|
Читайте также: |
будет получен следующий результат, представленный на рисунке 20.

Рис. 20. Декартово произведение таблиц project и department
В данном случае среда для выполнения запросов преобразовала наименование колонки department.dept_no в dept_no_1 для исключения дублирования.
Если добавить в запрос условие WHERE p.dept_no = d.dept_no, то из декартова произведения таблиц будут выбраны только те строки, в которых значения колонок project.dept_no и department.dept_no равны, то есть для запроса вида
SELECT p.*, d.* FROM project p, department d
WHERE p.dept_no = d.dept_no
будет получен результат, представленный на рисунке 21.
 Рис. 21. Промежуточный результат объединения таблиц project и department
Рис. 21. Промежуточный результат объединения таблиц project и department
Теперь можно ограничить количество выбираемых колонок и получить заключительный вариант запроса и результат его выполнения (рисунок 22):
SELECT p.proj_no, p.proj_name, d.dept_no,
d.dept_name
FROM project p, department d
WHERE p.dept_no = d.dept_no

Рис. 22. Окончательный результат объединения таблиц project и department.
Такой вариант объединения называется простым (simple join).
Пример 10. Для всех проектов необходимо выбрать следующую информацию: номер проекта, название проекта, номер подразделения и название подразделения.
В данном примере подразумевается, что проекту может быть не поставлено в соответствие подразделение-исполнитель, т.е. в колонке dept_no таблицы project может храниться неопределенное значение (NULL). В этом случае речь идет о внешнем объединении таблиц (outer join). Внешнее объединение в общем случае отбирает больше строк, чем простое объединение. При выполнении операции внешнего объединения отбираются все строки, которые были бы отобраны при выполнении операции простого объединения и дополнительно отбираются строки из одной таблицы, которым не обнаружено соответствия по используемому критерию отбора ни с одной строкой другой таблицы.
Внешнее объединение отображается в конструкции WHERE в одной из двух форм:
[таблица1.]столбец = [таблица2.]столбец (+)
или
[таблица1.]столбец (+) = [таблица2.]столбец
Символы внешнего объединения “ (+)” должны следовать непосредственно за колонкой, по отношению к которой выполняется внешнее объединение. Для лучшего запоминания того, где необходимо ставить символы “ (+)”, можно использовать следующее правило: знак внешнего объединения ставится после наименования той колонки, на которую будут отсутствовать ссылки из связанной таблицы.
В рассматриваемом примере внешнее объединение выполняется по отношению к колонке dept_no таблицы department, поэтому запрос для решения поставленной задачи будет иметь вид:
SELECT p.proj_no, p.proj_name, d.dept_no,
d.dept_name
FROM project p, department d
WHERE p.dept_no = d.dept_no (+)
Результат выполнения этого запроса представлен на рисунке 23.

Рис. 23. Результат внешнего объединения
таблиц project и department
Если же символ внешнего объединения поставить после указания колонки dept_no таблицы project, то выполнится запрос, который вернет информацию о всех отделах и тех проектах, которые ими выполняются, причем информация об отделе будет присутствовать независимо от того, есть выполняемые этим отделом проекты или нет. То есть в результате выполнения запроса вида:
SELECT p.proj_no, p.proj_name, d.dept_no,
d.dept_name
FROM project p, department d
WHERE p.dept_no (+) = d.dept_no
мы получим следующую выборку, показанную на рисунке 24.

