|
Читайте также: |
Сонымен, алдыңғы параграфтан шығатын қорытынды - «компьютер архитектурасындағы параллельділік – бұл уақытша емес, ол мәңгі – бақилық» десе болады. Қазіргі жаңа технологиялар мыңдаған процессорларды бір ғана есептеу жүйесіне жеңіл түрде біріктіруге мүмкіндік береді. Алайда, паралель компьютерлерді қолданудың осы уақытқа дейінгі тәжірибесі оларды толық игерудің идеал жағдайлардан қашық екендігін көрсетеді.
Іс жүзінде барлық дерлік жағдайда келесі тұжырым орынды: «компьютердің архитектурасындағы параллельділік дәрежесін көтеру оның шектік өнімділігінің жоғарылауына алып келуімен қатар, бір мезгілде шектік өнімділігі мен нақты өнімділігі арасындағы айырмашылықтың да артуына әкеледі». Бұл түсінікті де, мысалға, барлық бағдарламалар ILLIAC IV компьютерінің барлық 64 процессорлық элементін бірдей тиімді қолдана алмайтыны анық.
Егер бағдарлама векторлық түрге келмесе, онда ол Gray сияқты векторлы-конвейерліқ машиналарының архитектурасындағы артықшылықтарын толық қанды пайдалана алмайды.
Кейде алгоритм структурасы оны тиімді іске асыруға мүмкіндік бермейді, бірақ мұндай жағдайлар жиі кездесе бермейді. Көп жағдайда бағдарламаның нақты өнімділігін жоғарылатуға болады, бірақ бұл процестің қиыншылығы есептеуіш жүйенің аппараттық-бағдарламалық ортасының параллельділікті қаншалықты қолдай алатынына тікелей байланысты. Бұл жерде барлығы маңызды: операциялық жүйелер және компиляторлар, параллель бағдарламалау технологиясы және бағдарламаның орындалу уақыты жүйелері, процессордың параллелизмді қаншалықты қолдауы және жадымен жұмыс істеу ерекшеліктері. Егер бір нәрселер ескерілмеген, қарастырылмаған жағдай бола қалса, онда тиімді бағдарламаны алу үшін қолданушының өзі қамдану керек: егер компилятор нашар болса, онда ассемблер тілінде жазу керек, егер аппараттық деңгейде әртүрлі процессорлардағы кэш жадыларда сақталған мазмұндарда келіспеушілік болса, онда кэш жадыны босататын арнайы функциялар тұрақты түрде кодқа қойылады және т.б.
Қазіргі таңда, компьютердің бағдарламалық – аппараттық ортасындағы паралельділікті қолдауда айрықша мәнді тәжірибе жинақталды десе болады. Осы ортаның «параллель» бөліктерімен танысумен қатар, сұрақтың кері жағының да маңыздылығы кем емес. Егер бағдарламаның тиімділігі төмен болса, онда оның себебі барлық жерде жасырынып тұруы мүмкін. Бұл үшін бір дегеннен пайдалынылған алгоритмге немесе өзіміздің бағдарлама құру қабілетімізге ренжіп қажеті жоқ.
Бұған себепші нашар компилятор немесе оны дұрыс пайдаланбау, аппаратура деңгейінде жадыға қатынастың бұғатталуы, нашар іске асырылған параллельді енгізу/шығару, коммуникациялық ортадан пакеттердің өтуі кезіндегі қақтығыстар – компьютердің бағдарламалық-аппараттық ортасының әрбір құраушысы бағдарлама жұмысына өз үлесін қосады, ал ол жақсы ма әлде жаман ба, ол басқа сұрақ.
Сонымен, бағдарлама жұмысының тиімділігін көтеру туралы айтатын болсақ, бірінші - арнайыпроцессорларды құрастыру жайында айтылу керек.
Компьютер архитектурасын құрастырушылардың алдында әрдайым дилемма қойылады: қандай да бір операцияны аппаратура деңгейінде ұйымдастыру керек пе, әлде бұл функцияны бағдарламалық жабдыққа жүктеу қажет пе.
Аппаратура жағынан демеу (процессордың арнайы командалар жүйесі, жадтың ерекше құрылымы, разрядтылық, деректерді беру (көрсету) тәсілдері, ішкі процессорлық коммуникацияның топологиясы және т.б.) анықталған операциялар жинағын орындау жылдамдығын арттыруда көп ұтымды болады Алайда, егер процессор байттық бүтін сандарды өте тиімді өңдей алатын болса, онда ол бір разрядты деректердің үлкен массивтерімен, я болмаса жылжымалы нүктелі нақты сандармен де соншалықты тиімді жұмыс істей алады деп анық айта алмаймыз. Алгоритмдер әртүрлі, ал архитектурада бәрін алдын–ала ескеру (көрсету) мүмкін емес, сондықтан да құрастырушыларға әмбебаптық және мамандандырылу арасында компромисс іздеуге тура келеді. Осы жайында есептеуіш құрылғылардың өлшемдері мен олардың бағалары да ойлануға мәжбүр етеді.
Арнайы процессорлардың жоғары мамандандырылуын ескерсек, олардың өнімділік көрсеткішін бағалау аса үлкен ұқыптылықты қажет ететіні айқын.
Арнайы процессорлардың қолданылу бағыттары кең - сигналдарды өңдеу, сөзді тану, бейнені және сейсмологиялық деректерді талдау, графикалық үдеткіштер және т.б. Нақты алгоритмдердің ерекшеліктерін тиімді пайдалана отырып, арнайы процессорлар көптеген (жүздеген, мыңдаған, он мыңдаған, жүз мыңдаған) параллель жұмыс істейтін элементар функциональді құрылғыларды біріктіреді. Мұнда үлкен иілгіштік жоқ, оның орнына үлкен жылдамдықпен жұмыс істеу мүмкіндігі бар.
