|
Читайте также: |
Ниже рассмотрены основные классические архитектуры параллельных систем, реализованные в серийных образцах [1].
АРХИТЕКТУРЫ С РАЗДЕЛЯЕМОЙ ОБЩЕЙ ПАМЯТЬЮ
Один из наиболее важных классов параллельных машин – shared memory multiprocessors – многопроцессорные системы с разделяемой общей областью памяти. Ключевой характеристикой данных систем является то, что взаимодействие процессоров осуществляется как обычное выполнение инструкций доступа к памяти (т.е. loads and stores). Данный класс систем имеет большую историю развития, начало которой датируется 1960 годом (система BINAC).
Основа программной модели (Shared address) для таких архитектур, по существу, есть разделение времени доступа к общей области памяти (time – sharing). В процессах часть их адресного пространства является разделяемой с другими процессами. Каждый процесс имеет виртуальную область памяти, состоящую из адресного пространства разделяемой памяти и собственного адресного пространства. На рис. 1.1 представлена типовая модель взаимодействия процессоров через механизм разделяемой общей памяти. На рисунке показана связь виртуального адресного пространства процессов (P0 – Pn)  , состоящего из разделяемой и собственной областей, с физической областью памяти.
, состоящего из разделяемой и собственной областей, с физической областью памяти.

Операции записи и чтения в разделяемую область памяти требует дополнительного контроля. Т.е. операционная среда выполняет специальные функции синхронизации процессов (операций записи и чтения в разделяемую область памяти). Например, должна быть блокирована операция чтения данных одного процесса до тех пор, пока в данную ячейку не будет записан результат процесса – предшественника.
Коммуникационное оборудование систем с общей памятью позволяет расширять системную память естественным образом. По - существу, большинство компьютерных систем позволяют процессору и ряду контроллеров ввода – вывода обеспечивать доступ к набору модулей памяти через некоторую коммуникационную среду, как показано на рис 1.2.
Большинство вычислительных систем содержат один или более модулей памяти (П), доступной процессору и контроллеры ввода-вывода через аппаратную коммуникационную среду.

Наращивание мощности системы достигается простым добавлением процессоров, модулей памяти и числа контроллеров ввода-вывода (которые также являются разделяемыми), в зависимости от требований к системе. На рис. 1.2. дополнительный процессор выделен тонировкой. При этом реальный рост производительность всей системы существенно зависит от специфики системной организации конкретного компьютера, т.к. рост числа процессоров и процессов приводит, постепенно, к несбалансированности между частотой обращений к разделяемой памяти и выполнением собственно программ. Это определяется тем, что не удается на практике реализовать идеальную - Parallel Random Access Machine (PRAM), когда любой процессор может осуществить доступ к любой ячейки памяти в любой момент времени. Для реализации данного принципа, обычно, используют иерархическую организацию разделяемой памяти, т.е. уменьшают количество обращений за счет, например, использования cache – памяти (С).
Можно выделить несколько основных типов коммуникационных сред, используемых в архитектурах разделяемой общей памяти (рис 1.3).
Для удовлетворения требований по загрузке системы она может иметь несколько каналов ввода-вывода, которые обеспечивают прямой доступ к каждому модулю памяти. Такого типа системы имеют организацию перекрестного соединения - switch connecting – процессоров (Пр), нескольких каналов ввода-вывода (I/O) и нескольких модулей памяти (П), показанной на рис 1.3а. Размерность рассматриваемой структуры определяется числом входов-выходов аппаратного коммутатора (swith). В ранних системах размер и стоимость рассматриваемой коммуникационной среды ограничивалась малым числом процессоров. В дальнейшем рост числа процессорных элементов определялся ростом удельного веса аппаратной части, с одновременным снижением ее стоимости. Цена размеров перекрестного соединения становится лимитирующим фактором и, в большинстве случаев, это приводит к появлению многоуровневой иерархической структуры коммуникационной среды - multistage interconnection network - показанной на рис 1.3б. В этом случае цена растет медленнее, чем число портов. Понятно, что экономия приводит к увеличению времени ожидания соединения (latency) и уменьшения полосы пропускания на порт. Способность доступа ко всей памяти прямо из каждого процессора имеет несколько преимуществ: любой процессор может запустить любые процессы или обратиться к любому событию ввода-вывода, а структуры данных могут быть разделены внутри операционной системы.
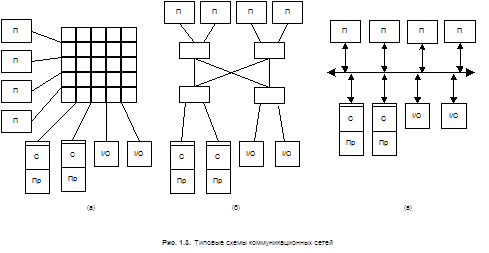
Широкое применение систем с разделяемой общей памятью связано с появлением 32-bit микропроцессоров в середине 1980 г., cache-память, плавающая запятая, и управление блоком памяти было реализовано на одной - двух платах (Bell 1985). Большинство машин среднего уровня, включающих миникомпьютеры, серверы, рабочие станции и персональные компьютеры имеют шинную организацию – bus interconnect - как показано на рис 1.3в. и эта шина может быть адаптирована для поддержки многопроцессорных систем. Стандартный механизм доступа к шине позволяет любому процессору достичь любого физического адреса в системе. Как и в случае перекрестного соединения (рис. 1.3а), вся память равноудалена от процессоров, поэтому все процессоры имеют одинаковое время доступа (latency) к памяти.
