Читайте также:
|
Модели выявленных предпочтений являются развитием пространственных моделей, таких, как модель Рейли [15]. Смысл состоит в том, чтобы на основе фактических пространственных данных о выборе магазинов респондентами оценить параметры модели для прогноза рыночной доли. Если в модели Рейли значения параметров фиксированы, то здесь они оцениваются эконометрическим путем. На основе доли предприятия можно оценить оборот, прибыль и привлекательность той или иной точки. Кроме того, данный метод позволяет вместе с местом выбрать и оптимальную концепцию предприятия для каждого варианта размещения.
В соответствии с аксиомой Люса [11] полагается, что вероятность выбора Pij потребителем i определенной торговой точки j равна доле, которую составляет полезность использования этой точки Uij в сумме полезностей всех n возможных магазинов. Каждый потребитель может выбрать только одну торговую точку и не меньше, чем одну. Формула выглядит следующим образом:

(1)
Индекс i соответствует потребителю или, в общем случае, некоторой ситуации выбора. При использовании этой модели в розничной торговле под ситуацией чаще всего понимается район проживания потребителя, хотя можно учитывать также его социально-демографические характеристики и наличие автомобиля.
Данная модель, наряду с логит- и пробит-моделями<2> для вероятностей выбора, достаточно часто используется для прогнозирования долей рынка различных потребительских товаров и услуг. Если мы подставим в эту формулу функцию полезности мультипликативного вида, то получим формулу модели мультипликативного взаимодействия (MCI). Ее частным случаем является известная модель Хаффа [6], включающая только два параметра — площадь торговой точки и ее удаленность от потребителя в ситуации i:

(2)
| где | Tij | — | удаленность торговой точки j от потребителя в ситуации i; |
| Sj | — | площадь торговой точки j; | |

| — | некоторый положительный параметр, требующий статистической оценки (обычно принимает значения от единицы до трех); | |
| n | — | число торговых точек. |
<2> Регрессионные модели, включающие в простейшем случае или логистическое преобразование (логит-модель), или преобразование по формуле стандартного закона нормального распределения (пробит-модель) по отношению к линейной функции от регрессоров. Оцениваются методом максимального правдоподобия.
В общем же случае выражение для вероятности выбора потребителем определенной точки в MCI выглядит следующим образом [12]:

(3)
| где | xkij | — | k-я переменная, описывающая точку j в ситуации выбора i; |
| Bk | — | показатель чувствительности функции полезности к k-й переменной (или уровень эластичности по этой переменной); | |
| q | — | число переменных, участвующих в функции полезности. |
Кроме того, используется функция полезности мультиномиального вида (MNL):