Алғашқылардың бірі және осы уақытқа дейін кең қолданыста жүрген арнайы процессорлардың қатарына, Фурье түрлендіруін тез іске асыруға аппараттық қолдау негізінде құрылған процессорларды жатқызуға болады. Пайдаланушыдан жасырын параллельділік - машиналық команда деңгейіндегі параллельділікті (Instruction–Level Parallelism) пайдалану идеясы параллельділіктің даму бағытына қызықты серпін берді. Пайда өте көп, олардың ішіндегі ең бастыларының қатарына пайдаланушыға арнайы параллель бағдарлама жасау қажеттілігінің жоқтығын айтуға болады. Сонымен қатар, мұнда тасымалдау мәселесі тізбекті машиналар класындағы бағдарламаны тасымалдаудың жалпы мәселелерінің деңгейінде қалады.
Машиналық команда деңгейінде параллельділкті пайдаланатын процессорлар архитектурасын құрудың негізгі екі жолы бар. Екі жағдайда да процессор бір-біріне тәуелсіз жұмыс жасай алатын бірнеше функционалдық құрылғыдан тұрады деп есептеледі және бұл құрылғылардың бірдей немесе әртүрлі екені маңызды емес.
Суперскалярлық процессорлар машиналық команда терминіндегі программа құрамында параллельділік туралы қандай да ақпараттың болуын қажет етпейді. Мұнда, машиналық кодтағы параллельділікті байқау, анықтау есебі аппаратқа жүктеледі және ол, сәйкесінше, командалардың орындалу тізбегін тұрғызады.
Тәжірибе жүзінде VLIW–процессорлары (Very Large Instruction Word) негізінен фон-неймандық компьютері ережесімен жұмыс істейді. Айырмашылығы: процессорге әр цикл сайын берілетін команда, бір ғана операцияны емес, бірден бірнешеуін анықтайды.
VLIW-процесорының командасы өрістер жиынтығынан тұрады, олардың әрқайсысы өзінің операциясына жауап береді, мысалы, функционалды құрылғыларды активтеу, жадпен жұмыс істеу, регистрлермен операция және т.б. Егер процессордың қандай да бір бөлігі, бағдарламаның орындалуы барысының ағымды этапында қажет етілмесе, онда команданың оған сәйкес өрісі әрекет етпейді.
Осыған ұқсас архитектуралы компьютерлер қатарына Floating Point Systems фирмасының АР–120В компьютерін мысалға келтіруге болады. Оны алғаш пайдалану 1976 жылы басталып, 1980 жылы дүние жүзі бойынша 1600 –ден аса данасы орнатылды. АР–120В компьютерінің командасы 64 разрядтан тұрады және ол машинаның барлық құрылғыларының жұмысын басқарады. Әрбір тактіде (167 нс) бір команда беріледі, бұл бір секунд ішінде 6 миллион команданың орындалуына эквивалентті. Әрбір команда бір уақытта бірнеше операцияларды басқара алатындықтан, нақты өнімділік жоғары болуы мүмкін. АР–120 В командасының барлық 64 разряды, әрбірі өз операциялар жиынына жауап беретін алты топқа бөлінеді: 16-разрядты бүтін санды берілгендер және регистрлермен операциялар, нақты сандарды қосу, енгізу/шығаруды басқару, өту командалары, нақты сандарды көбейту және басты жадтағы жұмыс командалары.
VLIW-процессоры үшін бағдарлама әрқашанда параллельділік туралы нақты, дәл ақпаратты қамтиды. Мұнда, компилятор, әрдайым бағдарламадағы параллельділікті өзі анықтап, қандай операциялар бір-біріне тәуелсіз екені туралы ақпаратты аппаратураға айқын түрде хабарлайды.
VLIW-процессорына арналған кодта процессордың бағдарламаны қалай орындайтыны туралы нақты жоспары енгізілген: әр операция қай кезде орындалады, қандай функционалды құрылғылар жұмыс істейді, қандай регистрлерге қандай операндтар кіреді және т.б.
Екі бағыттың да өз артықшылықтары мен кемшіліктері бар және де VLIW архитектурасының шектелген мүмкіндіктері мен қарапайымдылығына суперскаляр жүйелердің күрделілігі мен динамикалық мүмкіндіктерін қарсы қоюдың қажеті жоқ. Әрине, компиляция кезінде операцияның орындалу жоспарын құру, суперскалярлық жүйелер үшін де жоғары дәрежедегі параллелділікті қамтамасыз ету үшін маңызды екені айқын. Сонымен бірге, компиляция кезінде бірмәнді еместік туындайды, оны суперскалярлы архитектураға тиісті динамикалық механизмдер көмегімен тек қана бағдарламаның орындалуы кезінде ғана шешуге болады.
50–ші жылдардың соңында суперскалярлық өңдеу идеясының дамуына IBM фирмасының STRECH жобасы үлкен ықпал етті, қазіргі таңда көптеген микропроцессорлардың архитектурасы осы қағидаға сүйеніп құрылған. VLIW-компьютерінің айқын өкілдері: Multiflow және Cydra компьютерлері ұрпағы.
Жоғарыда келтірілген екі қағида да жеке процессорлардың өнімділігін арттыруға қатысты, олардың негізінде өз кезегінде көппроцесссорлы конфигурациялар құруға болады. Параллель компьютерлердің архитектурасы компьютерлік индустрияның пайда болуынан бастап, адам нанғысыз темппен және әртүрлі бағыттарда дамуда [24].
Дегенмен, егер детальдарын ескермей, ал кейінгі басым көпшілік параллель есептеу жүйелерінің жалпы құрылу идеясын бөліп қарастыратын болсақ, онда тек екі класс қана қалатынын көреміз.
Бірінші класс – бұл ортақ (жалпы) жадылы компьютерлер. Осы принциппен құрылған жүйелерді әдетте мультипроцессорлық жүйелер немесе жай мультипроцессорлар деп те атайды. Жүйеге, ортақ жадыға қатынауға тең құқылы бірнеше процессорлар кіреді (12 сурет).