Такая конфигурация обычно называется symmetric multiprocessor (SMP). SMP идеально подходит как для параллельных программ, так и для малтипрограммирования [2]. Типичным примером организации многопроцессорной системы с симметричным доступом к памяти, основанной на шинной архитектуре, является компьютер Intel Pentium Pro four-processor “quad pack”, иллюстрирующий первый SMP для широкого рынка (рис. 1.4).

Материнская плата Intel quad-processor Pentium Pro использовалась во многих многопроцессорных серверах, таких как HP NetServer LX series, являясь главным элементом дизайна для систем с малым числом процессоров - small-scale design. Как показано на рис. 1.4, на ней можно было объединить до четырех процессорных модулей (Пр-модуль), содержащих Pentium Pro (166 MHz) процессор (CPU), cache-память, контролллер прерываний, интерфейс шины. Такой модуль был реализован на одном кристалле, имеющем разъемы для прямого включения в 64-bit шину памяти. 66 MHz шина имела пиковую пропускную способность 528 Mb/s. Двухкристальный контроллер памяти и четырехкристальный контроллер мультиплексного канала - memory interleave unit (MIU) - обеспечивали взаимодействие шины с модулями памяти (DRAM). Шина памяти через PCI мосты сопрягалась с двумя независимыми шинами стандарта PCI, которые обеспечивали связь с монитором, сетью и устройствами ввода-вывода (I/O). Структура Pentium Pro “quad pack” была похожа на большинство ранних машин класса SMP, но ее реализация отличалась наибольшей степенью интеграции.
На рис. 1.5 показана структура сервера Sun Enterprise Server, который так же поддерживает симметричный доступ к памяти (SMP), не смотря на то, что она физически распределена между процессорными платами.

В отличии от Pentium Pro “quad pack”, многопроцессорный сервер Sun UltraSparc-based Enterprise является представителем систем большей размерности по числу процессоров - larger-scalle design. Широкая (256-bit), высоко поплайнизированная шина памяти имеет пропускную способность 2,5 Gb/s. Сервер имеет иерархическую структуру, где каждая плата реализует структурную единицу системы, либо вычислительный модуль (Пр - модуль) из двух процессоров и памяти, либо модуль ввода-вывода. Наличие двух типов модулей является обязательным условием работоспособности системы. Вычислительный модуль содержит два процессора UltraSparc, каждый их которых имеет двухуровневую cache-память (первый уровень (C') – 16 KB, второй уровень (С”) – 512 KB), плюс два 512-bit-wide банка памяти и внутренний коммутатор. Модуль ввода-вывода поддерживает три SBUS слота для расширения функции ввода-вывода, SCSI разъем, 100bT Ethernet порт и два конектора для подключения оптических каналов - FiberChannell interfaces. Стандартная конфигурация сервера включает в себя 24 процессорных и 6 модулей ввода-вывода. Хотя банки памяти являются физически разнесенными попарно между процессорными модулями, вся память равноудалена от процессоров и доступна им через общую шину, что соответствует требованиям SMP. Данные могут быть размещены в любом месте без влияния на производительность системы.
Факторы ограничивающие число процессоров в системе различны для рассмотренного случая и для архитектуры с сетью из коммутаторов. (рис.1.3;а,б). Дополнение процессоров в коммутатор – дорого, однако общая производительность системы возрастает с числом портов. Цена добавления процессоров к шине – мала, но производительность всей системы остается фиксированной. В последнем случае ограничителем является пропускная способность шины. Если цена доступа к памяти станет слишком большой, процессоры будут тратить большую часть времени на режим ожидания и преимущество большого числа процессоров будет снивелирована.
Одним из естеcтвенных подходов построения масштабируемых машин с разделяемой общей памятью, поддерживающий симметричный доступ к памяти, показан на рис. 1.2. Он обеспечивает масштабируемость коммуникационной среды между процессорами и модулями памяти. Основной недостаток заключается в том, что при каждом обращении к памяти затрачивается много времени на ожидание кругового путешествия по сети, поэтому каждый процессор должен обеспечить высокую пропускную способность.
Альтернативный подход создания масштабируемой среды взаимодействия процессоров показан на рис 1.6.

