|
Читайте также: |
Рассмотрим сравнение строк на позиции  , где образец
, где образец 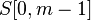 сопоставляется с частью текста
сопоставляется с частью текста 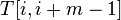 . Предположим, что первое несовпадение произошло между
. Предположим, что первое несовпадение произошло между 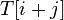 и
и 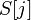 , где
, где 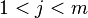 . Тогда
. Тогда 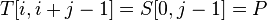 и
и 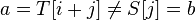 .
.
При сдвиге вполне можно ожидать, что префикс (начальные символы) образца 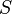 сойдется с каким-нибудь суффиксом (конечные символы) текста
сойдется с каким-нибудь суффиксом (конечные символы) текста 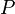 . Длина наиболее длинного префикса, являющегося одновременно суффиксом, есть значение префикс-функции от строки для индекса
. Длина наиболее длинного префикса, являющегося одновременно суффиксом, есть значение префикс-функции от строки для индекса 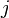 .
.
Это приводит нас к следующему алгоритму: пусть 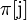 — значение префикс-функции от строки для индекса . Тогда после сдвига мы можем возобновить сравнения с места и
— значение префикс-функции от строки для индекса . Тогда после сдвига мы можем возобновить сравнения с места и 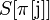 без потери возможного местонахождения образца. Можно показать, что таблица
без потери возможного местонахождения образца. Можно показать, что таблица 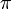 может быть вычислена (амортизационно) за
может быть вычислена (амортизационно) за 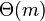 сравнений перед началом поиска. А поскольку строка
сравнений перед началом поиска. А поскольку строка  будет пройдена ровно один раз, суммарное время работы алгоритма будет равно
будет пройдена ровно один раз, суммарное время работы алгоритма будет равно 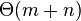 , где
, где 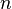 — длина текста .
— длина текста .
35)Алгоритм Боуэра и Мура
Алгоритм основан на трёх идеях.
1. Сканирование слева направо, сравнение справа налево. Совмещается начало текста (строки) и шаблона, проверка начинается с последнего символа шаблона. Если символы совпадают, производится сравнение предпоследнего символа шаблона и т. д. Если все символы шаблона совпали с наложенными символами строки, значит, подстрока найдена, и поиск окончен.
Если же какой-то символ шаблона не совпадает с соответствующим символом строки, шаблон сдвигается на несколько символов вправо, и проверка снова начинается с последнего символа.
Эти «несколько», упомянутые в предыдущем абзаце, вычисляются по двум эвристикам.
2. Эвристика стоп-символа. Предположим, что мы производим поиск слова «колокол». Первая же буква не совпала — «к» (назовём эту букву стоп-символом). Тогда можно сдвинуть шаблон вправо до последней его буквы «к».
Строка: * * * * * * к * * * * * *Шаблон: к о л о к о лСледующий шаг: к о л о к о лЕсли стоп-символа в шаблоне вообще нет, шаблон смещается за этот стоп-символ.
Строка: * * * * * а л * * * * * * * *Шаблон: к о л о к о лСледующий шаг: к о л о к о лВ данном случае стоп-символ — «а», и шаблон сдвигается так, чтобы он оказался прямо за этой буквой. В алгоритме Бойера-Мура эвристика стоп-символа вообще не смотрит на совпавший суффикс (см. ниже), так что первая буква шаблона («к») окажется под «л», и будет проведена одна заведомо холостая проверка.
Если стоп-символ «к» оказался за другой буквой «к», эвристика стоп-символа не работает.
Строка: * * * * к к о л * * * * *Шаблон: к о л о к о лСледующий шаг: к о л о к о л?????В таких ситуациях выручает третья идея АБМ — эвристика совпавшего суффикса.
3. Эвристика совпавшего суффикса. Если при сравнении строки и шаблона совпало один или больше символов, шаблон сдвигается в зависимости от того, какой суффикс совпал.
Строка: * * т о к о л * * * * *Шаблон: к о л о к о лСледующий шаг: к о л о к о лВ данном случае совпал суффикс «окол», и шаблон сдвигается вправо до ближайшего «окол». Если подстроки «окол» в шаблоне больше нет, но он начинается на «кол», сдвигается до «кол», и т. д.
Обе эвристики требуют предварительных вычислений — в зависимости от шаблона поиска заполняются две таблицы. Таблица стоп-символов по размеру соответствует алфавиту (например, если алфавит состоит из 256 символов, то её длина 256); таблица суффиксов — искомому шаблону. Именно из-за этого алгоритм Бойера-Мура не учитывает совпавший суффикс и несовпавший символ одновременно — это потребовало бы слишком много предварительных вычислений.
Опишем подробнее обе таблицы.
Таблица стоп-символов [править | править вики-текст]
Считается, что символы строк нумеруются с 1 (как в Паскале).
В таблице стоп-символов указывается последняя позиция в needle (исключая последнюю букву) каждого из символов алфавита. Для всех символов, не вошедших в needle, пишем 0 (для нумерации с 0 — соответственно, −1). Например, если needle=«abcdadcd», таблица стоп-символов будет выглядеть так.
Символ a b c d [все остальные]Последняя позиция 5 2 7 6 0Обратите внимание, для стоп-символа «d» последняя позиция будет 6, а не 8 — последняя буква не учитывается. Это известная ошибка, приводящая к неоптимальности. Для АБМ она не фатальна («вытягивает» эвристика суффикса), но фатальна для упрощённой версии АБМ — алгоритма Хорспула.
Если несовпадение произошло на позиции i, а стоп-символ c, то сдвиг будет i-StopTable[c].
Таблица суффиксов [править | править вики-текст]
Для каждого возможного суффикса S шаблона needle указываем наименьшую величину, на которую нужно сдвинуть вправо шаблон, чтобы он снова совпал с S. Если такой сдвиг невозможен, ставится | needle | (в обеих системах нумерации). Например, для того же needle=«abcdadcd» будет:
Суффикс [пустой] d cd dcd... abcdadcdСдвиг 1 2 4 8... 8Иллюстрация было??d?cd?dcd... abcdadcd стало abcdadcd abcdadcd abcdadcd abcdadcd... abcdadcdЕсли шаблон начинается и заканчивается одной и той же комбинацией букв, | needle | вообще не появится в таблице. Например, для needle=«колокол»для всех суффиксов (кроме, естественно, пустого) сдвиг будет равен 4.
Суффикс [пустой] л ол... олокол колоколСдвиг 1 4 4... 4 4Иллюстрация было??л?ол...?олокол колокол стало колокол колокол колокол... колокол колоколСуществует быстрый алгоритм вычисления таблицы суффиксов. Этот алгоритм использует префикс-функцию строки.
m = length(needle)pi[] = префикс-функция(needle)pi1[] = префикс-функция(обращение(needle))for j=0..m suffshift[j] = m - pi[m]for i=1..m j = m - pi1[i] suffshift[j] = min(suffshift[j], i - pi1[i])Здесь suffshift[0] соответствует всей совпавшей строке; suffshift[m] — пустому суффиксу. Поскольку префикс-функция вычисляется за O (| needle |) операций, вычислительная сложность этого шага также равняется O (| needle |).
Дата добавления: 2015-07-11; просмотров: 135 | Нарушение авторских прав