12 сурет. Ортақ жадылы параллель компьютерлер
Барлық процессорлар өзара жалпы жадыны «бөледі», осы себепті бұл класқа жататын компьютерлердің тағы бір атауы - бөлінген жадылы компьютерлер. Барлық процессорлар ортақ адрестік кеңістікте жұмыс істейді: егер бір процессор 1050 адресі бойынша, сөзде 61 мәнін жазса, онда басқа процессор 1050 адресінде орналасқан сөзді оқып, 61 мәнін қабылдап алады.
Екінші класс – бұл таратылған жадылы компьютерлер, кей кезде оларды мультикомпьютерлі жүйелер деп те атайды (13 сурет).

13 сурет. Таратылған жадылы параллель компьютерлер
Әрбір есептеу торабы өзінің процессорымен, жадысымен, енгізу/шығару ішкі жүйелерімен және операциялық жүйесімен бір бүтін компьютер болып саналады. Бұл жағдайда, егер бір процессор 1024 адресі бойынша 79 мәнін жазса, онда сол адрес бойынша басқа процессордың не оқығанына әсері жоқ, себебі, олардың әрқайсысы өз адрестік кеңістігінде жұмыс істейді.
Ортақ жадылы компьютерлерге Symmetric Multi Processors (SMP) класының барлық жүйелері жатады. SMP жүйесінде бірнеше процессорлардан басқасынан бәрі бір экземплярдан: бір жады, бір операциялық жүйе, бір енгізу/шығару бағыныңқы жүйесі. Архитектураның аталуындағы «симметриялық» сөзі, әрбір процессор басқа процессорлар атқара алатын барлық қызметті атқара алады дегенді білдіреді.
Қазіргі уақытта, көбіне SMP-ны ортақ жадылы компьютерлер үшін альтернативті атау ретінде қарастырады. Бұған SMP-ның мүмкін болатын екі шартбелгіні ашу нұсқасы да қосымша демеу болды: Symmetric Multi Processors және Shared Memory Processors.
Бұл екі класс ортақ және таратылған жадылы компьютерлер кластары кездейсоқ пайда болған жоқ. Олар параллель есептеудің негізгі екі есебін көрсетеді.
Ең бірінші мәселе максимальді өнімділік беретін есептеу жүйесін құру болып табылады. Бұны таратылған жадылы компьютер көмегімен жеңіл шешуге болады. Қазіргі уақытта бірыңғай коммуникациялық орта аясында бірнеше мыңдаған есептеу тораптарын біріктіретін қондырғыларды пайдалану жүзеге асуда. Тіпті Интернеттің өзін миллиондаған есептеу тораптарын біріктіріп отырған таратылған жадылы ең үлкен параллельді компьютер деп қарауға болады. Бірақ, осындай жүйелерді қалай тиімді пайдалануға болады? Параллель жұмыс істейтін процессорлардың ара-қатынасына жұмсалатын шығындарды қалай жоюға болады? Параллель бағдарламаларды құруды қалай ықшамдауға, жеңілдетуге болады? Тәжірибе жүзінде осындай жүйелерді бағдарламалаудың бірден-бір әдісі - бұл хабар алмасу жүйесін пайдалану, мысалы PVM немесе MPI, бірақ әрдайым оңай бола бермейтінін ескеру керек.
Осыдан келіп екінші мәселе туындайды - параллельді есептеу жүйелері үшін тиімді бағдарламалық қамтамасыздандыруды құрудың әдістерін іздеу.
Бұл мәселе ортақ жадылы компьютерлер үшін біраз жеңіл шешімін табады. Ортақ жады арқылы процессорлар арасындағы мәлімет алмасудағы қосымша шығындар минимальды болады, ал мұндай жүйелерді бағдарламалау технологиясы қарапайым болып табылады. Мұндағы мәселе басқада. Технологиялық себептерге байланысты, ортақ жедел жадылы, саны көп процессорларды біріктіру мүмкін болмайды, сондықтан мұндай жүйелерде қазіргі кезде өте үлкен өнімділік ала алмайсың.
Байқасақ, екі жағдайда да процессорларды жады модулдерімен немесе процессорларды өзара байланыстыратын коммутация жүйесі көп қиындықтар туғызады. Мысалға, 32 процессор жалпы жедел жадтқа тең қатынас жасай алады немесе 1024 процессордың әрқайсысы өзара байланыса алады деу әрине оңай, бірақ тәжірибе жүзінде мұны қалай жүзеге асыру керек? Енді компьютерлерде қатынастық жүйелерді ұйымдастырудың кейбір әдістерін қарастырайық.
Мультипроцессорлы жүйелерді ұйымдастырудың ең қарапайым әдістерінің бірі процессорлар да, жады да қосылатын жалпы шинаны қолдануға негізделген (14 сурет).
Шинаның өзі қандай да бір тізбектер санынан тұрады. Бұл тізбектер, процессорлар мен жады арасында адрестер, деректер және басқарушы сигналдармен алмасу үшін қажет болып табылады.
Бірнеше процессорлардың жадымен бір уақытта қатынас жасауын болдырмау үшін, шинаны иеленген құрылғының шинаға дара иелік жасауына кепіл болатын арбитраждың қандай да бір сызбасы пайдаланылады.
Осындай жүйелерде туындайтын негізгі қиындық (мәселе) – шинадағы құрылғылар санының шамалы өсуі (4-5), оны тез арада «тар орынға» айналдырады, ал ол өз кезегінде жадпен деректер алмасу кезіндегі айқын бөгелістерге және жалпы жүйе өнімділігінің апаттық құлдырауына әкеліп соғады.