Процессор и модули памяти интегрированы между собой таким образом, что доступ к локальной памяти осуществляется существенно быстрее, чем к удаленной. Такая организация взаимодействия процессоров носит название несимметричного доступа к памяти - nonuniform memory access (NUMA) - при котором контроллер локальной памяти определяет, выполнять ли доступ к локальной памяти или осуществлять транзакцию сообщения к удаленной памяти (при этом системы ввода-вывода могут быть либо частью каждого модуля, либо консолидироваться в специальный модуль I/O). В таком случае доступ к собственным данным процессора, часто может быть выполнен локально, как и доступ к разделяемым данным, если они сохранены в локальном модуле. Доступ к локальной памяти быстрый и не возрастает во времени, по сравнению с удаленным доступом. Среднее время доступа существенно уменьшается, если большую часть занимают обращения к локальной памяти. Требования к пропускной способности сети тоже уменьшаются.
Не смотря на некую привлекательность концептуальной простоты SMP архитектуры, подход NUMA стал куда более приемлемым для больших многопроцессорных систем, благодаря его неотъемлемым преимуществам, приводящим к росту производительности таких систем.
Примером такого стиля проектирования является CRAY T3E, показанный на рис. 1.7.

CRAY T3E может содержать до тысяч процессоров, работающих с глобальным общим адресным пространством. Каждый модуль - node - содержит DEC Alpha процессор (Пр), локальную память (П), интегрированный с контроллером памяти сетевой интерфейс и сетевой коммутатор. Компьютер организован как трехмерный куб, в котором каждый модуль соединяется с его соседями через 650 Mb/s линки (стандарт point-to-point). Любой процессор может иметь доступ к любой памяти, однако идеология NUMA реализована в коммуникационной архитектуре, как наилучшая для характеристик производительности системы. Контроллер памяти модуля захватывает доступ к удаленной памяти и руководит транзакцией сообщения в контроллере памяти удаленного модуля от имени локального процессора. Транзакция сообщения автоматически маршрутизируется через промежуточные модули (вершины) до места назначения, с малыми задержками на каждом переходе. Данные удаленной памяти не кэшируются, поскольку нет аппаратного механизма их сохранения. Система ввода-вывода CRAY T3E распределена между совокупности вершин, располагающихся на поверхности куба, которые соединяются с внешним миром через дополнительную сеть.
В этой машине реализована структура, при которой хоть вся память и доступна любому процессору, распределение данных между процессорами отдано программисту. Caches – память (С) используется только для хранения данных (инструкций) из локальной памяти. Т.о. задача программиста – избежать частых обращений к удаленной памяти.
В заключение, надо отметить, что операции взаимодействия и синхронизации в моделях программирования с разделяемой общей адресной областью [2], специфицируются операциями READS и WRITES разделяемых переменных. Эти операции прямо отображаются в коммуникационные абстракции, содержащие LOAD и STORE (инструкции доступа к глобальной разделяемой общей памяти), которые прямо поддержаны аппаратно через доступ к разделяемым зонам физической памяти. Программная модель и коммуникационные абстракции имеют прямую аппаратную реализацию. Для каждого процесса обращение к памяти, есть адрес в его виртуальном адресном пространстве. Адрес транслируется в процесс идентификации физической области, которая может быть локальной или удаленной, по отношению к процессору и которая может быть доступна другим процессорам. Трансляция адреса реализуется защищенно, в пределах разделяемого адресного пространства, как это делается в однопроцессорных системах.
Эффективность систем с разделяемой общей памятью зависит от времени ожидания доступа к памяти, связанного с пропускной способностью среды передачи данных. Для чтобы достичь маштабируемости таких систем, все решения, включая все механизмы связи, используемые для доступа к разделяемой памяти, должны быть правильно сбалансированы.
1.2. АРХИТЕКТУРЫ С РАСПРЕДЕЛЕННОЙ ОБЛАСТЬЮ ПАМЯТИ
Ко второму важному классу параллельных машин относятся многопроцессорные системы с распределенной областью памяти - message-passing architectures (MPA). MPA используют законченные компьютеры, включающие микропроцессор, память и подсистему ввода-вывода, как узлы для построения системы, объединенные коммуникационной средой, обеспечивающую взаимодействие процессоров посредством простых операций ввода-вывода. Структура высокого уровня для MPA практически такая же, как и для NUMA машин, т.е. машин с разделяемой памятью, показанных на рис. 1.6. Первое отличие состоит в том, что коммуникации интегрированы в уровень ввода-вывода, а не в систему доступа к памяти. Этот стиль дизайна имеет много общего с сетями из рабочих станций или кластерными системами, за исключением того, что в МРА пакетирование узлов обычно более плотное, нет монитора и клавиатуры на каждом узле, а производительность сети намного выше стандартной. Интеграция между процессором и сетью имеет склонность быть более тесной чем традиционные структуры ввода-вывода, которые поддерживают соединения с оборудованием, которое более медленное, чем процессор. Начиная с посылки сообщения MPA есть фундаментальное взаимодействие ПРОЦЕССОР – ПРОЦЕССОР.
Системы с распределенной памятью имеют существенную дистанцию между программной моделью и действительными аппаратными примитивами. Коммуникации осуществляются через средства операционной системы или библиотеку вызовов, которые выполняют много акций более низкого уровня, включающих операции коммуникации.
