Читайте также:
|
ОДО 2 курс (4 семестр)
Составитель: Ассистент Берзина Д.В.
Перечень утвержден на заседании кафедры
математического моделирования СФ БашГУ
Протокол № «_____» от_______________2012г.
Зав. кафедрой д.ф.-м.н., профессор С.А. Мустафина
1.Задачи СППР класс программных систем призванных облегчить работу людей выполняющих анализ.задачи реаемые СППР:1.ввод данных.2.хранение данных 3.АД.СППР-система обладающая ср-ми ввода,хранения и АД относящихся к определенной предметной области с целью поиска решения.Вод данных осуществляется либо автоматически от передатчиков характеризующих состояние среды или человеком оператором.основная задача сппр-предоставить аналитикам инструент для анализа данных.система не гарантирует правильные решения,а только предоставляет аналитику данные в соотв.виде.(отчеты,таблицы,графики).классы задач анализа:1.информационно поисковый.СППР осущ поиск необходимых данных.2.Оперативно-аналитический.СППР производит группирование и обобщение данных в любом виде необходимом аналитику.3.интеллектуальный.СППРосущ.поиск функц.и логических заономерностей в накопленных данных,построение моделей.
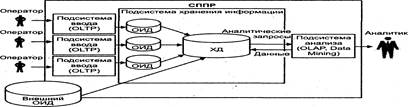
2. Архитектура СППР. оператор- подсистема ввода(СУБД OLIP)- подсистема хранения(СУБД или хранилища данных)-Подсистема аналитика [под-ма информ.поискового анализа] [под-ма оперативного анализа] [под-ма интеллект.анализа] –аналитик. Подсистема ввода- oltp выполняется транзакционная обработка данных. Подсис.анализа -построена на основе информ.поискового анализа,на базе реляционных СУБД.
3.Концепция хранилища данных.в основе кхд лежит идея разделения данных используемого для опретивной обработки и для решения задач анализа.в сппр есть источники данных:- оперативные источк.данных.2. ХД.ХД-это предметно-ориентированный интегрированный,неизм-ый поддреживающий хронологию набор данных организованной для цели поддержки принятия решений. СВ-ва ХД: 1.предметная ориентация.-позволяет хранить в хд только те данные которые нужны для анализа.2.поддержка хронологий.3.интеграция-приводит данные к единому формату.4.неизменяемость.ХД после загрузки только читаютя.это позволяет существенно повысить скорость доступа к данным.
4. Структура СППР с физическим и виртуальным ХД.Физическое. При загрузке информации из ОИД в ХД данные фильтруются. Многие из них не попадают в ХД, поскольку лишены смысла с точки зрения использования в процедурах анализа.
Информация в ОИД носит, как правило, оперативный характер, и данные, потеряв актуальность, удаляются. В ХД, напротив, хранится историческая информация. С этой точки зрения дублирование содержимого ХД данными ОИД оказывается весьма незначительным. В ХД хранится обобщенная информация, которая в ОИД отсутствует.
Во время загрузки в ХД данные очищаются (удаляется ненужная информация), и после такой обработки они занимают гораздо меньший объем
 Избыточность инфрм.можно свести к 0 используя вирт-е ХД.в данном случае данные из ОИД не копир.в единое хранилице.они извлекаются,преобразуются и интегрируются непоср-но при выполнении аналит.запросов в операт.памяти компьютера.Факт.такие запросы напрямую адресуются к ОИД.
Избыточность инфрм.можно свести к 0 используя вирт-е ХД.в данном случае данные из ОИД не копир.в единое хранилице.они извлекаются,преобразуются и интегрируются непоср-но при выполнении аналит.запросов в операт.памяти компьютера.Факт.такие запросы напрямую адресуются к ОИД. 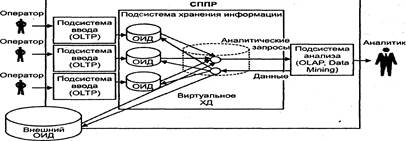 Основные достоинства вирт Хд:1.минимизация объемов памяти,заменяемых на носит.инфор. 2.работа с текущими детализированными данными.
Основные достоинства вирт Хд:1.минимизация объемов памяти,заменяемых на носит.инфор. 2.работа с текущими детализированными данными.