Бұдан да қуатты жүйелер құру үшін басқа жолдар іздеу қажет. Соның бірі – жадыны тәуелсіз модульдерге бөлу және әртүрлі процессорлардың басқа модульдарға бір уақытта қатынау мүмкіндігін қамтамасыз ету. Мұнда шешімдер көп болуы мүмкін, дербес жағдайда, мысалы, матрицалық коммутаторды пайдалану. Процессорлар және жады модульдері 15-ші суретте көрсетілгендей байланысады. Тізбектер қиылысында процессорлар және жады модульдері арасында ақпарат алмасуға рұқсат ететін немесе ақпарат алмасуға тыйым салатын элементарлық нүктелі айырып/қосқыштар орналасқан. Мұндай ұйымдастырудың басты артықшылығы, процессорлардың бір мезгілде, жадының әртүрлі модульдерімен жұмыс істей алу мүмкіндігі. Әрине, егер екі процессор бір жады модулімен жұмыс істегісі келсе, онда екеуінің біреуі бұғатталады. Матрицалық коммутаторлардың кемшілігі – қажетті құрылғының үлкен көлемді болуы, мысалы, n процессорларды n жады модульдерімен байланыстыру үшін n2 элементарлы айырып/қосқыштар қажет. Көп жағдайларда бұл өте қымбат шешімдерге жатқызылады, сондықтан құрастырушыларды басқа жолдарды іздеуге итермелейді.

14 сурет. Ортақ шиналы мультипроцессорлық жүйе.
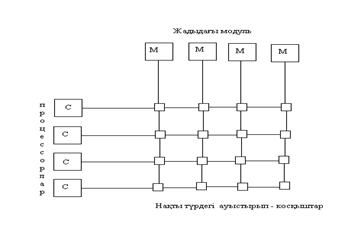
15 сурет. Матрицалық коммутаторлардағы
мультипроцессорлық жүйе.
Каскадты айырып/қосқыштарды пайдалану – альтернативті әдіс болып есептеледі, мысалы, омега – желі жасалғандай. 16-суретте екі каскадта ұйымдасырылған, 4 коммутатордан 2*2 тұратын желі көрсетілген.
Әрбір пайдаланылған коммутатор өзінің кезкелген екі кірісін, өзінің кез–келген екі шығысымен байланыстыра алады. Бұл қасиет және пайдаланылған коммутация сызбасы осы суретте көрсетілген кезкелген есептеу жүйесінің процессорына жадының кезкелген модулімен қатынасуға мүмкіндік береді. Жалпы жағдайда n процессорды жадының n модулімен байланыстыру (жалғау) үшін, әрбірінде n/2 коммутатор болатын log2n каскад қажет етіледі, яғни жалпы алғанда барлығы (nlog2n)/2 коммутатор.
Үлкен n мәндері үшін бұл шама n2 қарағанда едәуір жақсы, бірақ басқа түрдегі қиындық туындайды – олар бөгелулер. Әрбір коммутатор лезде қосыла алмайды, себебі әрбір каскадта кіріс пен шығысты коммутациялауға біраз уақыт қажет етіледі. Тағы да айырып/қосылу уақыты үлкен емес қымбат қатынас жүйесі және үлкен бөгелістерге ие қымбат емес жүйелер арасындағы компромисс ізделінеді.


16 сурет. Омега - желі мультипроцессорлық жүйесі.
Біз процессорлардың жады модульдерімен байланыс түрлерін толық қарастырған жоқпыз. Негізінде таратылған жадылы жүйелердегі нақты пайдаланылатын процессорлар коммутациясының сызбалары едәуір көп.
17, а -суретте, барлық есептеу тораптары бір сызық бойына біріктірілген қарапайым нұсқадағы байланыс топологиясы келтірілген. Жүйенің бірінші және соңғысынан басқа әрбір торабының оң және сол жақтарында көршілес тораптар орналасады. n тораптан тұратын жүйені тұрғызу үшін жүйеге n-1 байланыс қажет. Жүйенің екі торабының арасындағы жолдың орташа ұзындығы n/3 –ке тең. Егер есептеу тораптарының сызықты түрін дөңгелек түрге өзгертсе, онда жолдың орташа ұзындығын азайтуға болады (17 б сурет). Сонымен, жүйедегі бірінші торапты соңғысымен қосымша байланыстыру арқылы, біз шын мәнінде жаңа топологияда қосымша пайдалы екі қасиет аламыз. Біріншіден, екі торап арасындағы жолдың орташа ұзындығы n/3 -тен n/6 -ға дейін қысқарады. Екіншіден, кез-келген тораптар арасындағы ақпарат алмасу екі тәуелсіз бағыт арқылы жүргізілуі есебінен, жүйенің жалпы істен шығуға тұрақтылығы артады. Әзірге барлық байланыс жұмысқа жарамды болып тұрғанда, ақпарат беру (алмасу) қысқа жолмен жүретін болады. Ал егер, қандай да бір байланыс бұзылатын болса, онда беру қарама-қарсы бағытта болуы мүмкін.

17 сурет. Мультикомпьютерлерлік жүйелер байланыс топологияларымен: а – сызықша; б – дөңгелек; в – жұлдызша
Тікелей байланыстардың айқын шектелуіне қарамастан, тек көрші процестердің өзара байланысы қажет болатын ұқсас қарапайым «сызықты» топологиялар көптеген алгоритмдерге жақсы сәйкес келеді. Атап айтқанда, математикалық физиканың көптеген бірөлшемді есептері (және көпөлшемді есептер аймақты бірөлшемділерге бөлу арқылы) осындай ұқсас әдістермен жақсы шешіледі. Бұндай есептер үшін ешқандай басқа топологияларды ойлап табудың қажеті жоқ. Алайда, барлық есептер мұндай бола бермейді. Бұндай топологияларға қосарлану схемасын немесе сызықты алгебраның блоктық әдістерін тиімді іске асыру оңай емес, өйткені процестерді процесссорлар бойынша дұрыс орналастырмау уақыттың көп бөлігін қатынасқа (коммуникацияға) жоғалтуға әкеліп соғады. Идеалды жағдайда пайдаланушы бұл туралы ойламау керек, онда басқа да проблемалар жеткілікті болары анық, бірақ іс жүзінде ғажайыптар болмайды. Қазіргі таңда технологиялық себептерге байланысты, әрбір процессоры басқа барлық процессорлармен тікелей байланыста болатын үлкен мультикомпьютерлік жүйелерді жасауға болмайды. Олай болса, мұнда да, есептеу жүйелерін құрастырушыларға әмбебаптық пен мамандандырылғандықтың, күрделілік пен қолжетімділік арасындағы ымыраға келуді іздеуге тура келеді. Егер есептер класы алдын-ала анықталған болса, онда жағдай көп жеңілденеді де нәтиже жеңіл табылуы мүмкін.