Наиболее общие операции взаимодействия на пользовательском уровне (user-level) в MPA есть варианты посылки (SEND) и получения (RECEIVE) сообщения. Совместный механизм SEND и RECEIVE, вызванный передачей данных из одного процесса в другой, показан на рис 1.8.

Передача данных из одного локального адресного пространства к другому произойдет, если посылка сообщения со стороны процесса - отправителя будет востребована процессом - получателем сообщения.
С этой целью в большинстве системах с распределенной памятью сообщение специфицируется операцией SEND, которая добавляет к сообщению специальный признак (tag), а операция RECEIVE в этом случае выполняет проверку сравнения данного признака.
Сочетание посылки и согласованного приема сообщения (на основе совпадения признаков) выполняет логическую связку – синхронизацию события, т.е. копирования из памяти в память. Имеется несколько возможных вариантов синхронизаии этих событий, в зависимости от того, завершиться ли SEND к моменту, когда RECEIV будет выполнен или нет (т.е. будет ли снова доступен буфер посылки для использования до момента получения подтверждения приема). Похожим образом RECEIV может, в принципе, подождать до момента согласованной посылки (SEND) или использовать "почтовый ящик" для получения сообщения. Каждый из этих вариантов имеет несколько различную интерпретацию и различные требования к реализации.
Механизм посылки сообщений долго использовался как средство коммуникации и синхронизации совокупности арбитрирующих взаимодействующих последовательных процессов, даже на одном процессоре. В качестве примеров можно привести языки программирования типа CSP и Occam, наиболее общие функции операционных систем, типа SOCKETS.
Первые машины с распределенной областью памяти обеспечивали аппаратную поддержку примитивов (команд), которые очень напоминали простую абстракцию взаимодействия SEND/RECEIV на пользовательском уровне, с некоторыми дополнительными ограничениями. Каждый узел системы соединялся с определенным (фиксированным) числом соседей по регулярной схеме (образцу) на основе связи точка-точка (poin-to-point), поведение которой, в свою очередь, описывалось простым FIFO. Такой тип конструкции для минимального 3D куба показан на рис. 1.9, где каждый узел имеет связи с соседями по трем направлениям через буфер FIFO.

В ранних системах, обычно, использовалась структура гиперкуба (на 2n узлов), в которой каждый узел соединялся с n другими узлами, бинарные адреса которых отличались на один бит. Другие машины имели решетчатую структуру, где узлы соединялись с соседями по двум или трем измерениям. Такая технология для более ранних машин была важна, потому что только соседние процессоры могли быть использованы в качестве адресата в операциях приема-посылки. Процесс - отправитель посылал сообщение, а процесс – получатель получал сообщение через канал - link. FIFO было маленьким, так что отправитель не успевал закончить формирование сообщения до момента, когда получатель начинал его читать, поэтому посылка блокировалась до момента начала приема (на современном языке это называется синхронной передачей сообщений, т.к. два события совпадают по времени). Детали передачи данных были скрыты от программиста в специальной, библиотеке, формирующей слой программного обеспечения между запросами на прием и передачу и реальным аппаратным обеспечением.
Прямое FIFO проектирование вскоре было заменено на более универсальное, при котором передача сообщений обеспечивалась механизмом прямого доступа к памяти direct memory access (DMA) на каждой стороне взаимодействующих процессов. DMA устройства представляют собой специализированный контроллер, который перемещает данные между памятью и устройством ввода-выводда без участия процессора до момента окончания передачи. Использование DMA позволяет осуществить неблокируемые посылки, при которых отправитель в состоянии инициировать посылку и одновременно продолжать полезные вычисления (или даже выполнять прием). На приемном конце сообщение принимается через устройство DMA, пересылается в буферный слой сообщений и ставится в режим ожидания до тех пор, пока заданный процесс выполнит соответствующий прием, после чего (в этот момент) данные копируются в адресное пространство процесса – получателя.
Физическая организация коммуникационной сети настолько влияла на программные модели этих ранних машин, что параллельные алгоритмы очень часто именовались в соответствии со спецификой внутренней топологии соединений, например, кольцо (Ring), матрица (grid), гиперкуб (hypercube). Однако для придания большей универсальности, системы стали обеспечивать поддержку взаимодействия между независимыми процессорами, а не только между соседними. Первоначально это поддерживалось перенаправлением данных внутри уровня сообщений вдоль каналов (links) в сети. Вскоре эта распределяющая функция была перенесена на уровень аппаратного обеспечения. Каждый узел стал содержать процессор с памятью и коммутатор, который мог перенаправлять сообщения. Тем не менее, в таком подходе, известным под названием store-and-forward, время передачи сообщения пропорционально числу необходимых этапов передачи в сети, поэтому, все-таки, влияние топологии внутренних соединений оставалось существенным.