5.Измерительные шкалы. Переменные м.б.измерены в разл.шкалах.различ.шкал определяется их информативностью.1.нормативная шкала.2.порядковая.интервальная.шкала отношений.абсолютная шкала. измерения в начальной шкале означает определение принадлежности объекта к тому или иному классу.в этой шкале можно лишь подсчитать кол-во объектов класса. Измер.в порядковой шкале еще и позволяет упорядочить наблюдение,сравнив их м/у собой в каком-то отношении.Эта шкала не опред.дистанцию м/у классами,а только какое из 2х наблюдений предпочтительней. При изм.в интервальной шкале,упоряд.наблюдения можно выполнить настолько точно,что известно расст.м/у любыми 2мя из них.эта шкала единств.с точностью до линейных преобразований.шкала имеет произв.точку отсчета,т.е.условный нуль.шкала отношений похожа на интерв.шкалу,но она единственна с точностью преобразования слуд вида у=ах. Это означает,что шкала имеет фиксир.точку отсчета,но произвольный масштаб измерения.Абсолютная шкала.-имеет и абсолютный 0 и абсолютн.еденицу измерения.примером явл-ся числовая прямая.эта шкала безразмерна.номин.и порядковая-кач-ые шкалы.стальные-количественные.
6. Коррело-регресс анализ.для исслед интенсивности и формы зависимости примен этот анализ,который явл-сяметодическ.инструменталом при решении задач прогнозир,планиров-я и анализа хоз.деят.предприятия.корреляция-связь,соотношение м/у объективно существ явл.в коелл-м анализе оценивается сила связи,а в регрессионном исследуется ее формарегрессия-просто функциональная зависимость одной пер-ой у от других независимых переменных х1,х2.регрессионные методы применяются главным образом для обнаруж.ф-ых зависимостей данных.
7.Дисперсионный анализ. Дисперсия-наиболее употреб.мера рассеивания, т.е.отклонения от среднего. Прикладная цель дис.анализа заключ.в ответе на вопрос:оказывают ли факторы влияние на зависим.величины или нет? Факторы должны быть представл-ы в номинальной или порядк.шкале.используя дисп.анализ вы можете:провести ранжирование факторов,по степени влияния на объем продаж.2.оценить,на сколько % увеличив.объем продаж при изменении того или иного фактора.3.спрогнозировать объем продаж новой торговой точки.
8.Кластерный анализ.предназначен для разбиения совокупности объектов на однородные группы кластеры или классы,по сути эта задача многомерной классификации данных.применяется в маркетинге,менеджменте.достоинство метода-работает даже тогда,когда данных мало,и когда не выполняются требования классич.методов статистич.анализа
9.Многомерная модель данных. Операции.Измерение-последовательность значений одного из анализируемых параметров.Множ.измерений предполагает представл.данных в виде многомерной модели;по измерению в многомерной модели откладывают пар-ры,относит. К анализир.предметной области.Многомерн.концепция представл- это множ.преспектива,состоящая из неск,независимых измерений,вдоль которых м.б. проанализир.опред.совокупности данных.Операции:1.срез-формирование подмножества многомерного массива данных.2.вращение-это изменение расположения измерений.3.Консолидация и детализация.
10.Определение OLAP-системы.-это технология оперативной аналитич.обработки данных,использ.ср-ва и методы для сбора,хранения и анализа многомерных данных в цели оддержки процессов принятия решений.Основное назначение-это поддержка аналитич.деятельности,произв.запросов пользователей,аналитиков.Цель OLAP анализа-проверка возникающих гипотез.OLAP содежрит компоненты:1.олап сервер.2.олап клиент.
11. Определение Data Mining-это исслед.и обнаруж.скрытых знаний,которые раннее не были известны,практически полезны и доступны для интерпритации человека.свва обнаруживаемых знаний:1.знания должны быть новые,ранее неизвестны.2.знания должны быть не тревиальны.3.зн.дол.быть практически полезны.полезность заключ.в том,что бы эти знания могли принести опред.выгоду.4.зн.д.б. доступны для понимания человеку.в Data Mining для пред-я получ.знаний служат модели.Наиболее распр-е-правила,деревья решений,кластеры.
