|
Читайте также: |
Ранжирование (иначе взвешивание) результатов поиска может быть определено как процесс вычисления так называемой релевантности (или веса) для каждого данного подобранного документа относительно данного вопроса, который соответствовал ему. Таким образом, релевантность - просто число, приложенное к каждому документу, с помощью которого можно оценить, насколько релевантный документ по отношению к запросу. Результаты поиска могут быть сортированы на основании этого числа и/или некоторых дополнительных параметров, так, чтобы наиболее популярный результат был выше остальных на странице результатов.
Нет никакого единого стандарта для оценки документов, кроме того, такого стандарта и не может быть, потому что релевантность объектов субъективна. Следовательно, для общего случая релевантность не просто трудно вычислить, это теоретически невозможно.
Ранжирование у Sphinx конфигурируемо. Оно имеет такое понятие как ранкер. Ранкер может формально быть определен как функция, которая берет документ и запрос на вход и вычисляет стоимость релевантности (вес документа относительно запроса). Ранкер контролирует то, каким образом (используя определенный алгоритм) Sphinx будет назначать вес для каждого документа. [4]
Два наиболее важных фактора вычисления веса при ранжировани это:
1) классический статистический фактор BM25;
2) специфичный для Sphinx фактор веса фразы.
ВМ25 – это некое вещественное число в диапазоне от нуля до единицы, которое зависит от того, насколько часто встречаются ключевые слова в выбранном документе и в общем наборе всех документов. На сегодняшний день ВМ25 представлен в Sphinx из расчета общей частоты употребления слова в документе, а не только от количества фактических совпадений с самим запросом. Это упрощение сделано намеренно, так как фактор ВМ25 вторичен в стандартном для Sphinx режиме ранжирования. Фактор BM25 используется многими системами полнотекстового поиска совместно с собственными факторами вычисления веса.
TF-IDF — статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов. Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
Вычисление TF-IDF.
TF (term frequency — частота слова) — отношение числа вхождения некоторого слова к общему количеству слов документа. Таким образом, оценивается важность слова  в пределах отдельного документа.
в пределах отдельного документа.

где  есть число вхождений слова в документ, а в знаменателе – общее число слов в данном документе.
есть число вхождений слова в документ, а в знаменателе – общее число слов в данном документе.
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции. То есть если какое-то слово встречается практически в каждом документе, то оно общеупотребимо и менее важно для поиска. IDF сразу убивает все частицы, предлоги и другие служебные части речи, а так же часто используемые слова.

где  - количество документов в коллекции,
- количество документов в коллекции,  - количество документов, в которых встречается (когда
- количество документов, в которых встречается (когда 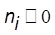 ).
).
Выбор основания логарифма в формуле не имеет значения, поскольку изменение основания приводит к изменению веса каждого слова на постоянный множитель, что не влияет на соотношение весов.
Таким образом, мера TF-IDF является произведением двух сомножителей:
 [14]
[14]
Фактор BM25 основан на данной метрике.
Фактор BM25 увеличивается в значении, когда мы ищем редкие ключевые слова, но в документе они встречаются часто. Значение падает, когда ключевые слова часто употребляются. Максимум достигается тогда, когда с документом совпали все, при этом редкие, ключевые слова, которые входят в документ много раз. Слишком частые слова уменьшают BM25.
Вес фразы (степень близости с запросом или query proximity) считается совершенно иначе. Этот фактор совсем не учитывает частоты, зато учитывает взаимное расположение ключевых слов запросе и документе. Для его расчета Sphinx анализирует позиции ключевых слов в каждом поле документа, находит самое длинное непрерывное совпадение с запросом, и считает его, совпадения, длину в ключевых словах. Формально говоря, находит наибольшую общую подпоследовательность (Longest Common Subsequence, LCS) ключевых слов между запросом и обрабатываемым полем, и назначает вес фразы для этого поля равным длине LCS. Вес (под)фразы — это число ключевых слов, которые в поле появились ровно в таком же порядке, как и в запросе.
Однако полное совпадение с запросом не дает лучшего результата в этом факторе.
Чтобы получить окончательный вес фразы для документа, веса фразы в каждом поле перемножаются на указанные пользователем веса полей (для этого есть соответствующая функция) и результаты умножения складываются. По умолчанию веса полей равны 1, и не могут быть выставлены ниже 1.[ссылка на хабр]
Дата добавления: 2015-10-16; просмотров: 453 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Установка и настройка Sphinx | | | Разработка компонента кэширования рекомендаций |