Такое внимание к сетевой топологии было значительно ослаблено, в связи с появлением гораздо более универсальных сетей, которые поплайнизировали передачу сообщения через каждый коммутатор, формирующий внутреннюю сеть. В наиболее современных машинах с распределенной памятью нарастающая задержка, вносимая каждым этапом передачи (скачком) достаточно мала. Это существенно упрощает программную модель [2]. Обычно процессор рассматривается как простой формирователь линейной последовательности с одинаковыми затратами на коммуникацию. Другими словами, коммуникационная абстракция отражает главным образом организационную структуру, показанную на рис 1.6. Один из важных примеров такой машины является IBM SP-2, изображенной на рис 1.10.

Это масштабируемый параллельный компьютер, состоящий из узлов на базе рабочих станций RS6000, масштабируемой сети и сетевым интерфейсом (NI)– network interface card (NIC), содержащим специализированный процессор (i860). NIC соединен с MicroChannel I/O bus и содержит драйверы сетевого линка, память (DRAM) для буферирования сообщений. Для реализации DMA, модуль содержит процессор i860, управляющий перемещением данных между памятью и сетью. Сеть представляет собой каскадное 8x8 коммутируемое перекрестное соединение (crossbar switches) (см. рис. 1.3а). Скорость передачи сообщений по линкам составляет 40 Mb/s в каждом направлении.
Другим примером является параллельный компьютер Intel Paragon, показанный на рис 1.11.
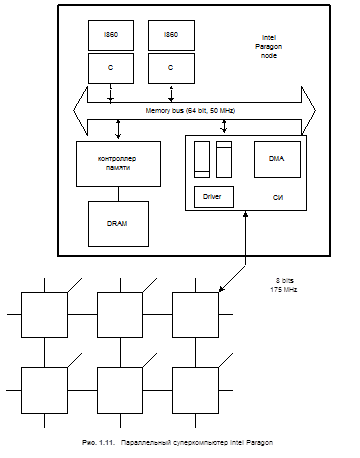
Intel Paragon иллюстрирует наиболее плотное аппаратное пакетирование в узлах. Каждая плата (узел) представляет собой SMP с двумя или более процессорами (i860) и кристалл сетевого интерфейса (NI) связанный с шиной памяти (Memory bus). Один из процессов специализируется на обслуживании сети. Узел имеет механизм DMA для передачи блоков данных через сеть высокого уровня. Сеть представляет собой 3D куб, аналогичный структуре сети компьютера CRAY T3E. Линки имеют пропускную способностью 175 Mb/s в каждом направлении.
В заключении, МРA и разделяемое адресное пространство являются двумя очевидно различными программными моделями, каждая из которых обеспечивает ясную парадигму для разделения коммуникации и синхронизации. Тем не менее лежащие в основе данных машин базовые структуры постепенно объединяются в рамках общей организации, представляемой набором законченных компьютеров усиленных специальным контроллером, соединяющим каждый узел с расширяемой коммуникационной сетью. Подробнее обобщенная архитектура параллельных систем будет рассмотрена ниже, в разделе 1.6.
1.3. МАТРИЧНЫЕ СИСТЕМЫ
Третий важный класс параллельных машин – матричные системы - относятся к классу single-instruction-multiple-data machines (SIMD) или data parallel architectures. Ключевой характеристикой этой модели программирования data parallel programming model [2] является то, что операция может быть выполнена параллельно на каждом элементе большой регулярной структуры данных, таких как массивы и матрицы.
Компьютерная таксономия, известная как Flynn’s taxonomy (Flynn 1972), появившаяся в изданиях начала 70–х годов, определяет структуру системы в терминах числа одновременно выполняемых различных инструкций и числа обрабатываемых элементов данных. В этом случае обычные последовательные компьютеры определяются как системы с одиночным потоком команд и одиночным потоком данных single-instruction-single-date (SISD), а параллельные машины, построенные из множества обычных процессоров как системы с множественным потоком команд и множественным потоком данных multiple-instruction-multiple-data (MIMD). Альтернативой им стали системы класса одиночного потока команд и множественного потока данных single-instruction-multiple-data (SIMD). Исторически, такой подход появился в середине 60‑х. Идея была в том, что вся последовательность инструкций могла бы быть консолидирована в управляющем процессоре. Процессор данных включал бы только ALU, память и обеспечивал простое взаимодействие с ближайшими соседями.
В SIMD машинах модель программирования (data parallel programming model) была напрямую реализована в физическом аппаратном уровне. Обычно управляющий процессор (Пр) осуществлял рассылку каждой инструкции по массиву процессорных элементов (data processing element) (ПрЕ), которые были соединены между собой в форме регулярной решетки, как показано на рис 1.12

Матричные системы ориентированы на большой класс вычислительных задач, которые требуют выполнения матричных операций или обработки массивов, т.е. когда выполняются одинаковые операции на уровне каждого элемента массива или матрицы, вовлекающие в процесс вычисления соседние элементы. Т.о. управляющий процессор инструктирует процессоры данных по выполнению каждой операции над локальным элементом данных или все выполняют операцию коммуникации-обмена данных (все сразу).