12.Основные задачи анализа данных.1.задача классификации-задача своится к опред.классу объектов по его характерм.2.задача регрессии-задача,подобна классификации,позволяет определить по известным характер-м объекта,значение некоторого его пар-р.значением пар-ра явл-ся множ-во действ.чисел.3.поиск ассоциативных правил-цель-нахождение частных зав-ей или ассоциаций м/у объектами и событиями.найденные зависимости пред-ся в виде правил и м.б.использованы для лучшего понимания анализир-х данных.4.задача кластеризации-заключ в поиске независимых групп кластеров.5.задача прогнозирования-опережающее отражение будущго.цель-предсказание буд событий
13.Задача классификации и регрессии..1.задача классификации-задача своится к опред.классу объектов по его характерм. Значением пар-ра явл-ся конечное множ-во классов2.задача регрессии-задача,подобна классификации,позволяет определить по известным характер-м объекта,значение некоторого его пар-р.значением пар-ра явл-ся множ-во действ.чисел
14.Задача кластеризации. заключ в поиске независимых групп кластеров и их характ-к во всем множ-ве анализир-х данных и в разделении исслед.множ-ва объектов на группы похожих объектов,назыв кластерами.Решение этой задачи помагает лучше понять данные.кроме тог группировка однородных объектов позволяет сократить их число,послед.и облегчить их анализ.
15.Задача поиска ассоциативных правил. цель-нахождение частных зав-ей или ассоциаций м/у объектами и событиями.найденные зависимости пред-ся в виде правил и м.б.использованы для лучшего понимания анализир-х данных.так и для предсказания появления событий.
16.Стадии Data Mining. Свободный поиск.осущ-ся исследование набора данных с целью поиска скрытых закономерностей.закономерность-это сущ.или постоянно повтор.взаимосвязь опред-я этапы и формы процесса становления различных явлений или процессов..система на этой стадии опред-т шаблоны для получения которых в системах olap необх-мо обдумывать или создавать множ-во вопросов.шаблоны ищет за него система.особенно полезно применение данного подхода в сферах больших БД.свободный поиск представлен такими действиями как выявление закономерностей условной логики.выполн при помощи:-индукций и правил условной логики,описание в компактной форме близких объектов,правил ассоциативной логики,опре-е трендов и колебания
17.Стадии Data Mining. Прогностическое моделирование.стадия использует результаты стадии свободного поиска.закономерности использ-ся непосредственно для прогнозирования.Моделир-е включает:-предсказание неизв-х значений,прогнозир-е развития процессов.В процессе моделир-я решаются задачи класссифик.и прогнозирования.прпрогн.моделир-е дедуктивно.закономерности полученные тут м.б прозрачными т.е. допускающими толкование аналитика и непрозрачными-«черными ящиками».
18.Стадии Data Mining. Анализ исключений.анализирутся аномалии выявленные в найденных закономерностях.рассчитыв-ся на стадии свободного поиска. действие, выполняемое на этой стадии, - выявление отклонений. Для выявления отклонений необходимо определить норму, которая рассчитывается на стадии свободного поиска
19. Методы классификации и прогнозирования. Деревья решений. При пом.данного метода решаются задачи классиф. И прогнозирования. Если зависимая, т.е. целевая переменная принимает дискретные значения, при помощи метода дерева решений решается задача классификации. Если же зависимая переменная принимает непрерывные значения, то дерево решений устанавливает зависимость этой переменной от независимых переменных, т.е. решает задачу численного прогнозирования. На этапе построения модели, собственно, и строится дерево классификации или создается набор неких правил. На этапе использования модели построенное дерево, или путь от его корня к одной из вершин, являющийся набором правил для конкретного клиента,используется для ответа на поставленный вопрос " Преимущества деревьев решений: Интуитивность 2. Деревья решений дают возможность извлекать правила из базы данных на естественном языке.3. Алгоритм конструирования дерева решений не требует от пользователя выбора входных атрибутов4.точность.
Дата добавления: 0000-00-00; просмотров: 99 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Весь ад забит женщинами в брюках... | | | Федеральный закон Российской Федерации от 6 апреля 2011 г. N 64-ФЗ |