Читайте также:
|
Для описания выборочного распределения, как правило, используются следующие известные параметры [1, 11, 15]:
1. Среднее арифметическое:
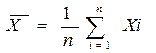 ; где:
; где:
Xi; - балл i-того испытуемого;
n - количество испытуемых в выборке (объем);
Выборочная, или средняя, квадратическая ошибка средней арифметической:
 .
.
2. Среднее квадратическое (стандартное) отклонение:

Σ - сумма квадратов тестовых баллов для n испытуемых.
Средняя ошибка среднего квадратического (стандартного) отклонения:
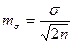 .
.
Стандартная ошибка среднего арифметического (математического ожидания) оценивается по формуле: на основе ошибки математического ожидания строятся доверительные границы, в которых заключена величина генеральной средней:  .
.
Если тестовый балл какого-либо испытуемого попадает в границы доверительного интервала, то нельзя считать, что испытуемый обладает повышенным (или пониженным) значением измеряемого свойства с заданным уровнем статистической вероятности.
Оценка достоверности вычисленных статистик производится по следующим формулам:
Критерий достоверности различий, наблюдаемых между средними арифметическими двух независимых выборок:
 .
.
3. Асимметрия:
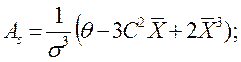
где: Х - среднее арифметическое;
σ - стандартное отклонение;
θ - среднее кубическое:  ;
;
С - среднее квадратическое:  ;
;
Р - частота появления варианты.
Коэффициент асимметрии величина не именованная. Он колеблется в пределах от нуля до единицы. При совершенно симметричных распределениях коэффициент асимметрии равен нулю. Асимметрия считается незначительной, если 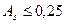 . При
. При  скошенность распределения оказывается уже значительной.
скошенность распределения оказывается уже значительной.
4. Эксцесс:  ,
,
Q - среднее значение четвертой степени: 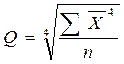
При положительном эксцессе показатель 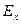 - число положительное, а при отрицательном - - число отрицательное. Если ≤ 0,2, эксцесс практически отсутствует; если же ≥0,5, но ≤ 1, эксцесс считается заметным, но небольшим. Предельное значение отрицательного равно - 2, что указывает на наличие распределения с двумя вершинами.
- число положительное, а при отрицательном - - число отрицательное. Если ≤ 0,2, эксцесс практически отсутствует; если же ≥0,5, но ≤ 1, эксцесс считается заметным, но небольшим. Предельное значение отрицательного равно - 2, что указывает на наличие распределения с двумя вершинами.
Асимметрия и эксцесс нормального распределения должны быть равны нулю. Если они существенно отклоняются от нуля (хотя бы один из двух параметров), то это означает, что полученное эмпирическое распределение анормально.
Проверку значимости асимметрии можно произвести на основе общего неравенства Чебышева:
 ; ("а")
; ("а")
где:
 - дисперсия эмпирической оценки асимметрии:
- дисперсия эмпирической оценки асимметрии:
 , где
, где
р - уровень значимости или вероятность ошибки первого рода; ошибки в том, что будет принят вывод о незначимости асимметрии, при наличии значимой асимметрии (в формулу подставляют стандартные р= 0,05 или р= 0,01 и проверяют выполнение неравенства).
Сходным образом оценивается значимость эксцесса:
 , ("б")
, ("б")
где:
 -эмпирическая дисперсия оценки эксцесса, определяется по формуле:
-эмпирическая дисперсия оценки эксцесса, определяется по формуле:

Гипотезы об отсутствии асимметрии и эксцесса принимаются с вероятностью ошибки р (пренебрежимо малой), если выполняются неравенства ("а") и ("б").
Если проверка согласованности эмпирического распределения с нормальным дает положительные результаты, то это означает, что полученное распределение можно рассматривать как устойчивое - репрезентативное по отношению к генеральной совокупности - а, значит, на его основе можно определить репрезентативные тестовые нормы. Если проверка не выявляет нормальности на заданном уровне, то это означает, что или выборка мала и нерепрезентативна к популяции, или измеряемое свойство и устройство теста (способ подсчета) вообще не дают нормального распределения [15].
В принципе, требование нормальности распределения не является обязательным. Можно с равным успехом пользоваться другими хорошо разработанными моделями гамма-распределения, пуассоновского распределения и т.п. Критерий Колмогорова позволяет оценить близость эмпирического распределения к любому теоретическому распределению. При этом устойчивым и репрезентативным может оказаться распределение любого типа. Если из нормальности, как правило, следует устойчивость, то обратное неверно - устойчивость вовсе не обязательно предполагает нормальность распределения.
Наличие значимой положительной асимметрии свидетельствует о том, что в системе факторов, детерминирующих значение измеряемого показателя, преобладают факторы, действующие в одном направлении - в сторону повышения показателя.
На практике распределения такого рода преобразуют в нормальное (приближенно нормальное) с помощью логарифмической трансформации: Z = Ln y. При этом говорят, что распределение показателей подчиняется "логнормальному" закону.
Подобную алгебраическую нормализацию тестовой шкалы применяют к показателям с еще более резко выраженной положительной асимметрией.
Например, в процедурах контент-анализа сам тестовый показатель является частотным - он измеряет частоту появления определенных категорий событий в текстах.
Дата добавления: 2015-07-10; просмотров: 92 | Нарушение авторских прав