Мысалы, параллель процестер арасында жұмысты бөлу сызбасын пайдалану, клиент-сервер сызбасындағы сияқты бір басты процесс бағыныңқы процестерге тапсырма тарататын (шебер/жұмысшылар схемасы немесе mаster/slaves), «жұлдыз» топологиясына (17, в сурет) жақсы сәйкес келеді. Жұлдыз сәулелерінде орналасқан есептеу тораптары өзара тікелей тәуелді байланыста болмайды. Бірақ бұл шебердің орталық торапта орналасу шартына байланысты процесс-шебердің бағыныңқы процестермен тиімді өзара байланысуына ешқандай да кедергі жасамайды.
Нақты есептеу жүйесінде процессорлар байланысы топологиясының қандай да бір түрлерін таңдап алу әртүрлі себептерге тәуелді болуы мүмкін. Бұл дегеніміз - технологиялық іске асыру, бағдарламалау мен жинау қарапайымдылығы, сенімділігі, тораптар арасындағы орташа жолдың минималды болуы, тораптар арасындағы максималды жолдың минималды болуы, бағасының қолжетімдігі т.б.
Кейбір нұсқалар 18-ші суретте көрсетілген. Екі өлшемді тордың топологиясы (18, а - сурет) өткен ғасырдың 90-жылдарының басында i860 процессорлары негізінде Intel Paragon суперкомпьютерін құрастыруда пайдаланылған. Екі өлшемді тор топологиясына сәйкес (18, б – сурет), Dolphin Interconnect Solutuions компаниясы ұсынған SCI желісін пайдаланатын кластерлердің есептеу тораптары байланыстырылуы мүмкін. Осылайша, МГУ НИВЦ (Россия) кластерлерінің біреуі құрылған. Қазіргі таңда Dolphin компаниясы тораптарды үш өлшемді торға біріктіруге мүмкіндік беретін желілік кешенді ұсынуда. Тораптар арасындағы орташа ара-қашықтық неғұрлым аз болса, соғұрлым сенімділігі жоғары болады. Яғни, әрбір процессоры басқа барлығымен тікелей байланыс орната алатын топология ең жоғары нәтижелі деп саналады (18, в - сурет). Бірақ, қазіргі заманғы технология деңгейінің мұндай мүмкіндігі жоқ (армандауға да мүмкінік бермейді): жалпы байланыс саны n(n-1)/2 болғанда, әрбір тораптың байланысы n-1.
Кейде ерекше қызық нұсқалар табылады, соның бірі екілік гиперкуб топологиясы (18, г - сурет). n - өлшемді кеңістікте бірлік n - өлшемді кубтың тек төбелерін ғана қарастырамыз, яғни, хі координаталарының бәрі 0-ге немесе 1-ге тең (x1,x2,…,xn) нүктелері. Осы нүктелерге шартты түрде жүйе процессорларын орналастырамыз, әр процессорды жақын тұрған тікелей көршісімен әрбір n - өлшемді жағалай байланыстырамыз. Нәтижесінде N=2n процессордан тұратын жүйе үшін n - өлшемді куб аламыз. Екі өлшемді куб жай шаршыға, ал төртөлшемді нұсқасы шартты түрде 18, г-суретінде бейнеленген. Гиперкубта әрбір процессор тікелей log2N көршісімен байланысқан (толық байланыс жағдайында N көрші процессорлармен). Гиперкубтың пайдалы қасиеттері көп. Мысалы, әр процессор үшін олардың барлық көршілерін анықтау қиын емес: олар одан қандай да бір хі координатасының мәні бойынша ажыратылады. n -өлшемді гиперкубтың әрбір «қыры» n-1 өлшемді гиперкуб болып табылады. n -өлшемді гиперкуб төбелері арасындағы максимал арақашықтық n- ге тең. Гиперкуб өзінің тораптарына қатысты симметриялы: әр тораптан жүйе біркелкі болып көрінеді және арнайы өңдеуді қажет ететін тораптар болмайды. Көптеген алгоритмдер өз құрылымы бойынша процессорлар арасындағы осындай өзара байланысқа жақсы сәйкес келетінін айта кету керек.
Алгоритмнің әр қадамы жүргенде гиперкуб өлшемі бір бірлікке азаяды.
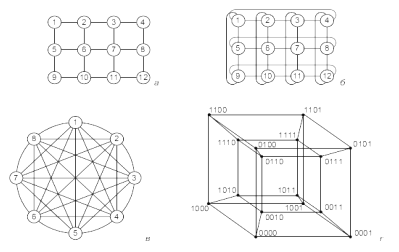
18 сурет. Процессорлардың байланыс топологияларының нұсқалары
а)решетка, б)тор в)толық байланыс г)гиперкуб
Алғашқы гиперкуб архитектуралы көппроцессорлы есептеу жүйелерінің бірі болып саналған COSMIC Cube компьютері 1983 жылы Калифорния технологиялық институтында Intel 8086/8087 микропроцессорлары негізінде құрастырылған. 1985 жылы Intel фирмасы алғашқы өндірістік гиперкуб жасап шығарды. Бұл тораптық процессорлар ретінде 80286/80287 сериялы микропроцессорларды пайдаланған iPSC (Intel Personal Supercomputer) компьютері еді. Нақ осы жылы 1024 торапқа дейін құрайтын, NCUBE Corporation фирмасының коммерциялық NCUBE/ten гиперкубы жарық көрді.