Рис. 24. Альтернативный результат внешнего объединения
таблиц project и department
После выполнения запроса может быть получено некоторое множество строк. Каждая строка имеет в рамках данного множества свой номер, называемый ROWNUM. Вычисление ROWNUM, как показано на рисунке 18, происходит автоматически после выполнения конструкции WHERE. Это позволяет использовать данный номер ROWNUM при организации условия, указываемого после ключевого слова WHERE.
Пример 11. Выбрать информацию о номере и наименовании любого из существующих проектов.
Для получения такой выборки можно использовать запрос вида:
SELECT proj_no, proj_name FROM project WHERE ROWNUM < 2
В результате запроса из всех строк, содержащих номера и соответствующие наименования проектов, будет получена максимум одна строка, которая в перечне строк имеет номер 1.
Для организации группировки отобранных данных с целью их совместной обработки используется синтаксическая конструкция GROUP BY. Совместная обработка данных обычно сводится к вычислению некоторой агрегатной функции: суммы значений указанной колонки, среднего значения указанной колонки, числа элементов множества отобранных значений указанной колонки и т. п.
Ключевое слово HAVING используется для формирования дополнительных условий включения групп в результат запроса.
Использование ключевого слова GROUP BY приводит к тому, что оператор SELECT выдает одну производную строку для каждой группы строк, формируемых на основе одинаковых значений для столбцов или выражений. Все столбцы и выражения, которые указываются в конструкции GROUP BY и по которым осуществляется группировка, должны присутствовать в списке после ключевого слова SELECT. В противном случае при выполнении запроса будет получено сообщение об ошибке.
Синтаксис конструкции группировки строк имеет вид:
GROUP BY выражение [, выражение ]... [ HAVING условие ]
Элемент выражение может быть колонкой, константой или функцией от них.
Ключевое слово HAVING используется для уточнения, какие группы будут включаться в окончательный результат. Запросы, содержащие ключевые слова GROUP BY и HAVING, обрабатываются Oracle следующим образом:
1) из рассмотрения удаляются все строки, не удовлетворяющие условию WHERE (если это условие присутствует);
2) вычисляются и формируются группы в соответствии с предложением GROUP BY;
3) из результирующего множества удаляются все группы, не удовлетворяющие условию HAVING.
Синтаксис использования агрегатных функций может быть представлен следующими двумя вариантами:
АГРЕГАТНАЯ_ФУНКЦИЯ ([ ALL ] выражение)
АГРЕГАТНАЯ_ФУНКЦИЯ (DISTINCT выражение)
При выполнении вычислений для агрегатных функций по умолчанию используется ключевое слово ALL, которое указывает, что результат включает все значения колонки, в том числе и дублирующиеся. Если в запросе использовано ключевое слово DISTINCT, то групповые функции рассматривают только отличающиеся (уникальные) значения колонок или выражений. Все агрегатные функции, кроме функции COUNT, не учитывают в вычислениях поля, имеющие неопределенное значения (NULL). Для замены неопределенного значения на какое-либо конкретное значение используется встроенная в Oracle функция NVL. К числу основных агрегатных функций относятся функции COUNT, AVG, MIN, MAX, SUM. Рассмотрим на примерах использование агрегатных функций.
Пример 12. Создать запрос, который будет возвращать номер отдела и количество проектов, выполняемых им.
Пусть в таблице project имеются записи, представленные на рисунке 25:

Рис. 25. Содержимое таблицы project
Для получения нужной информации запрос должен иметь следующий вид:
SELECT dept_no, COUNT(*) FROM project GROUP B Y dept_no
В этом запросе применяется группировка по значениям колонки dept_no и используется агрегатная функция COUNT, которая подсчитывает для каждой группы записей количество таких записей. Т.к. нет необходимости подсчитывать количество значений в каких-либо конкретных колонках, то в скобках у агрегатной функции COUNT пишется символ ‘*’. Результат выполнения запроса будет иметь вид, представленный на рисунке 26.

