Читайте также:
|
Основное предназначение взвешивания терминов, как отмечалось выше, заключается в определении того, насколько полно они отражают содержание документа. Как показывает практика, частотные методы оценки весов имеют ряд недостатков. Следствием этого является получение в результате поиска нерелевантных и отсутствие истинно релевантных документов.
Во-первых, описанные методы не учитывают тот факт, что частоты встречаемости различных терминов зависят друг от друга. Термины не появляются в документе независимо от остальных терминов, они могут быть, например, объединены в словосочетания, устоявшиеся обороты и т. п.
Другой проблемой является синонимия и полисемия (многозначность) [24].
Под синонимией понимается тот факт, что любое явление или предмет могут быть выражены различными способами. В зависимости от контекста, знаний человека, манеры письма одни и те же сведения описываются разными терминами (синонимами). Например, синонимы «дисплей» и «монитор» определяют один и тот же предмет.
Полисемия, напротив, заключается в том, что большинство слов в языке имеет несколько значений. Один и тот же термин может обозначать абсолютно разные понятия. Соответственно, наличие того или иного термина в некотором документе не означает того, что документ является релевантным запросу, в котором содержится такой же термин. В качестве иллюстрации приведем слово «мышь», которое означает и грызуна, и компьютерное устройство [1].
Описанные проблемы решает латентное семантическое индексирование[5] [24, 38]. Суть этого подхода состоит в том, что каждый набор документов имеет неявную, латентную семантическую структуру[6]. Анализ такой структуры (латентно-семантический анализ) позволяет описать каждый документ не только с точки зрения наличия или отсутствия каких-либо терминов, но и с точки зрения его смысла (семантической направленности). Например, документ может быть адекватно описан терминами, которые не входят в его состав, и наоборот – некоторые термины не отражают смысла документа, и совпадение их с терминами запроса не делает документ релевантным [20].
Таким образом, в результате количественного анализа латентных факторов веса терминов могут быть скорректированы, и поисковый образ документа станет более адекватным его содержанию. Качество поиска в ИПС, использующих ЛСИ, выше, чем в системах, где применяются только частотные методы.
Латентно-семантическое индексирование позволяет также охарактеризовать документ некоторыми новыми свойствами, которые не связаны с наличием или отсутствием терминов (например, количеством библиографических ссылок на данный документ из остальных документов набора, разметкой документа (обычный текст или таблица) или, для документов Интернет, частотой обновления и посещаемостью страницы [7, 9]).
Математически латентно-семантическое индексирование реализуется с помощью одного из методов линейной алгебры – сингулярного разложения матрицы [1, 24]. Современные алгоритмы используют также аппарат теории вероятностей (вероятностное латентное семантическое индексирование) [23].
Одним из важных направлений ЛСИ является межязыковое латентно-семантическое индексирование[7] [20]. Основным принципом здесь является тот факт, что запрос на одном языке может возвращать релевантные документы на других языках.
Рассмотрим некоторую группу документов, где каждый документ представлен на двух языках (например, немецком и английском). После проведения латентно-семантического анализа каждый документ будет описан как немецкими, так и английскими терминами в едином межязыковом семантическом пространстве. Поэтому запросы к этому набору документов, а также к вновь добавляемым в набор документам (на каком-то одном языке) можно будет делать на любом из двух языков.
Главное достоинство межязыкового ЛСИ – отсутствие необходимости перевода (ручного или машинного) запроса на другой язык. Это особенно актуально для поиска в сети Интернет, когда запросы являются неспециализированными, и их адекватный перевод вызывает значительные трудности [1, 20, 25].
Латентно-семантический анализ в настоящее время также часто применяется для анализа гипертекстовых документов. Практика показывает, что документы, связанные гиперссылками, обычно находятся в одном семантическом пространстве. Один из латентных факторов, которым в данном случае является структура гиперссылок, существенно влияет на точность поиска [17].
Примером количественной характеристики этого фактора может служить величина  , которая вычисляется на основе информации о других документах, имеющих ссылки на данный, и определяется выражением
, которая вычисляется на основе информации о других документах, имеющих ссылки на данный, и определяется выражением
 . .
|
Здесь 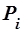 и
и  – документы информационного массива;
– документы информационного массива;  – некоторый параметр (обычно
– некоторый параметр (обычно  );
);  – общее количество ссылок, выходящих из документа ;
– общее количество ссылок, выходящих из документа ;  – величина, характеризующая наличие гиперссылки из документа
– величина, характеризующая наличие гиперссылки из документа 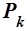 в документ
в документ  (исходящей гиперссылки[8]).
(исходящей гиперссылки[8]). 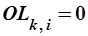 , если такая ссылка отсутствует, и
, если такая ссылка отсутствует, и  , если она существует.
, если она существует.
Значение , которое рассчитывается для каждого документа, определяет его важность по сравнению с другими документами [7].
Для реализации некоторых вспомогательных операций информационного поиска (автоматическая фильтрация[9], классификация и др.) также используются алгоритмы ЛСИ [9].
[1] Подробнее о мерах близости документов и запросов см. Часть 2 методических указаний.
[2] Подобному распределению подчиняются не только все естественные языки мира, но и другие явления: распределения ученых по числу опубликованных ими статей, городов по численности населения, биологических родов по численности видов, посетителей сайтов сети Интернет и т. д. [14]
[3] TF – англ. Term Frequency – частота термина в отдельных документах.
[4] IDF – англ. Inversed Document Frequency – обратная документная частота.
[5] Латентное семантическое индексирование (ЛСИ) – англ. Latent Semantic Indexing (LSI)
[6] Под семантической структурой здесь имеется в виду некоторая структура, в которую объединены отдельные термины в документе.
[7] Межязыковое ЛСИ – от англ. Cross-language Latent Semantic Indexing
[8] OL – англ. Outgoing Hyperlink – исходящая гиперссылка.
[9] Автоматическая фильтрация – это отбор документов, удовлетворяющих информационной потребности пользователя, из некоторого потока. Примером потока может служить лента новостей информационного агентства, на которую непрерывно поступает свежая информация.
Дата добавления: 2015-07-10; просмотров: 271 | Нарушение авторских прав