Читайте также:
|
В 1977 году два израильских ученых Якоб Зив и Абрахам Лемпел опубликовали работу, положившую начало новой эре в сжатии информации. Практически все современные программы-архиваторы используют ту или иную модификацию алгоритма LZ.
Основная идея первой версии этого алгоритма (алгоритма LZ77) заключается в том, что повторяющиеся последовательности символов заменяются более короткой ссылкой на предыдущую такую же последовательность.
При кодировании данных алгоритм LZ77 использует скользящее по сообщению окно, разделенное на две неравные части. Первая, большая по размеру, включает уже просмотренную часть сообщения и называется словарем. Вторая часть, намного меньшая по размерам, называется буфером. Она содержит еще не закодированные символы входного сообщения. Обычно размер буфера не превышает 100 байт, а словаря - несколько килобайт.
Алгоритм LZ77 пытается искать в словаре такой же фрагмент, который находится в начале буфера и выдает на выход адрес его местонахождения в словаре.
В дальнейшем появились модификации этого алгоритма: LZSS, LZ78, LZW. Рассмотрим работу такого варианта алгоритма LZ, в котором одиночные символы выдаются на выход без сжатия, а вместо последовательности повторяющихся символов указываются ее адрес в словаре и число входящих в нее символов. При этом ASCII код одиночного символа предваряется нулевым битом (префиксом нуля), а пара (адрес, размер) для кодирования последовательности повторяющихся символов - единичным префиксом.
Рассмотрим пример, в котором длина словаря Nсл=32 байта, а длина буфера Nбуф=8 байтов.
Пример 10.
Исходный файл:
Таблица 30
| ABABCABABABCAACAAAACAA |
N0=22 байта.
Этапы работы алгоритма LZ показаны в табл. 31.
Таблица 31
| Словарь | Выходной сигнал | ||||||||||||||||||||||||
| Этап | Адрес позиции в словаре | Буфер | |||||||||||||||||||||||
| ... | Пре- фикс | Адрес | Размер | Приме-чание | |||||||||||||||||||||
| A A B A B A B A B A B C A B A B C A B A B A B A B C A B A B A B C A A B A B C A B A B A B C A A A B A B C A B A B A B C A A C A A | ABABCABA BABCABAB ABCABABA CABABABC ABABABCA ABCAACAA ACAAAACA CAAAACAA AACAAA | 0(A) 0(B) 1(AB) 0(C) 1(ABAB) 1(ABCA) 1(ABCA) 1(CAA) 1(AACAA) | |||||||||||||||||||||||
На первом этапе происходит заполнение буфера содержимым исходного файла. Т.к. словарь к этому моменту пуст, то на выход выдается ASCII код первого символа в буфере - символа A (столбцы 5 и 6), который предваряется префиксом 0 (столбец 4). В целом на выход на этом шаге выдается последовательность 001000001, т.е. 0 и ASCII код символа A, о чем еще раз упоминается в столбце примечания 7. В конце этого этапа содержимое буфера сдвигается на один символ в сторону словаря, а новый символ исходного файла входит в буфер.
На втором этапе также кодируется одиночный символ B и содержимое буфера снова сдвигается на один символ влево.
К третьему этапу работы алгоритма в словаре уже имеется два символа. Поэтому производится сравнение группы из первых двух символов буфера (AB) со всеми группами из двух символов, имеющимися в словаре. Такая группа расположена в словаре по адресу 30. Далее к этой группе необходимо добавить еще один символ из буфера и искать аналогичную группу, т.е. последовательность ABC, в словаре. Если и такая группа символов имеется в словаре, то к ней добавляется еще один символ из буфера и снова ищется подобная последовательность в словаре и т.д. Если на каком-то этапе в словаре не будет больше найдено ни одной идентичной группы символов, то на выход выдаются префикс 1 (столбец 4), адрес местонахождения последней группы символов в словаре (столбец 5) и ее размер (столбец 6). В данном случае вместо 16 битов, требуемых при обычном представлении символов AB, используется только 9 битов: 111110010. В конце третьего этапа содержимое буфера сдвигается уже на два символа и столько же новых символов добавляется в буфер.
Подобная процедура повторяется столько раз, пока через буфер не пройдет содержимое всего файла.
Следует заметить, что при увеличении размеров словаря и буфера появится возможность кодировать более длинные повторяющиеся последовательности символов. Однако при этом увеличивается длина кода каждой последовательности, что снижает эффективность алгоритма LZ при работе с большим числом коротких последовательностей символов. Так, при длине словаря в 4096 байтов, а буфера - в 64 байта общая длина кода любой последовательности будет составлять 12+6=18 битов и эффект от сжатия будет достигаться лишь для последовательностей длиной 3 и более символов.
Однако, как и в других методах сжатия, сжатый файл должен также содержать служебную информацию, которая поможет затем восстановить исходные данные. Для метода LZ в сжатом файле очевидно следует указать использованные при сжатии размеры словаря и буфера. При этом целесообразно запоминать не сами размеры Nсл и Nбуф, а величины Kсл и Kбуф, которые находятся из соотношений:

Тогда полный сжатый файл увеличится на два байта, в которых и будут записаны для нашего примера Kсл=5 и Kбуф=3.
Полный сжатый файл представлен в табл. 32. В ней недостающим в последнем байте разрядам (помеченным?) присвоены нулевые значения.
Таблица 32
| Двоичный сжатый файл | ||||||
| ASCII код сжатого файла | ||||||
| Двоичный сжатый файл | ||||||
| ASCII код сжатого файла | ||||||
| Двоичный сжатый файл | 1??????? | |||||
| ASCII код сжатого файла |
N 1= 13 байтов; K сж= N 1/N 0= 11/22 = 0.59.
Пример 11
Восстановить сообщение из сжатого файла:
Таблица 33
| Тип файла | Значение | |||
| Двоичный ASCII код Символьный |
|

| ! | P |
| Двоичный ASCII код Символьный |
| > |

|

|
| Двоичный ASCII код Символьный | И |
N 1= 10 байтов.
В двух первых байтах содержатся значения Kсл=5 и Kбуф=3. Эти параметры словаря и буфера будем использовать при восстановлении исходного файла.
Процесс восстановления поясняется табл. 34.
Таблица 34
| Словарь | Сжатый двоичный файл | |||||||||||||||||||||
| Этап | Адрес позиции в словаре | |||||||||||||||||||||
| ... | Пре-фикс | ASCII код или (адрес+размер) | Оставшаяся часть сжатого файла | |||||||||||||||||||

| ||||||||||||||||||||||
| C | 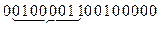
| |||||||||||||||||||||
| C | C | 
| ||||||||||||||||||||
| C | C | A | 
| |||||||||||||||||||
| C | C | A | C | C | A | 
| ||||||||||||||||
| C | C | A | C | C | A | B | 
| |||||||||||||||
| C | C | A | C | C | A | B | C | A | C | 
| ||||||||||||
| C | C | A | C | C | A | B | C | A | C | A | C | C | A | |||||||||
Восстановленный исходный файл:
Таблица 35
| CCACCABCACACCA |
N 0 = 14 байтов; Kсж= 10/14 = 0.71.
Дата добавления: 2015-07-10; просмотров: 62 | Нарушение авторских прав