Рис. 26. Результат запроса с использованием
агрегатной функции COUNT
Значение ключевых слов ALL и DISTINCT, и их использование в агрегатных функциях можно пояснить на следующем примере.
Пример 13. Создать запрос, который будет возвращать общее количество проектов и общее количество отделов, задействованных для их реализации.
В данном случае для вычисления общего количества проектов можно использовать либо агрегатную функцию COUNT(*), которая подсчитает общее количество записей, либо агрегатную функцию COUNT(ALL proj_no) или COUNT(proj_no), которая подсчитает общее количество значений в колонке proj_no. Т.к. один и тот же отдел может реализовывать несколько проектов, то для подсчета общего количества отделов с учетом того, что значения колонки dept_no могут дублироваться, потребуется использование агрегатной функции вида COUNT(DISTINCT dept_no). В данном случае группировка не требуется. Запросы могут быть представлены в следующем виде:
SELECT COUNT(*), COUNT(DISTINCT dept_no) FROM project
или
SELECT COUNT(ALL proj_no), COUNT(DISTINCT dept_no) FROM project
или
SELECT COUNT(proj_no), COUNT(DISTINCT dept_no) FROM project
Результат выполнения данных запросов показан на рисунке 27.

Рис. 27. Результат запроса с использованием
агрегатной функции COUNT и ключевого слова DISTINCT
Пример 14. Создать запрос, который будет возвращать номер отдела и средний бюджет проектов этого отдела.
Для составления такого запроса необходимо использовать агрегатную функцию вычисления среднего значения AVG, которая возвращает среднее значение, не включая в вычисления неопределенные значения (NULL). Запрос будет иметь следующий вид:
SELECT dept_no, AVG (budget) FROM project
GROUP BY dept_no
Результат выполнения данного запроса показан на рисунке 28.

Рис. 28. Результат запроса с использованием
агрегатной функции AVG
Как видно из результата, для отдела с номером 3 будет подсчитано среднее значение 2500, поскольку для этого отдела существуют в таблице project 3 записи со значениями колонки proj_no, равными 4, 5 и 6, и для проектов с номерами 4 и 6 указаны бюджеты, равные 2000 и 3000 соответственно, а для проекта с номером 5 значение колонки budget содержит неопределенное (NULL) значение.
Если требуется рассматривать значение NULL колонки budget как нулевой бюджет проекта, то необходимо использовать встроенную в Oracle функцию NVL. Эта функция имеет следующий синтаксис:
NVL (выражение_1, выражение_2)
Если выполняется условие выражение_1 IS NULL, то функция возвращает в качестве результата выражение_2; в противном случае возвращается само выражение_1. Например, выражение NVL(budget, 0) будет возвращать либо конкретное значение, хранящееся в колонке budget, либо 0, в случае если колонка budget содержит значение NULL
С учетом этих замечаний можно представить запрос иначе:
SELECT dept_no, AVG (NVL (budget, 0)) FROM project
GROUP BY dept_no
Результат такого запроса будет иметь вид, представленный на рисунке 29 (среднее значение бюджета для отдела номер 3 изменилось).

Рис. 29. Результат запроса с использованием
агрегатной функции AVG и функции NVL
Пример 15. Создать запрос, который будет возвращать номера отделов, а также минимальные и максимальные значения бюджетов проектов, реализуемых ими.
В данном случае применяются агрегатные функции вычисления минимального и максимального значений, не включая в вычисления неопределенные значения NULL. Это функции MIN и MAX. Требуемый запрос будет иметь вид:
SELECT dept_no, MIN (budget), MAX (budget)
FROM project
GROUP BY dept_no
Результат его выполнения представлен на рисунке 30.

Рис. 30. Результат запроса с использованием
агрегатных функций MIN и MAX
Пример 16. Создать запрос, который будет возвращать номера отделов и сумму бюджетов проектов, реализуемых ими.
Для реализации запроса используется агрегатная функция SUM, подсчитывающая сумму значений, не включая в вычисления неопределенные значения (NULL). Ниже представлен текст запроса и результат его выполнения (рисунок 31).
SELECT dept_no, SUM (budget) FROM project
GROUP BY dept_no