(4)
Выбор функции определяется характером зависимости маркетингового эффекта (доли рынка) от значений факторов. Модель MCI применяется в тех случаях, когда эластичность доли по значениям переменных убывает (например, площадь торговой точки), тогда как MNL предполагает наличие точки максимальной эластичности при ненулевых значениях переменной (расходы на рекламу).
Для оценки коэффициентов bk необходимо знание факторов xkij и вероятностей выбора Pij. Значения этих переменных привязаны к определенным «ситуациям выбора», то есть к ситуациям, для которых предполагаются одинаковые условия выбора (значения переменных не меняются от случая к случаю). Аналитик свободен в определении факторов, участвующих в выделении ситуаций выбора и в уравнении регрессии. Как правило, факторы, разграничивающие огромное множество всех ситуаций на искусственные группы или «ситуации выбора», одновременно входят в уравнения (3—4) в качестве регрессоров.
Каждую ситуацию выбора мы должны ассоциировать с соответствующими вероятностями Pij и переменными xkij. Так как истинные значения вероятностей нам не известны, то они заменяются усредненными по каждой ситуации оценками распределения предпочтений потребителей pij. В другом случае, когда множество ситуаций выбора совпадает с множеством респондентов, вероятности оцениваются через распределение числа визитов, совершенных данным потребителем.
В число факторов включаются переменные, описывающие торговую точку, и переменные, описывающие потребителя (расстояние до точки, наличие автомобиля). Например, перечень, предложенный [8], включает семь атрибутов для торгового центра: ассортимент, время пути до центра, дизайн, время работы, уровень цен, атмосферу и информативность. Значение этих переменных оценивается потребителями самостоятельно. Возможен и подход, в котором эти характеристики оцениваются экспертно. Например, в перечень переменных, оцененных экспертным путем, могут войти следующие: время в пути, площадь торговой точки (как приближение для ассортимента), наличие парковки, уровень цен, дизайн. Следует отметить, что в модель MCI мы можем включить только переменные, от которых доля предприятия на локальном рынке и эластичность доли должны зависеть монотонно (только возрастать или только убывать). В частности, мы не можем использовать переменные сегментирования и переменные, заведомо имеющие оптимальный уровень для доли (уровень освещенности, доля сопутствующих товаров).
Данные, необходимые для калибровки модели, почти всегда собираются путем полевого исследования<3>. Специалист должен выбрать территорию исследования. В случае небольшого или среднего города территория будет равна территории всего города. Если же исследуется рынок города-миллионера, то возможно ограничить исследование только территорией вблизи предполагаемого места (но с радиусом не менее двух километров).
<3> В некоторых случаях можно обойтись геоинформационной системой (ГИС) — комплексом из программы и данных, предназначенных для отображения и анализа пространственных данных.
Разбиение выборки на ситуации может производиться уже после полевого этапа, хотя обычно необходима хотя бы территориальная стратификация. Таким образом, вся территория исследования разбивается на ряд небольших районов. В каждом районе опрашивается определенное количество домохозяйств с целью выяснения их предпочтений.
Здесь следует отметить два тонких момента: выбор числа районов и выбор способа измерения предпочтений потребителей.
Модель (3—4) оставляет достаточно много свободы для описания предпочтений, а именно, для интерпретации P. Схема не запрещает использование в качестве усредненной оценки распределения расходов, что должно дать на выходе модели прогнозы оборота. Часто же под P понимается распределение визитов или распределение торговых точек по критерию максимальной важности для потребителя. В последнем случае выборка искусственно ограничивается теми домохозяйствами, которые совершают основную часть покупок данной категории только в одной торговой точке. Проблема измерения предпочтений сводится к проблеме постановке основных вопросов.
Эффективность способов описания предпочтений определяется типом предприятия, для которого производится исследование. Для торгового центра возможны следующие варианты основного вопроса:
| 1. | Назвать центр, в котором совершается подавляющая часть покупок [17]. |
| 2. | Назвать центр, в который потребитель скорее всего пойдет за покупками в следующий раз [16]. |
| 3. | Указать распределение числа визитов за покупками по торговым центрам [5]. |
| 4. | Указать распределение расходов на одежду по торговым центрам [16]. |
Для специализированных магазинов наиболее подходящим кажется вопрос о распределении расходов.
После получения массива подготовленных для анализа данных проводится расчет оценок долей P и параметров потребителей. С этими данными аналитик оценивает модель (3) методами наименьших квадратов или максимального правдоподобия. Второй метод в силу характера вычислений не гарантирует получения действительной величины оценки, поэтому лучше использовать метод наименьших квадратов. Путем несложных алгебраических операций выражение (3) удается привести к линейному виду относительно коэффициентов. В наиболее распространенном варианте уравнение регрессии для MCI будет выглядеть следующим образом:

(5)
Для MNL используется иное уравнение:

(6)
В уравнениях (5—6)  обозначает геометрическое среднее вероятностей выбора различных объектов в ситуации i; Xki — геометрическое среднее значений k-й переменной для всех торговых точек в ситуации i,
обозначает геометрическое среднее вероятностей выбора различных объектов в ситуации i; Xki — геометрическое среднее значений k-й переменной для всех торговых точек в ситуации i, 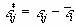 и
и  — арифметическое среднее ошибки по всем объектам для ситуации i.
— арифметическое среднее ошибки по всем объектам для ситуации i.
Для этой модели требуется измерение всех переменных в относительной шкале, то есть переменные, полученные на основе методов сокращения размерности, здесь неприемлемы. Тем не менее, существуют варианты записи модели, для которых может быть использована интервальная шкала.
К сожалению, для ошибок модели характерна гетероскедастичность4 [12]. Выражения для вариации и ковариации ошибок в модели зависят от формы основного вопроса, и обсуждение этого вопроса выходит за рамки обзорной статьи. Отметим, что для повышения качества оценок используется обобщенный метод наименьших квадратов. Возможно использование и стандартного метода, но в таком случае точность оценки коэффициентов будет ниже. Применение обобщенного метода наименьших квадратов для калибровки моделей дискретного выбора подробно описано в [12]. Кроме того, общие принципы можно узнать из [1].
Модели выявленных предпочтений имеют минимум два важных преимущества. Первое состоит в возможности получения количественного результата с максимальной точностью. Отметим, что точность моделей может быть повышена за счет учета взаимодействия между факторами, которое вводится в модель (3—4) ценой некоторого усложнения. Точность прогнозов из модели выявленных предпочтений немного выше, чем у регрессионных моделей и аналоговых методов. Большее значение имеет второе преимущество, заключающееся в лучшей интерпретируемости результатов. Из модели MCI или MNL мы можем легко вычислить эластичность доли рынка по любой переменной и выбрать оптимальную концепцию центра, исходя из максимизации прибыли девелопера. Преимущества данной методики особенно очевидны, когда ставится задача выбора местоположения для более чем одной торговой точки.
Применение модели ограничивается случаями исследования рынков, находящихся в состоянии относительной стабильности. Если в развитии розничной торговли города в ближайшее время предполагаются значительные изменения (в том числе, за счет реализации рассматриваемого проекта), то модель, откалиброванная на текущих данных, будет неверна для будущего (context dependency problem). В частности, параметр чувствительности к расстоянию существенно меняется вместе с пространственной структурой розничной торговли города. Кроме того, чувствительность к параметрам, по которым существующие торговые точки различаются мало, будет очень низка или статистически незначима.
Эта проблема особенно актуальна для России. В настоящее время в большинстве региональных столиц крупные торговые центры проектируются в условиях отсутствия фактической конкуренции. Вместе с тем ожидается достаточно высокий уровень конкуренции после завершения строительства, поэтому как выбор местоположения, так и концепции объекта являются для девелопера очень важными решениями. Использование в данном случае модели выявленных предпочтений в ее базовом варианте, несмотря на высокую мощность метода, приведет к некорректным результатам.
В данный момент мы считаем возможным применение методики для торговых центров в Москве, Санкт-Петербурге, Екатеринбурге. Для супермаркетов территория возможного применения методики значительно шире и распространяется на большинство региональных столиц.
Очевидный недостаток метода выявленных предпочтений заключается в необходимости проведения полевого исследования с довольно сложным вопросником. В случае, если в качестве основного вопроса используется вопрос о последнем месте совершения покупок, размер выборки, по нашим оценкам, должен составлять не менее 2000 респондентов целевого сегмента. В таком случае мы используем приемлемый размер выборки для построения регрессии (около 30 наблюдений) и ошибку оценки доли +/–10 процентных пунктов с доверительной вероятностью 0,9. Но для вопроса о распределении числа визитов приемлем значительно меньший размер выборки (от 300—400 респондентов).
С другой стороны, полевое исследование является весьма желательным этапом процесса выбора местоположения торговой точки (которое часто происходит одновременно с выбором концепции). Поэтому ценой использования метода выявленных предпочтений в данном случае будет лишь включение 7—10 закрытых вопросов в анкету.
Заключение
Мы рассмотрели основные модели, применяемые для выбора местоположения торговой точки. При этом метод выявленных предпочтений был рассмотрен более подробно ввиду его новизны для российской практики и большей сложности. Вместе с тем, нам не хотелось бы рекомендовать применение во всех случаях только одного метода. Каждый из перечисленных вариантов решения проблемы может быть назван наилучшим для определенных ситуаций. Мы постарались дать характеристику случаев, в которых использование данной модели оптимально.
Но главным выводом из нашей статьи мы хотели бы сделать вывод о многообразии и достаточно высокой мощности методов, существующих в маркетинговой науке для обеспечения принятия решения по выбору местоположения торговой точки. В России активно применяются только два метода из четырех (метод контрольного списка и аналоговый метод). Вместе с тем, с развитием розничной торговли применение более точных методов становится все более оправданным. Надеемся, что эта статья позволит несколько повысить качество принятия решений в области размещения торговых предприятий.
http://dis.ru/library/520/25648/
Дата добавления: 2015-09-05; просмотров: 68 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Регрессионный анализ | | | Понятие и предмет философии права |