Читайте также:
|
Физические модели баз данных определяют способы размещения данных в среде хранения и способы доступа к этим данным, которые поддерживаются на физическом уровне.
В каждой СУБД по-разному организованы хранение и доступ к данным, однако существуют некоторые файловые структуры, которые имеют общепринятые способы организации и широко применяются практически во всех СУБД.
В системах баз данных файлы и файловые структуры, которые используются для хранения информации во внешней памяти, можно классифицировать следующим образом:

Файлы с прямым доступом обеспечивают наиболее быстрый способ доступа. Мы не всегда можем хранить информацию в виде файлов прямого доступа, но главное – это то, что доступ по номеру записи в базах данных весьма неэффективен. Чаще всего в базах данных необходим поиск по первичному или возможному ключам, иногда необходима выборка по внешним ключам, но во всех этих случаях мы знаем значение ключа, но не знаем номера записи, который соответствует этому ключу.
В подобных случаях применяют различные методы хэширования и создают специальные хэш- функции. Несмотря на высокую эффективность хэш-адресации, в файловых структурах далеко не всегда удается найти соответствующую функцию, с помощью которой можно было бы полностью избежать коллизий, поэтому при организации доступа по первичному ключу широко используются индексные файлы.
Индексные фaйлы можно представить как файлы, состоящие из двух частей: индексной области и области данных файла (записи БД). В зависимости от организации индексной и основной областей различают 2 типа файлов: с плотным индексом и с неплотным индексом.
В файлах с плотным индексом основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а индексная запись состоит из значения ключа и номера записи:

Здесь значение ключа - это значение первичного ключа, а номер записи - это порядковый номер записи в основной области, которая имеет данное значение первичного ключа.
Неплотный индекс строится именно для упорядоченных файлов. Для этих файлов используется принцип внутреннего упорядочения для уменьшения количества хранимых индексов. Структура записи индекса для таких файлов состоит из значения ключа первой записи блока и номера блока с этой записью.
В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет нам быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области.
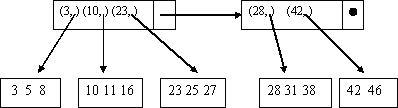
Для обеспечения быстрого доступа к данным на запоминающих устройствах в современных БД используются древовидные структуры данных, хранящиеся во внешней памяти, такие, как B-деревья.
Построение В-деревьев связано с простой идеей построения индекса над уже построенным индексом. В общем случае получим некоторое дерево, каждый родительский блок которого связан с одинаковым количеством подчиненных блоков, число которых равно числу индексных записей, размещаемых в одном блоке. Количество обращений к диску при этом для поиска любой записи одинаково и равно количеству уровней в построенном дереве. Такие деревья называются сбалансированными (balanсed) именно потому, что путь от корня до любого листа в этом древе одинаков.
Дата добавления: 2015-09-01; просмотров: 68 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Нормальные формы. | | | Растровые (матричные) изображения. |