Читайте также:
|
5.1 Структурная согласованность баз знаний
Целью моего дипломного проекта является создание структурной модели для прикладной программы разработки бизнес-планов. Поэтому в данном разделе изучаются методы, с помощью которых строится структурная модель программы. Задача построения таксономии знаний всегда связана с определением ее непротиворечивой, согласованной структуры. Сложность этой задачи определяется несколькими факторами, основными из которых являются большой объем поступающей информации и динамичность этого потока, что определяет необходимость реализации соответствующих процедур адекватной реструктуризации системы знаний в соответствии с произошедшими изменениями. Один из подходов к оценке степени согласованности системы взаимосвязанных элементов базы знаний основывается на анализе тернарных отношений между объектами этой системы, путем ввода правила, позволяющего каждое тернарное отношение относить к одному из двух типов: согласованному и рассогласованному. В ряде работ эти типы получили соответственно названия консонансного и диссонансного состояния тройки. Выбрав определенный критерий состояния тройки объектов, мы можем представить всю совокупность имеющихся объектов в виде множества троек, для каждой из которых в соответствии с выбранным критерием можно определить ее тип, что дает возможность построить некоторую систему классификации внутреннего состояния множества взаимосвязанных однородных объектов, позволяющую определить его структурную согласованность. Свойства консонансных множеств исследованы в ряде работ. Развитие теории структурной согласованности множеств взаимосвязанных объектов привело к ее расширению на основе введения понятия поликонсонанса и исследованию его свойств. На основе этих свойств был предложен интегрированный алгоритм реструктуризации произвольного множества взаимосвязанных объектов, приводящей к его поликонсонансному прообразу, соответствующему согласованному состоянию данного множества. Алгоритм базируется на операциях повершинного переброса и оценках вектора повершинных различий, который строится исходя из вида знаковой матрицы связности, отображающей структуру исследуемого множества объектов. Являясь хорошим средством визуализации структуры рассматриваемого множества объектов, матрица связности служит и основным инструментарием, с помощью которого эксперт оказывает влияние на весь процесс реструктуризации этого множества, что позволяет реализовать процесс классификации как интерактивную человеко-машинную процедуру, обеспечивающую приведение базы знаний эксперта к согласованному состоянию.
5.2 Построение взаимосвязей между объектами и аппроксимация сходства
1 Взаимосвязи в множестве слабоструктурированных объектов
Как отмечено выше, современная работа эксперта с информацией характеризуется в значительной степени тем, что эта информация представлена в мультимедийной форме, предполагающей интеграцию в виде единого информационного массива данных различного типа. Каждый из этих типов имеет свои характеристики и свойства, что требует своего особого описания при выработке тех или иных подходов к оценке сходства двух различных объектов одного типа. Часто эта задача в области распознавания образов или других теорий. Но в большинстве случаев основным источником информации для пользователя документальных баз данных является все же текстовая информация. Если при этом некоторый документ является мультимедийным, то из него всегда можно выделить текстовую составляющую, которая часто и несет информационную нагрузку. Поиск различных методов оценки взаимосвязей между слабоструктурированными документальными объектами (тексто-выми документами) и анализ существующих методов позволяет сделать вывод о том, что наибольшее распространение сегодня получили два метода оценки взаимосвязей ("сходства") между документами: метод взвешенных ключевых слов и метод латентных семантик.
2 Метод взвешенных ключевых слов
Данный метод основывается на представлении документов в виде неупорядоченного набора слов, встречающихся в этом документе, с присвоенным каждому из них весовым коэффициентом, характеризующим значимость этого слова для выражения общего смысла всего документа. Расчет весовых коэффициентов часто производится по методике "tfidf" (term frequency times inverse document frequency). Если документ имеет некоторую структуру, то весовые коэффициенты слов могут быть модифицированы в соответствии с их месторасположением в тексте: например, коэффициенты слов заголовка могут быть увеличены. Общий вид формулы расчета весовых коэффициентов:
Wi= Ci*fi*log(N/fd)
где wi - вес i-го слова документа d;
Ci - модифицируемая константа;
fi - частота встречаемости слова в документе;
N - общее количество документов в базе данных;
fd - количество документов, в которых найдено данное слово.
Модифицирующие константы Ci определяются часто эмпирическим путем или с применением алгоритмов обучения. При определении значений таких констант исходят из разного рода предположений о зависимости расположения слова и соответствующей им смысловой нагрузке. Представление документов в виде векторов взвешенных ключевых слов дает возможность определения взаимосвязи между любоу парой таких документов на основе сравнения соответствующих им векторов. Функция сходства здесь может быть использована любая. В научной литературе часто в качестве нее используется функция относительного веса общих для двух документов ключевых слов:
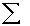 Wik*Wjk
Wik*Wjk
f(Di, Dj)=V Wik^2* Wjk^2
Выводы
В дипломной работе создается база знаний путем обобщения по признакам, то есть, формулы представляются через структуры, в которых имеются пространство и время. Фактом представления знаний является жизненный цикл. Факты объединяются в И/ИЛИ-дерево, а это дерево и продукционные правила над ИЛИ-синтермами позволяют говорить о создании базы знаний. База знаний - модульная, то есть формируется база знаний о внутренних структурах блока с определенным именем. А имя задает класс объектов или тип. Цель: обеспечить вывод нужного решения по некоторому техническому решению. А техническое задание - это перечисление подмножеств значений или узлов. Таким образом, решены задачи:
1. По ряду прототипов путем обобщения по признакам сформировано И/ИЛИ-дерево с прототипами (их наличие позволяет работать с продукциями). Продукции - стандартные, их наличие создает базу знаний.
2. Обеспечено формирование ряда семантических ограничений на работу аппарата изобретений с тем, чтобы по некоторому набору исходных прототипов сформировать то множество прототипов, которое нужно для обобщения.
3. Синтез (на уровне пользователя) для иллюстрации работоспособности системы.
В дипломной работе рассмотрено формирование системы принятия решений в области выбора наилучшего варианта инвестиций с целью снижения трудоемкости создания бизнес-планов.
В данной работе были рассмотрены способы представления знаний об экономике для системы создания бизнес-планов. Поскольку моя дипломная работа тесно связана с дальнейшим усовершенствованием структуры прикладной программы, то в работе были представлены методы и способы для создания такой структуры.
Дата добавления: 2015-08-21; просмотров: 92 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Процедуры изобретения новых объектов | | | Йа! Йа! Ктулху фхтагн! |