Читайте также:
|
Большинство современных алгоритмов индексации и поиска в той или иной степени основано на векторной модели текста, предложенной Дж. Солтоном в 1973 году. В векторной модели каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Иными словами, каждому документу соответствует вектор, размерность которого равна числу терминов, которыми можно воспользоваться при поиске [10].
Для дальнейшего изложения введем несколько важных понятий: словарь, поисковый образ документа, информационный массив [13].
Словарь – это упорядоченное множество терминов. Мощность словаря обозначается как  .
.
Поисковый образ документа – это вектор размерности . Самый простой поисковый образ документа – двоичный вектор. Если термин входит в документ, то в соответствующем разряде этого двоичного вектора проставляется 1, в противном же случае – 0. Более сложные поисковые образы документов связаны с понятием относительного веса терминов или частоты встречаемости терминов [2].
Любой запрос также является текстом, а значит, его тоже можно представить в виде вектора  . В процессе работы поискового алгоритма происходит сравнение векторов поискового образа документа и поискового образа запроса. Чем ближе вектор документа находится к вектору запроса, тем более релевантным он является[1].
. В процессе работы поискового алгоритма происходит сравнение векторов поискового образа документа и поискового образа запроса. Чем ближе вектор документа находится к вектору запроса, тем более релевантным он является[1].
Обычно все операции информационного поиска выполняются над поисковыми образами, но при этом их, как правило, называют просто документами и запросами.
Информационный массив  представляют в виде матрицы размерности
представляют в виде матрицы размерности 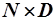 , где в качестве строк выступают поисковые образы
, где в качестве строк выступают поисковые образы  документов:
документов:
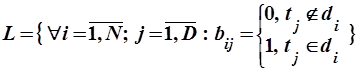 , ,
| (2.1) |
где  – термин,
– термин, 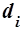 – документ. Информационный массив называют также информационным потоком, набором документов или коллекцией документов.
– документ. Информационный массив называют также информационным потоком, набором документов или коллекцией документов.
Описанная модель информационного массива является наиболее широко используемой. В первую очередь это связано с простотой реализации и, как следствие, возможностью быстрой обработки больших объемов документов. В случае использования весов терминов информационный массив может быть представлен в виде
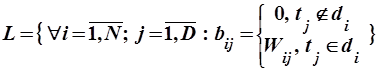 , ,
|
где 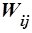 – вес термина в документе .
– вес термина в документе .
Матрица информационного массива изображена на рис. 4.

Рис. 4. Матрица "термин-документ" информационного массива
Процедура обращения к информационно-поисковой системе может быть определена следующим образом:
 . .
|
Здесь – вектор запроса,  – вектор отклика системы на запрос.
– вектор отклика системы на запрос.
Остановимся подробнее на статистических закономерностях, которые используются в процессе индексирования документов.
Дата добавления: 2015-07-10; просмотров: 248 | Нарушение авторских прав