В дальнейшем, в середине 1970-х, векторные процессоры затмили собой развитие других многопроцессорных систем. Векторные процессоры интегрировали скалярный процессор с коллекцией функциональных единиц, которые оперировали с векторными данными на памяти с поплайновой организацией. Способность оперировать над векторами в любом месте памяти ликвидировало необходимость размещения используемых структур данных в жесткую структуру внутренних связей и значительно упростило проблему получения объединенных данных.
Набор команд первого векторного процессора CDC Star-100 включал в себя векторные операции, которые позволяли комбинировать два источника векторов из памяти и создавать в памяти вектор результата. Машина работала на полной скорости тогда, когда векторы были соседними и, следовательно, основное время тратилось на простое транспонирование матриц. Сенсационное изменение произошло в 1976 году, когда был представлен CREY-1, в котором концепция LOAD-STORE архитектуры была расширенна на обработку векторов и реализована в процессорах CDC 6600 и CDC 7600 (и продолжена в современных RISC машинах). Векторы в памяти, с любым фиксированным шагом по индексу, были перенесены в или из соседних (близких) регистров посредством загрузки вектора и хранения инструкций. Арифметика выполнялась на векторных регистрах. Использование очень быстрых скалярных процессоров (80 MHz), интегрированных с векторными операциями и использующих большую полупроводниковую память, привело к мировому господству суперкомпьютеров рассматриваемого класса. Более чем 20 последующих лет, CRAY Research лидировал на суперкомпьютерном рынке, увеличивая пропускную способность передачи векторов в памяти, число процессоров, число векторных поплайнов и длину векторных регистров.
Второй раз SIMD компьютеры (data parallel machine) пережили эпоху своего возрождения в середине 1980, когда развитие VLSI-design привело к появлению доступного 32 разрядного микропроцессора (это были, так называемые, одноразрядные секционные микропроцессоры или микропроцессоры с разрядно - модульной организацией). В уникальной петлевой архитектуре в data parallel режиме было размещено 32 простых одноразрядных элементарных процессоров на одном чипе, вместе с серией соединений с соседними процессорами. Совокупность последовательных инструкций была размещена на управляющем процессоре. Главное было в том, что такие системы с несколькими серийными процессорными элементами были созданы и имели разумную цену.
В дальнейшем технологические факторы, которые сделали это bit-serial проектирование привлекательным и обеспечили быстрое, недорогое проектирование на базе однокристальных процессоров с плавающей точкой, проложили путь очень быстрым микропроцессорам с интегрированными плавающими запятыми и кэш-памятью. Это устранило ценовые преимущества консолидированной последовательной логики, описанной выше, и обеспечило равенство пиковой производительности на более малом числе полных процессоров.
Таким образом, пока существует пользовательский уровень абстракции параллельных операций на больших регулярных структурах данных, продолжается и предложение интересных решений для рассматриваемого важного класса проблем. Машинная организация, поддерживая модели data parallel programming models, развивается по направлению к более общим параллельным архитектурам множественной кооперации микропроцессоров, более масштабируемой разделяемой памяти и MPA машинам, несмотря на то, что существуют решения в области создания специализированных компьютерных сетей, поддерживающие глобальную синхронизацию процессоров. В последнем случае сетевая поддержка выступает в роли барьера, который в особых точках программы переводит каждый процесс в режим ожидания до тех пор, пока остальные процессы, не достигнут заданной точки синхронизации. В действительности SIMD подход эволюционировал в SPMD (single-programm-multiple-data) подход, в котором все процессоры выполняют копии одних и тех же программ и имеют, таким образом, в большей мере схожесть с более структурированными формами разделяемой памяти и МР программирования.
В середине 1980-х возрождение SIMD data parallel machine привело к появлению других архитектурных направлений, которые были исследованы в академических институтах и промышленности, но имели меньший коммерческий успех и поэтому не получили широкого распространения, по сравнению с рассмотренными выше. Два подхода, которые развились до законченных программных систем – dataflow architectures и systolic architectures.
1.4. МАШИНЫ, УПРАВЛЯЕМЫЕ ПОТОКОМ ДАННЫХ
Машины, управляемые потоком данных относятся к классу datafllow architecture. Реализация datafllow - модели вычислений может привести к наивысшей степени параллелизма, т.к. в ней используется альтернативный принцип управления – управление потоком данных, который не накладывает дополнительных ограничений, присущих рассмотренному выше командному принципу управления.
В вычислительных системах, управляемых потоками данных, машинах потоков данных, отсутствует понятие программы как последовательности команд, а следовательно, отсутствует понятие состояния процесса. Каждая инструкция передается на исполнение, как только создаются условия для ее реализации. При наличии достаточных аппаратных средств одновременно может обрабатываться произвольное число готовых к исполнению инструкций. В datafllow – модели параллелизм не задается явно и аппаратные средства обработки должны его выделять на этапе исполнения. Однако, следует отметить, что реализация принципа управления потоком данных вызывает ряд трудностей, часть из которых носит принципиальный характер. К их числу необходимо отнести громоздкость программы, трудность обработки итерационных циклов, трудность работы сос структурами данных.
