлов (или наоборот); физическая запись, как правило, включает одну или более логических записей;
г) уровень представлений пользователя описывает БД в виде совокупности пользовательских подсхем, которые применяются для ввода/вывода информации. С представлениями пользователя связаны также понятия маски редактирования (преобразования данных при окончательном представлении пользователю), и кодирования/декодирования (трансляции кодов) — расширения кратких представлений данных и аббревиатур с помощью вспомогательных файлов и кодовых таблиц (по своей сути — операция соединения отношений в РМД).
Дата добавления: 2015-07-20; просмотров: 143 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| БАЗОВЫЕ ТИПЫ ИНФОРМАЦИОННЫХ СИСТЕМ | | | Табличные базы данных |