Рис. 31. Результат запроса с использованием
агрегатной функции SUM
Пример 17. Написать запрос, выбирающий данные о номерах отделов, средний бюджет проектов которых превышает средний бюджет проектов организации. Для контроля результата представить данные, содержащие номер отдела и его средний бюджет. Проекты, бюджет которых не определен, при расчетах не учитывать.
Этот пример позволяет продемонстрировать использование условия отбора групп, указываемое после ключевого слова HAVING.
Запрос, возвращающий среднее значение бюджета проектов для всей организации имеет вид:
SELECT AVG (budget) FROM project
Данный запрос предполагает, что проекты с неопределенным значением бюджета не учитываются при подсчете среднего значения. Такой запрос сформирует результат, показанный на рисунке 32.
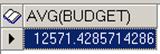
Рис. 32. Результат запроса,
подсчитывающего среднее значение бюджета всех проектов
Запрос, формирующий список отделов и средний бюджет их проектов, имеет вид (неопределенные значения бюджетов не учитываются):
SELECT dept_no, AVG (budget) FROM project
GROUP BY dept_no
Из результата этого запроса (рисунок 33) видно, что только отделы с номерами 2 и 4 имеют средний бюджет проектов, превышающий средний бюджет проектов организации в целом.

Рис. 33. Результат запроса, возвращающего список отделов
и средний бюджет их проектов
Чтобы получить информацию только об этих двух отделах, необходимо на результат группировки наложить дополнительное условие отбора групп, которое указывается после ключевого слова HAVING.
Запрос примет вид:
SELECT dept_no, AVG (budget) FROM project
GROUP BY dept_no
HAVING AVG(budget) > (SELECT AVG(budget) FROM project)
В этом запросе в качестве условия отбора групп выступает логическое выражение, сравнивающее значение, возвращаемое для группы агрегатной функцией AVG, с результатом подзапроса, определяющего среднее значение бюджета проектов организации:
AVG(budget) > (SELECT AVG(budget) FROM project)
Окончательный результат запроса показан на рисунке 34.
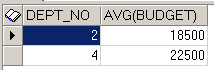
Рис. 34. Окончательный результат запроса для примера 17
Для сортировки результатов запроса по возрастанию или убыванию используется конструкция из ключевых слов ORDER BY. Без указания этого ключевого слова строки извлекаются в произвольном порядке.
Сортировка задается использованием следующей синтаксической конструкции:
ORDER BY выражение1 | положение1 | колонка1 [ ASC | DESC ], [ выражение2 | положение2 | колонка2 [ ASC | DESC ] ] [,...]
В этой синтаксической конструкции символ “|” ставится между элементами конструкции для того, чтобы показать, что использоваться может только один из этих элементов.
Параметр выражение представляет собой выражение, базирующееся на одной или нескольких колонках таблиц, перечисленных после ключевого слова FROM, а также колонках, указанных после ключевого слова SELECT.
Строки с одинаковыми значениями по выражению1 упорядочиваются по выражению2, если оно определено, и так далее.
Параметр положение задает число, идентифицирующее позицию колонки в перечислении после ключевого слова SELECT, то есть вместо указания имени колонки можно указать номер позиции этой колонки в списке SELECT.
Естественно, что предусмотрено и указание колонки, по значениям которой необходимо выполнить сортировку.
Ключевые слова ASC или DESC определяют возрастающий или убывающий порядок сортировки соответственно. Если эти ключевые слова не указаны, то по умолчанию используется сортировка по возрастанию (ASC).
Особое внимание следует уделить неопределенным (NULL) значениям колонок. Значение NULL рассматривается как “самое тяжелое” и размещается в конце списка при сортировке в порядке возрастания (ASC) и в начале списка при сортировке в порядке убывания (DESC).
Рассмотрим использование сортировки на примерах.
Пример 18. Выбрать информацию о номере, названии и бюджете проектов. Информацию представить в порядке убывания бюджета.
Запрос для получения данной информации будет иметь следующий вид:
SELECT proj_no, proj_name, budget FROM project
Дата добавления: 2015-08-17; просмотров: 57 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Операции выборки строк | | | ORDER BY budget DESC |