Жекелеген компьютерлерде гиперкуб басқа типті архитектуралар комбинациясында қолданылды. Thinking Machines фирмасының Connection Machine сериялы машиналарында 216 дейінгі қарапайым тораптар пайдаланылды. Осы компьютердің бір кристалында, бірімен бірі байланысқан 16 торап орналасқан, ал 212 осындай кристалдар 12-өлшемді гиперкубқа біріктірілген.
Енді ортақ және таратылған жадылы компьютерлердің ерекшеліктеріне қайта оралайық. Көріп отырғанымыздай, екі кластың да өз артықшылықтары бар, бірақ та олар біртіндеп оның кемшіліктеріне де айналуы мүмкін. Ортақ жадылы компьютерлер үшін параллель бағдарламалар құру қиындық тудырмайды, бірақ олардың максималды өнімділігі көбіне процессорлардың кішігірім санымен шектеледі. Ал таратылған жадылы компьютерлер үшін барлығы керісінше. Осы екі кластың артықшылықтарын біріктіруге бола ма? Мүмкін бағыттардың бірі – NUMA (Non Uniform Memory Access) архитектуралы компьютерлерді жобалау.
Неліктен ортақ жадылы компьютерлер үшін параллель бағдарламаларды жазу жеңіл? Себебі, бірыңғай адрестік кеңістік бар, қолданушыға мәлімет алмасу үшін процестер арасында хабар жіберуді ұйымдастырумен айналысып қажеті жоқ.
Егер қолданушылар бағдарламалары компьютердің барлық біріккен физикалық жадысына, ортақ адрестік жады деп қарайтын механизм құрылса онда барлығы көп жеңіл болар еді.
Өткен ғасырдың 70-ші жылдарының соңында бірінші NUMA –компьютерін құрастырған, Cm* жүйесін құрастырушылар осы жолмен жүрген. Бұл компьютер бір-бірімен кластер аралық шиналар арқылы байланысқан кластерлер жиынынан тұрады.
Әрбір кластер өзара локальді шиналар (19-сурет) арқылы байланысқан процессор, жады контроллері, жады модулі, кейбір енгізу/шығару құрылғыларын өзіне біріктіреді. Егер процессорға оқу немесе жазу операциясын орындау қажет болса, ол өзінің жады контроллеріне қажетті адреспен сұраныс жібереді. Контроллер адрестің үлкен разрядтарын талдау арқылы, қажетті мәліметтердің қай модульде сақтаулы екенін анықтайды. Егер адрес локальді болса, онда сұраныс локальді шинаға қойылады, кері жағдайда, қашықтағы кластер үшін арналған сұраныс кластер аралық шина арқылы жіберіледі. Бұл режимде жадының бір модулінде сақталатын бағдарлама жүйенің кез-келген процессорында орындалады. Жалғыз ғана айырмашылық – орындалу жылдамдығында. Барлық локальді сілтемелер қашықтағыларына қарағанда тез өңделеді. Сондықтан бағдарлама сақталған кластер процессоры оны басқа процессорларға қарағанда бірнеше есе жылдамырақ орындайды.
Осы ерекшелігіне қарай мұндай компьютерлер класы – жадыға біртекті емес қатынас компьютерлері деп аталады. Осы мағынада, классикалық SMP - компьютерлері UMA (Uniform Memory Access) архитектурасымен қамтылған, ондағы әрбір процессор кез келген жады модуліне бірдей қатынас жасауы қамтамасыз етілген деп айтылады.
|
|
|


19 сурет. Сm* есептеу жүйесінің сызбасы
NUMA-компьютерінің тағы бір мысалы максималды конфигурацияда 256 процессорды біріктірген BBN Butterfly компьютері болды (20 - сурет).
Компьютердің әрбір есептеу торабы процессордан, локальді желіден, жады контроллерінен тұрады. Ол сұраныстың локальді жадыға тиісті немесе оны Butterfly коммутаторы арқылы қашықтағы торапқа жіберу қажет екендігін анықтайды.
Бағдарламашының көзқарасы бойынша жады ортақ жалпы жады, ондағы қашыққа сілтемелер локальді сілтемелерден біршама ұзақ іске асырылады (шамамен 6мкс қашыққа, 2мкс локальді үшін).
Әрине, үлкен NUMA – компьютерлерін жасау жолымен алға қарай батыл жүре беруге болар еді, егер күтпеген бір проблема болмаса – ол жеке процессорлардың кэш-жадысы. Көп процессорлы жүйелер үшін, жеке процессорлардың жұмысын едәуір жылдамдатуға көмектесетін кэш-жады –тар орын болып табылады. Алғашқы NUMA – компьютерлерінің процессорларында кэш-жады болмағандықтан, мұндай мәселелер де туған жоқ болатын. Бірақ қазіргі заманғы микропроцессорлар үшін кэш-жады ажырамас құрамдас бөлік болып табылады. Біздің бұл мәселеге алаңдау себебімізді түсіндіру қиын емес. P1 процессоры q ұяшығында х мәнін сақтаған делік, содан кейін Р2 процессоры дәл сол q ұяшығындағы ақпаратты оқығысы келсін. Сонда Р2 процессоры не алады? Әрине, ол х мәнін алса екен деріміз анық, бірақ Р1 процессорының кэшіне түскен х мәнін ол қалай ала алады? Бұл мәселе, кэш-жады мазмұнының үйлесімділік мәселелері деген атқа ие (cache coherence problem, кэштің когеренттік мәселесі). Айтылған мәселе қазіргі заманғы SMP – компьютерлері үшін де актуалды, олардың да процессорлары кэші мәліметтерді пайдалануда сәйкессіздік туғызуы мүмкін.
Осы мәселені шешу үшін NUMA архитектурасының арнайы модификациясы – ссNUMA (cache coherence NUMA) жасалып шығарылды. Бұл жерде біз, барлық кэштер мазмұндарының үйлесімділігін қамтамасыз ететін көптеген хаттамалардың техникалық берілулеріне тоқталмаймыз.
