Читайте также:
|
Одинаковых символов
Метод основан на представлении последовательности одинаковых символов в виде двух величин К и S, где К - количество повторяющихся символов, S - ASCII код этого символа. Следует иметь в виду, что количество повторений К символа S записывается в сжатом файле не арабскими цифрами, а представляется некоторым символом А, номер ASCII кода которого и будет соответствовать количеству повторений К, т.е. А=ASCII(K).
Пример 1.
Исходный файл:
Таблица 1
| NNNMMMLLLLLKNNNNNNNN |
Т.к. каждый символ при обычном представлении внутри ЭВМ занимает один байт памяти, то полная длина исходного файла N0= 20 байтов.
Сжатый файл можно представить табл. 2:
Таблица 2
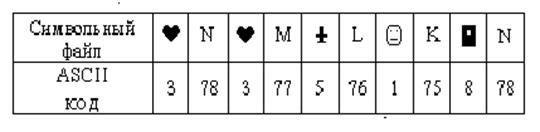
Общее число символов в сжатом файле N1= 10. Коэффициент сжатия Ксж=N1/N0=10/20=0,5. Иногда коэффициент сжатия определяют как Ксж=N0/N1.
Следует иметь в виду, что в некоторых редакторах символы с ASCII кодами 0-31 могут не отображаться на экране. Кроме того, т.к. они относятся к управляющим символам, то их наличие в файле может привести к некоторым действиям, например переводу последующей части файла на следующую строку экрана или табуляции (когда последующий символ сдвигается относительно предыдущего на определенное число символьных позиций). Причем в различных редакторах действия этих управляющих символов могут быть различными.
В дальнейшем для упрощения записи, если ASCII код символа меньше 31, вместо этого символа будет указываться подчеркнутый номер его ASCII кода, а если больше 31, то этот символ может указываться как обычно или вместо него также может стоять подчеркнутый ASCII код. Так, сжатый файл в примере 1 можно записать следующим образом:
Таблица 3
| 3 N 3 M 5 L 1 K 8 N |
Пример 2.
Исходный файл:
Таблица 4
| Таблица ASCII-кодов. |
Сжатый файл:
Таблица 5
| 1 T 1 a 1 б 1 л 1 и 1 ц 1 а 11 А 1 S 1 C 2 I 1 - 1 к 1 о 1 д 1 о 1 в 1. |
N0= 20 байтов; N1= 38 байтов; Ксж= N1/N0= 38/20 = 1,9. Видим, что в данном примере сжатый файл получился больше исходного.
Пример 3.
Исходный файл:
Таблица 6
| X=5.2*******Y=5.********C=0.********D=4. |
Сжатый файл:
Таблица 7
| 1 X 1 = 1 5 1. 1 2 7 * 1 Y 1 = 1 5 1. 8 * 1 C 1 = 1 0 1. 8 * 1 D 1 = 1 4 1. |
N0= 40 байтов; N1= 40 байтов; Ксж= N1/N0= 40/40 = 1.
Для восстановления исходного файла необходимо разбить сжатый файл на группы по два символа и вставить в исходном файле такой же символ, который стоит в группе на втором месте. Причем число повторений этого символа указано в начале каждой группы.
Пример 4.

Сжатый файл:
Таблица 8
!* 1 Т 1 а 1 б 1 л 1 и 1 ц 1 а  * 1131101 1 1., * 1 к 1 о 1 д * 1131101 1 1., * 1 к 1 о 1 д
|
Исходный файл (видимый символьный файл):
Таблица 9
| *********************************Таблица******** 1.********************************************код |
Главный недостаток рассматриваемого метода сжатия проявляется, если сжимаемый файл содержит данные в виде последовательности различных символов. В этом случае выходной файл будет больше, чем исходный (смотри пример 2). Это объясняется тем, что для записи любой строки повторяющихся символов, даже единичной длины, всегда требуется два байта. Выигрыш в объеме файла при использовании обычного алгоритма сжатия последовательности одинаковых символов будет достигнут, если средняя длина каждой группы будет > 2.
Однако во многих случаях можно использовать модификацию рассмотренного метода - адаптивный алгоритм сжатия последовательностей одинаковых символов.
В этом методе группы одинаковых символов длиной в 1 и 2 символа передаются в выходной файл без изменения, а вместо групп одинаковых символов длиной 3 и более символов в сжатом файле вставляется комбинация символов (S1S2S3) где S1 - специальный символ, означающий, что два последующих за ним символа кодируют группу одинаковых символов; S2 указывает число повторений символа; S3 - ASCII код самого символа. В качестве специального символа S1 может использоваться ASCII символ, который не входит в данный файл. Т.е. перед собственно сжатием необходимо просмотреть весь сжимаемый файл и определить, все ли 256 ASCII символов присутствуют в нем.
Если исходный файл содержит все 256 ASCII символов, то сжатие адаптивным методом невозможно и следует использовать обычный метод сжатия последовательностей одинаковых символов. Если в исходном файле встречаются не все возможные 256 ASCII символов, то любой из отсутствующих ASCII символов выбирается в качестве специального символа S1. Чтобы программа-декодер смогла восстановить исходный файл, в сжатом файле необходимо указать, какой ASCII символ используется в качестве специального символа S1. Кроме того, необходимо указать, какой тип алгоритма (обычный или адаптивный) использован для сжатия данных. Рассмотрим старый пример 3:
Исходный файл:
Таблица 10
| X=5.2*******Y=5.********C=0.********D=4. |
Сжатый файл:
Таблица 11
| 23X=5.23 7 *Y=5.3 8 *C=0.3 8 *D=4. |
N0 = 40 байтов; N1 = 28 байтов; Kсж= N1/N 0= 28/40 = 0.7, в то время как при использовании обычного алгоритма Kсж = 1. В сжатом файле первый символ 2 означает, что используется адаптивный алгоритм. Если бы использовался обычный алгоритм, то первым символом была бы 1. На втором месте стоит символ ASCII 3, который используется в качестве специального символа S1.
Если первым символом сжатого файла является 2, то декодирование сжатого файла начинается с его третьего символа. Если очередной символ сжатого файла не равен символу S1, то этот символ записывается в восстанавливаемый файл. Если очередной символ сжатого файла f1 равен S1, то считываются еще два следующих за ним символа fi+1 и fi+2 и в восстанавливаемый файл записывается группа из символов fi+2, размер которой определяется номером ASCII кода символа fi+1.
Если первым символом сжатого файла является 1, то декодирование начинается со второго символа и происходит по правилам декодирования обычного алгоритма сжатия последовательностей одинаковых символов.
Пример 6.
Сжатый файл:
Таблица 12
| 2XX!*ПРИЛОЖЕНИЕ |
Восстановленный файл:
Таблица 13
| *********************************ПРИЛОЖЕНИЕ |
N1= 15 байтов; N0= 43 байта; Kсж= N1/N0= 15/43 = 0.35.
Пример 7.
Сжатый файл:
Таблица 14
| 1 1 X 1 1 1 = 1 0 1. 1 3 1; 20 * 1 Y 1 = 1 0 |
Восстановленный файл:
Таблица 15
| X1=0.3;********************Y=0 |
N1 = 24 байта; N0 = 30 байтов; Kсж = N1/N0= 24/30 = 0.8
Дата добавления: 2015-07-10; просмотров: 98 | Нарушение авторских прав