Читайте также:
|
Задачей кластеризации является выделение из системы данных множества схожих объектов и соединения их в группы (кластеры).
Методы кластеризации делятся на 1) иерархические: агломеративные (последовательное объединение исходных элементов в кластеры) и дивизимные (последовательное расщепление на группы объектов).
В данной работе применяется виджет Hierarchical Clustering и агломеративный метод.
2) Неирерахические.
В данной работе используется метод k-Means Clustering (метод k-средних).
Опишем этапы данного метода:
1 этап: Множество объектов разделяется на заданное число кластеров и вычисляются центры тяжести этих кластеров. Точки данных помещаются в кластер с ближайшим центром.
2 этап: Вычисляются новые центры тяжести по точкам, входящим в кластер.
3 этап: Точки данных перераспределяются по кластерам в соответствии с новыми центрами.
4 этап: Этапы 2 и 3 повторяются до тех пор, пока кластеры не перестанут изменяться.
Рассмотрим подробнее каждый метод кластеризации:
1) Используется, как уже сказано выше, агломеративный метод.
Программа разбила наше множество на 2 кластера. Дендрограмма изображена на рис.12.
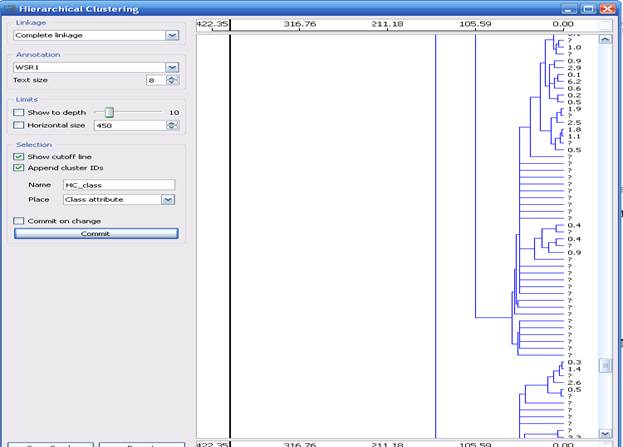
Рис.12. Дендрограмма иерархического метода
2) Рассматривается метод k-средних. Его дендрограмма изображена на рис.13.

Рис.13. Дендрограмма метода k-средних (неиерархический метод)
Из рис.13 видно, что программа разбила наши данные на 5 кластеров (С1…С5). При наведении на определенную точку на диаграмме можно увидеть информации о ней – к какому классу относится, какое имеет значение и, наконец, к какому кластеру относится.
Выводы по работе: в данной работе нами была исследована система данных Ozone Level Detection, дающая информацию об днях с озоном и без озона и всевозможных параметрах внешней среды, которые являются значениями наших атрибутов.
Задачей классификации являлась задача отнесения значения того или иного атрибута к тому или иному классу (есть озон – class 1., нет озона – class 0.).
Был проведен сравнительный анализ алгоритмов классификации при различных методах тестирования. В результате, анализируя данные из таблицы 1, можно сделать вывод, что наиболее точным алгоритмом при анализе наших данных оказался CN2 (даже несмотря на то, что при тестировании leave-one-out он дал не самые лучшие результаты; метод тестирования leave-one-out, на наш взгляд, использовать неудобно, поскольку он слишком долго работает на большом объеме данных, поэтому им можно пренебречь).
Из методов кластеризации наиболее удобно использовать неирерхический метод кластеризации, поскольку он быстр в работе и дает большую наглядность и понятность, нежели иерархический агломеративный метод, используемый в нашей работе.
Данная работа также дала нам представление о таком мощном математическом аппарате как Data Mining. Представляя объем данных нашей системы, появляется необходимость говорить уже о «Хранилище данных», нежели о «Базе данных», поэтому при анализе разумно использовать только средства математического анализа.
Дата добавления: 2015-10-21; просмотров: 131 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Построение классификационных моделей | | | Тенденции в дизайне логотипов |