Маңыздысы, бұл мәселе шешілетіні, пайдаланушыларға ауыртпалық әкелмейтіндігі. Пайдаланушы үшін басқа маңызды сұрақ: қаншалықты NUMA архитектурасы «біртекті емес»? Егер өз жадысына қарағанда, басқа тораптың жадысымен байланысқа 5-10% уақыт көп кетсе, онда бұл жағдайда ешқандай сұрақ болмауы да мүмкін.


20 сурет. BBN Butterfly есептеу жүйесінің сызбасы
Көпшілік пайдаланушылар бұл жүйеге UMA(SMP) сияқты қарайды және тәжірибе жүзінде SMP үшін құрылған бағдарламалар мұнда жеткілікті түрде жақсы жұмыс істей алады. Алайда, қазіргі заманғы NUMA жүйесі үшін тіпті олай емес, себебі локальді және қашыққа қатынас уақытының арасындағы айырмашылық 200-700% аралығын құрайды. Осындай қатынас жылдамдықтарының айырмашылығы кезінде, бағдарламалардың қажетті орындалу тиімділігін қамтамасыз ету үшін, талап етілетін деректерді дұрыс орналастыруға көп көңіл бөлу керек.
Қазіргі уақытта ссNUMA архитектурасы негізінде дәстүрлі ортақ жадылы компьютерлердің мүмкіндіктерін кеңейтетін көптеген нақты жүйелер шығарылуда. Егер жетекші өндірушілердің SMP серверлері конфигурациялары 16-32-64 процессорды құраса, онда олардың ссNUMA архитектуралы соңғы кеңейтілулері 256 және одан да көп процессорларды біріктіреді.
Параллель компьютерлердің архитектурасын жетілдіру және оларды бағдарламалық қамтамасыздандыруды дамыту қатар жүргізілді. Параллель есептеу жүйелерінің аппараттық және бағдарламалық құрамдарын дамытуды бір-бірінен бөліп қарауға болмайтынын тәжірибе көрсетті. Бір құрамдас бөлігіне жаңашылдық енгізу, басқасына да өзгеріс енгізуге тура келтіреді. Оған жақсы мысал, Cray T3D/T3E тұқымдас компьютерлерде, процестерді барьерлі синхрондауға аппараттық демеу болып табылады.
Ендігі бізді қызықтыратын ең бірінші мәселе – ол параллель бағдарламалау технологиясындағы өзгерістер. Әрине, қазіргі таңда бағдарламашылар қоржынында Ассемблер немесе Fortran ғана емес, көптеген жаңадан құрастырылған жүйелер және бағдарламалау тілдері бар екені белгілі. Алайда, қазіргі уақытта, тиімді параллель бағдарламалық қамтама құрастыру, параллель есептеудегі басты мәселе болып табылады.
Сонымен, бір есепті шешуге бірнеше процессорларды қалай жұмылдыруға және мәжбүрлеуге болады? Бұл сұрақ алғашқы параллель компьютерлердің шығуымен бір уақытта пайда болды, бүгінгі күні әртүрлі бағдарламалау технологияларының тұтас спектрі жинақталған. Нақты технологиялардың толығырақ мазмұны 2-бөлімде баяндалады, мұнда біз негізгі бағыттарды сипаттаумен шектелеміз.
Бастапқы тізбекті бағдарламаларға «параллель» спецификасын қосатын арнайы комментарилерді, дәстүрлі бағдарламалау тілдерінде пайдаланудан бастайық. Айталық, сіз Cray T90 векторлы-конвейерлік компьютерінде жұмыс істейсіз. Қолданудағы бағдарламаның кейбір циклінің барлық итерациялары бір-біріне тәуелсіз екені белгілі болса, онда оны «векторлауға» болады, яғни векторлық командалар көмегімен конвейерлік функционалды құрылғыларда өте тиімді орындауға болады. Егер цикл қарапайым болса, онда тізбекті кодты параллель кодқа айналдыру мүмкіндігін компилятордың өзі де анықтай алады. Егер компилятордың жоғары интеллектілігіне сенімділік болмаса, онда цикл басына векторлау мүмкіндігінің және тәуелсіздігінің жоқтығына айқын белгі қою керек.
Дербес жағдайда, Fortran бағдарламалау тілінде (Fortran бағдарламалау тілі параллель есептеуде жиі қолданылатынын айта кету керек) бұл былайша көрсетіледі:
CDIR$ NODEPCHK
Fortran тілінің ережесі бойынша бірінші позициядағы ´С´ әріпі ағымды жолдың комментарий екенін, ´DIR$´ тізбегі компилятор үшін арнайы комментарий екенін, ал ‘NODEPCHK’ бөлігі - орындалып жатқан циклдің итерациялары арасында ақпараттық тәуелділіктің жоқтығын көрсетеді.
Арнайы комментарийлерді пайдалану параллель орындалу мүмкіндігін ғана қосып қоймай, сонымен қатар бағдарламаның алдыңғы нұсқасын да толық сақтайды. Тәжірибе жүзінде бұл өте ыңғайлы, мысалы, егер компилятор параллельділік туралы ештеңе білмесе, онда ол бағдарламаның тізбекті семантикасын негізге ала отырып, арнайы комментарилердің бәрін ескермей өткізіп жібереді
Қазіргі уақыттағы кең тараған OPEN MP стандарты да комментарийлерді пайдалануға негізделген. Мұнда ортақ жадымен, жіптермен жұмыс істеуге және параллельділікті айқын сипаттауға басты бағдар жасалған.
FORTRAN тілінде OPEN MP арнайы коммментаридің белгісі!SOMP префиксі болып табылады, ал С тілінде «#pragma omp» директивасы қолданылады. Қазіргі күні SMP–компьютерлерінің барлық жетекші өндірушілері өз платформаларындағы компиляторларда OPEN MP-ді қолдайды.