Суть идеи datafllow - модели в том, что программа представляется графом потока данных, пример которого показан на рис. 1.13
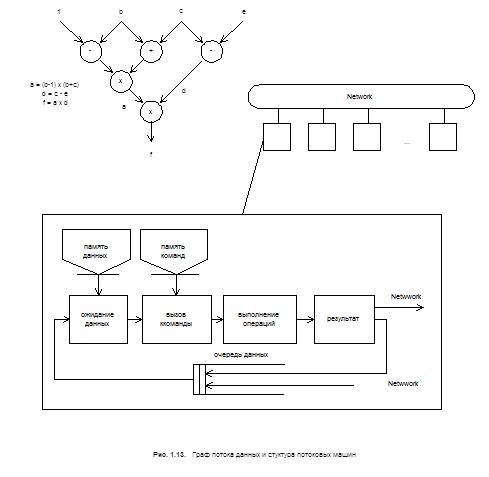
Инструкциям на графе соответствуют вершины, а дуги, обозначенные стрелками, указывают на отношения предшествования. Точка вершины, в которую входит дуга, называется входным портом (или входом), а точка, из которой она выходит, выходным. По дугам передаются метки, называемые токенами данных (token). Срабатывание вершины означает выполнение инструкции. При этом срабатывание происходит в произвольный момент времени при выполнении условий, соответствующих правилу запуска. Обычно используется строгое правило запуска, согласно которому срабатывание вершины происходит при наличии хотя бы по одному токену во всех ее входных портах. Срабатывание вершины сопровождается удалением одного токена из каждого входного порта и размещением не более одного токена результата операции в выходные порты. В зависимости от конкретной архитектуры системы порты могут хранить один или несколько токенов, причем они могут использоваться по правилу FIFO или в произвольном порядке.
Граф может быть распространен на произвольную совокупность процессоров. В предельном случае процессор в машине, управляемой потоком данных, может выполнять операции как отдельный круговой поплайн, как показано на рис 1.13.
Токен или сообщение из сети содержит данные и адрес или тэг (tag) его места назначения (вершины графа). Тэг сравнивается с хранимыми тэгами на совпадение. Если совпадение не произошло, то токен помещается в память для ожидания партнера. Если партнер найден, то токен с совпавшим тэгом удаляется из памяти, и данные поступают на выполнение соответствующей инструкции. Когда результат вычислен, новое сообщение или токен, содержащий данные результата посылаются каждому по назначению, специфицированному в инструкции. Тот же самый механизм может быть использован и для удаленного процессора.
Все архитектуры машин, управляемых потоком данных, с точки зрения механизмов организации повторной входимости, принято делить на статические и динамические. Т.е. в них используется либо статический граф потока данных, где каждая вершина представлена примитивной операцией, либо динамический граф, в котором вершина может быть представлена вызовом произвольной функции, которая сама может быть представлена графом. В динамических или (tagged-token) архитектурах эффект динамически развивающегося графа на вызываемую функцию обычно достигается появлением дополнительного информационного контекста в тэге.
Было создано несколько машин, управляемых потоком данных, как со статической, так и с динамической архитектурами. Наиболее известными являются мультипроцессор Дениса (Массачусетский технологический институт), система DDP (фирма Texas Instruments) и LAU (исследовательский центр CERT), достаточно подробно описанные в литературе.
1.5. СИСТОЛИЧЕСКИЕ СИСТЕМЫ
Разработчики систолических архитектур ставили перед собой задачу получить систему, которая совмещала бы достоинства конвейерной и матричных обработок. Первоначально систолические архитектуры разрабатывались для узкоспециализированных вычислительных систем. Однако в дальнейшем были найдены соответствующие алгоритмы для достаточно широкого класса задач, позволяющие реализовать принципы систолической обработки.
Основной принцип систолической обработки заключается в том, чтобы выполнить все стадии обработки каждого элемента данных, извлеченного из памяти, прежде чем вновь поместить в память результат этой обработки. Этот принцип реализуется систолической матрицей процессорных элементов, в которой отдельные процессорные элементы объединены между собой прямыми и регулярными связями, образующими конвейер. Таким образом может формироваться несколько потоков операндов, каждый из которых образован исходными операндами (элементами структуры данных, хранящейся в памяти), промежуточными результатами, полученными при выполнении элементарных операций в каждом процессорном элементе, и элементами результирующей структуры. Потоки данных синхронизированы единой для всех процессорных элементов системой тактовых сигналов. Во время тактового интервала все элементы выполняют короткую неизменную последовательность команд (или одну команду).

Рис 1.14 иллюстрирует систолическую систему для вычисления «свертки функции», использующую простую линейную область. Во время тактового интервала входные данные продвигаются вправо, умножаются на локальный вес и аккумулируются на выходе в порядке следования.
