Читайте также:
|
Рассмотрим пространственные характеристики сверточных кодов в контексте простого кодера (рис. 8.3) и его решетчатой диаграммы (рис. 8.7). Мы хотим узнать расстояния между всеми возможными парами последовательностей кодовых слов. Как и в случае блочных кодов, нас интересует минимальное расстояние между всеми такими парами последовательностей кодовых слов в коде, поскольку минимальное расстояние связано с возможностями коррекции ошибок кода. Поскольку сверточный код является групповым или линейным, можно без потери общности просто найти минимальное расстояние между последовательностью кодовых слов и нулевой последовательностью. Другими словами, для линейного кода данное контрольное сообщение окажется точно таким же "хорошим", как и любое другое. Так почему бы не взять то сообщение, которое легко проследить, а именно нулевую последовательность? Допустим, что на вход передана нулевая последовательность; следовательно, нас интересует такой путь, который начинается и заканчивается в состоянии 00 и не возвращается к состоянию 00 нигде внутри пути. Всякий раз, когда расстояние любых других путей, которые сливаются с состоянием а = 00 в момент ti, окажется меньше расстояния нулевого пути, вплоть до момента ti, будет появляться ошибка, вызывая в процессе декодирования отбрасывание нулевого пути. Иными словами, при нулевой передаче ошибка возникает всегда, когда не выживает нулевой путь. Следовательно, ошибка, о которой идет речь, связана с выживающим путем, который расходится, а затем снова сливается с нулевым путем. Может возникнуть вопрос, зачем нужно, чтобы пути сливались? Не будет ли для обнаружения ошибки достаточно лишь того, чтобы пути расходились? В принципе, достаточно, но если ошибка характеризуется только расхождением, то декодер, начиная с этой точки, будет выдавать вместо оставшегося сообщения сплошной "мусор". Мы хотим выразить возможности декодера через число обычно появляющихся ошибок, т.е. хотим узнать "самый легкий" для декодера способ сделать ошибку. Минимальное расстояние для такой ошибки можно найти, полностью изучив все пути из состояния 00 в состояние 00. Итак, давайте сначала заново начертим решетчатую диаграмму, как показано на рис. 8.14, и обозначим каждую ветвь не символом кодового слова, а ее расстоянием Хэмминга от нулевого кодового слова. Расстояние Хэмминга между двумя последовательностями разной длины можно получить путем их сравнивания, т.е. прибавив к началу более короткой последовательности нужное количество нулей. Рассмотрим все пути, которые расходятся из нулевого пути и затем в какой-то момент снова сливаются в произвольном узле. Из диаграммы на рис. 8.14 можно получить расстояние этих путей до нулевого пути. Итак, на расстоянии 5 от нулевого пути имеется один путь; этот путь отходит от нулевого в момент t1 и сливается с ним в момент t4.. Точно так же имеется два пути с расстоянием 6, один отходит в момент t1 и сливается в момент t5 а другой отходит в момент t1 и сливается в момент t6 и т.д. Также можно видеть (по пунктирным и сплошным линиям на диаграмме), что входными битами для расстояния 5 будут 1 0 0; от
нулевой входной последовательности эта последовательность отличается только одним битом. Точно так же входные биты для путей с расстоянием 6 будут 1 1 0 0 и 1 0 1 0 0; каждая из этих последовательностей отличается от нулевого пути в двух местах. Минимальная длина пути из числа расходящихся, а затем сливающихся путей называется минимальным просветом (minimum free distance), просветом или свободным расстоянием (free distance). Его можно видеть на рис. 8.14, где он показан жирной линией. Оценка возможностей кода по коррекции t ошибок, определяется известным уравнением с заменой минимального расстояния dmin на просвет (свободное расстояние) df

Здесь [x] означает наибольшее целое, не большее х. Положив df = 5, можно видеть, что код, описываемый кодером на рис. 8.3, может исправить две любые ошибки канала.
 |
Решетчатая диаграмма представляет собой "правила игры". Она является как бы символическим описанием всех возможных переходов и соответствующих начальных и конечных состояний, ассоциируемых с конкретным конечным автоматом. Эта диаграмма позволяет взглянуть глубже на выгоды (эффективность кодирования), которые дает применение кодирования с коррекцией ошибок. Взглянем на рис. 8.14 и на возможные ошибочные расхождения и слияния путей. Из рисунка видно, что декодер не может сделать ошибку произвольным образом. Ошибочный путь должен следовать одному из возможных переходов. Решетка позволяет нам определить все такие доступные пути. Получив по этому пути кодированные данные, мы можем наложить ограничения на переданный сигнал. Если декодер знает об этих ограничениях, то это позволяет ему более просто (используя меньшее значение сигнал/помеха - Eb/N0) удовлетворять требованиям надежной безошибочной работы.