Параллель бағдарламаларды алу үшін арнайы комментарилерді пайдаланумен қатар, қолданыстағы бағдарламалау тілдерін жетілдіруге де жиі баруда. Пайдаланушыға бағдарламаның параллельді құрылымын анық тапсыруға және кейбір жағдайларда параллель бағдарламаны басқаруға мүмкіндік беретін қосымша операторлар және айнымалыларды сипаттаудың жаңа элементтері енгізіледі.
High Performance Fortran (HPF) тіліне, FORTRAN тілінің дәстүрлі операторлары және арнайы комментарилеріне қоса, бағдарламаның параллель циклдерін сипаттау үшін енгізілген FORALL жаңа операторы кіреді. Сонымен қатар, мысал ретінде РАН жүйелік программалау Институтында құрастырылған, ANSI C кеңейтілуі болып табылатын mpC тілін айтуға болады. mpC тілінің негізгі мақсаты (қызметі) – біртекті емес есептеу жүйелеріне арналған тиімді параллель бағдарламаларды құру.
Параллель жүйелер архитектурасының спецификасын немесе қайсібір пәндік аумақтың қандай да бір есептер класының қасиеттерін дәлірек беру үшін, параллель бағдарламалаудың арнайы тілдерін қолданады. Транспьютерлік жүйелерді бағдарламалау үшін Occam тілі құрылды, ал ағынды машиналарды бағдарламалау үшін бір ретті меншіктеу тілі Sisal жобасы жасалынды. М. В. Келдыш атындағы қолданбалы математика Институтында И. Б. Задыхайлоның басқаруымен құрастырылған декларативті НОРМА тілі (есептеулерді торлық әдістермен жүргізуде пайдаланылды) өте қызықты және ерекше тіл болып саналады. Тілдің жоғары деңгейлі абстракциясы, математиктің мәселені бастапқы қоюына жуық нотацияда есептерді сипаттауға мүмкіндік береді, оны тілдің авторлары шартты түрде бағдарламашысыз бағдарламалау деп атайды. Тілде есептеу ретін бекітетін сонымен қоса, алгоритмнің табиғи параллельділігін жасыратын дәстүрлі бағдарламалау тілдерінің конструкциясы жоқ.
Массивті-параллель компьютерлердің пайда болуынан бастап, параллель процестердің ара-қатынасын қолдайтын кітапханалар мен интерфейстер кең тарай бастады. Осы бағыттағы типтік представитель, әрбір параллель платформада, яғни векторлы-конвейерлі супер ЭЕМ-нан бастап, дербес компьютерлік желілер мен кластерлерге дейін іске асырылған интерфейс Message Passing Interface (MPI) болып табылады. Мұнда, қосымшаның қандай параллель процестері бағдарламаның қай жерінде және қандай процестермен мәліметтер алмасатынын немесе өз жұмысын синхрондайтынын бағдарламашы өзі анықтайды. Негізінде параллель процестердің адрестік кеңістігі әртүрлі. Осы идеологияға сәйкес деп MPI мен PVМ-ді айтуға болады. Басқа технологияларда, мысалы Shmem, қосымшаның барлық процестеріне бірдей қолжетімді жалпы (shared) айнымалыларды да, локальді (private) айнымалыларды да қолдануға мүмкіндік береді.
Linda жүйесінде параллель бағдарлама құру үшін кезкелген тізбекті тілге төрт қосымша функция in, out, read, eval қосса жеткілікті. Өкінішке орай, бұл идеяның қарапайымдылығы оны іске асыруда үлкен мәселелерге тірейтіндіктен, бұл технология тәжірибелік құралдан гөрі академиялық қызығушылық обьектісіне алмастырылады.
Тәжірибе жүзінде қолданбалы бағдарламашылар көбіне айқын параллельді конструкцияларды мүлдем қолданбайды, қажет кезінде бағыныңқы бағдарламалар мен параллель пәндік кітапханалар функцияларын пайдаланады. Бар параллельділік және бар оптимизация шақыруларда жасырылған, ал пайдаланушыға стандартты блоктарды тиімді пайдалана отырып өз бағдарламасының тек сыртқы бөлігін ғана жазу қалады. Осыған ұқсас кітапханаларға Lapack, ScaLapack, Cray Scientific Library, HP Mathematical Library, PETSc және көптеген т.б. жатады.
Сонымен, ендігі айтылатын ең соңғы бағыт – бұл арнайы пакеттер мен бағдарламалық кешендерді пайдалану. Бұл жағдайда, пайдаланушыға бағдарлама құрудың мүлдем қажеті жоқ. Негізгі мәселе – барлық керекті енгізілетін деректерді дұрыс көрсете алу және пакеттер функционалдығын дұрыс пайдалана білу. Осылай, көптеген химиктер квантты-химиялық есептеулерді параллель компьютерлерде жүргізу үшін GAMESS пакетін пайдаланады, алайда олар параллель өңдеудің қалай іске асырылаты туралы ойланбайды да.
Сонымен, алдыңғы параграфтардағы айтылғандарды қорытындылай келе, параллель компьтерлердің аппаратурасы және бағдарламалық қамтамасындағы соңғы бірнеше он жылдықтағы үлкен өзгерістерге өз бағасын беруіміз қажет. Осы өзгерістердің нәтижесінде, қазіргі күнгі пайдаланушылар, өте күрделі есептерді шығаруға мүмкіндік беретін қуатты есептеу жүйелеріне ие болды. Алайда, тәжірибе көрсеткендей, жалпы параллель есептеу жүйелеріне қатысты мәселелер толық жойылған жоқ, олар басқа деңгейге көшті десе болады. Егер алғашқы кезде, бірнеше қарапайым компьютерді тиімді пайдалану сұрағы қойылса, ал қазір жүздеген, мыңдаған және он мыңдаған процессорлардан тұратын жүйелердің тиімділігі туралы мәселе қойылуда. Мұнда әрбір процессордың өзі де күрделі параллель жүйе екенін ескеру қажет.
Дата добавления: 2015-10-29; просмотров: 597 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Конвейерлік өңдеу | | | Функционалды құрылғылар жүйесі |