Систолические архитектуры обладают следующими достоинствами:
- минимизируются обращения к памяти, сто позволяет согласовать скорость работы памяти со скоростью обработки,
- упрощается решение проблем ввода – вывода вследствие уменьшения конфликтов при обращении к памяти,
- эффективно используются технологические возможности СБИС за счет регулярности структуры систолической матрицы.
Однако для реализации этих преимуществ необходимо найти для каждой задачи соответствующие систолические алгоритмы, которые могут быть реализованы на систолической структуре системы. Такие алгоритмы существуют сегодня для широкого круга задач, среди которых задачи числовой обработки, обработки сигналов и символов; умножение и обращение матриц, решение линейных систем, дискретное преобразование Фурье, кодирование и декодирование числовых последовательностей и т.д. Большинство этих алгоритмов сводится к рекуррентным соотношениям того или иного вида. В зависимости от вида систолического алгоритма, т.е. числа операндов, участвующих в примитивных операциях, типа этих элементарных операций м последовательности их выполнения выбирается тип процессорного элемента и структура локальных регулярных связей между ними. К типовым конфигурациям систолических матриц относятся: линейная (рис. 1.14), для реализации алгоритмов фильтрации при обработке сигналов, сравнения цепочек литер при обработке баз данных; прямоугольная, перемножения матриц, нахождения двухмерных ДПФ; и гексагональная, для выполнения операций обращения матриц, решения линейных систем уравнений и т.д.
Однако не все алгоритмы могут быть сведены к систолическим, и во многих случаях приходится отказываться от алгоритмов с меньшей сложностью в пользу более сложных, но регулярных алгоритмов, но отвечающим требованиям систолической обработки.
1.6. ОБОБЩЕННАЯ АРХИТЕКТУРА ПАРАЛЛЕЛЬНЫХ СИСТЕМ
Экзаменуя эволюцию основных подходов к параллельным архитектурам, можно заметить взаимопроникновение архитектур рассмотренных вычислительных систем и наличие общей типовой параллельной машинной организации, показанной на рис 1.15. Типовая параллельная вычислительная система включает в себя множество законченных компьютеров, содержащих один или несколько процессоров (Пр) с кэш-буфепами (С) и память (П), соединенных между собой через масштабируемую коммуникационную сеть. Управлять генерацией выходных сообщений или приемом входных сообщений помогает вспомогательный процессорный блок communication assist (CA) – контроллер.
С одной стороны объединение всех подходов к построению параллельных систем в рамках одной общей структуры может показаться существенным ограничением в области дизайна. С другой стороны все многообразие описанных выше подходов реализуется в communication assist (CA) – контроллере. Все дело в функциональности, которая должна быть им обеспечена, т.е. каков должен быть интерфейс между процессором, системой памяти и сетью.
Не удивительно, что различные программные модели определяют собственные, отличные от других требования к дизайну CA и определяют какие системные операции являются общими и должны быть оптимизированы. В случае разделяемой памяти CA крепко интегрируется с системой памяти (П) для того чтобы управлять событиями в памяти, которые могут потребовать взаимодействия с другими узлами системы (nodes). CA должен также управлять приемом сообщений, доступом к памяти и устанавливать транзит по направлению к другому узлу системы. В случае MPA, коммуникация инициализируется четкой акцией системного или пользовательского уровня, т.е. не требуется «наблюдаемости» системных событий в памяти. Вместо этого необходимо наличие возможности быстрой посылки сообщения и формирования ответа на входящее сообщение. Можно потребовать, чтобы под ответом подразумевалось выполнение операции сравнения тэгов (tag) на совпадение, чтобы буфера были локализованы, чтобы передача данных комментировалась. Параллельные данные и систолические подходы делают акцент на быстрой глобальной синхронизации, которая может быть прямо поддержана сетевыми механизмами или CA. Datafllow архитектура делает акцент на быстром, динамическом распределении вычислений, основанном на входных сообщениях. Систолические алгоритмы предоставляют возможность использовать общие алгоритмические модели в специальных задачах синхронизации параллельного взаимодействия. Даже при этих различиях, важно заметить, что все из рассмотренных подходов имеют много общего, т.е. они требуют инициировать сетевую транзакцию как результат специфичных процессорных событий, и они требуют реализации прямых операций на удаленном узле системы для выполнения необходимых программных действий.
Мы также видим, что произошло разделение между программной моделью и машинной организацией, как только среда параллельного программирования достигла своей зрелости.
Список литературы:
1. Parallel Computer Architecture: A Hardware/Software Approach/ David E. Culler, Jaswinder Pal Singh// Morgan Kaufmann Published, Inc. San Francisco, California, 1999, 1025 c.
2. Designing and Building Parallel Programs: Concepts and Tools for Parallel Software Engineering/ Ian T. Foster// Addison-Wesley Publishing Company, Inc. 1998, 381 c.
Дата добавления: 2015-07-20; просмотров: 122 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Законы Ома и Кирхгофа в комплексной форме. Параллельное соединение R,L,C элементов | | | Профессор, а почему Русские вымерли? - Были слишком терпеливыми.... |