Хотя на рис. 8.14 представлен способ прямого вычисления просвета, для него можно получить более строгое аналитическое выражение, воспользовавшись для этого диаграммой состояний, изображенной на рис. 8.5. Для начала обозначим ветви диаграммы состояний как D0= 1, D1 или D2, как это показано на рис. 8.15, где показатель D означает расстояние Хэмминга между кодовым словом этой ветви и нулевой ветвью. Петлю в узле а можно убрать, поскольку она не дает никакого вклада в пространственные характеристики последовательности кодовых слов относительно нулевой последовательности. Более того, узел а можно разбить на два узла (обозначим их а и е), один из них представляет вход, а другой — выход диаграммы состояний. Все пути, начинающиеся из состояния а = 00 и заканчивающиеся в е = 00, можно проследить на модифицированной диаграмме состояний, показанной на рис. 8.15. Передаточную функцию пути a b c e (который начинается и заканчивается в состоянии 00) можно рассчитать через неопределенный "заполнитель" D как D2DD2 = D5. Степень D — общее число единиц на пути, а значит, расстояние Хэмминга до нулевого пути. Точно так же пути a b d
c e и a b c b e e имеют передаточную функцию D6 и, соответственно, расстояние Хэмминга, равное 6, до нулевого пути. Теперь уравнения состояния можем записать следующим образом:
Xb = D2Xa+Xc,
Xc = DXb+DXd,
Xd = DXb+DXd,
Xe = D2Xc.
Здесь Хa,..., Хе являются фиктивными переменными неполных путей между промежуточными узлами. Передаточную функцию кода, T(D), которую иногда называют производящей функцией кода, можно записать как T(D) = Xe/Xa. Решение уравнений состояния имеет следующий вид:
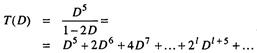
Передаточная функция этого кода показывает, что имеется один путь с расстоянием 5 до нулевого вектора, два пути — с расстоянием 6, четыре — с расстоянием 7. В общем случае существуют 2 l пути с расстоянием l + 5 до нулевого вектора, причем l = 0, 1, 2,.... Просвет df кода является весовым коэффициентом Хэмминга слагаемого, имеющего наименьший порядок в разложении T(D). В данном случае df = 5. Для оценки пространственных характеристик при большой длине кодового ограничения передаточную функцию T(D) использовать нельзя, поскольку сложность T(D) экспоненциально растет с увеличением длины кодового ограничения.
 |
С помощью передаточной функции кода можно получить более подробную информацию, чем при использовании лишь расстояния между различными путями. В каждую ветвь диаграммы состояний введем множитель L так, чтобы показатель L мог служить счетчиком ветвей в любом пути из состояния а = 00 в состояние е = 00.
Более того, мы можем ввести множитель N во все ветви переходов, порожденных входной двоичной единицей. Таким образом, после прохождения ветви суммарный множитель N возрастает на единицу, только если этот переход ветви вызван входной битовой единицей. Для сверточного кода, описанного на рис. 8.3, на перестроенной диаграмме состояний (рис. 8.16) показаны дополнительные множители L и N. Уравнения теперь можно переписать следующим образом:
Xb = D2LNXa+LNXc,
Xc = DLXb+DLXd,
Xd = DLNXb+DLNXd,
Xe = D2LXc.
Передаточная функция кода такой доработанной диаграммы состояний будет следующей:

Таким образом, мы можем проверить некоторые свойства путей, показанные на рис. 8.14. Существует один путь с расстоянием 5 и длиной 3, который отличается от нулевого пути одним входным битом. Имеется два пути с расстоянием 6, один из них имеет длину 4, другой — длину 5, и оба отличаются от нулевого пути двумя входными битами. Также есть пути с расстоянием 7, из которых один имеет длину 5, два — длину 6 и один — длину 7; все четыре пути соответствуют входной последовательности, которая отличается от нулевого пути тремя входными битами. Следовательно, если нулевой путь является правильным и шум приводит к тому, что мы выбираем один из неправильных путей с расстоянием 7, то в итоге получится три битовые ошибки.
 |
Дата добавления: 2015-08-02; просмотров: 68 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Память путей и синхронизация | | | Систематические и несистематические сверточные коды |