Читайте также:
|
Важнейшей характеристикой сообщения является количество информация в нем содержащейся. Например, сообщение "Утром взошло солнце" содержит совсем мало информации, тогда как сообщение "Ваш дом только что рухнул" содержит информации много больше. Количество информации в сообщении о событии зависит от вероятности события: чем менее оно вероятно, тем больше информации мы получаем.
Мы привыкли измерять информацию в битах и байтах. Посмотрим, как связаны биты с вероятностью. Классический опыт, постоянно применяемый в теории вероятности - серия из n бросаний монеты. Выпадение "решки" на монете обозначим буквой "Р", орла - "О". Предположим, что мы хотим передать сообщение о результате серии из четырех испытаний, например "ООРО". Вероятность выпадения такой серии равна 1/16, для передачи сообщения требуется 4 бита. Этот простой пример может служить оправданием для следующего определения:
Количество информации I = -log(P),
где P - вероятность события, сообщение о котором передается. Логарифм в формуле подразумевается двоичным. Знак минус обеспечивает положительность количества информации, так как вероятность меньше 1. Единицей измерения количества информации является бит.
Таким образом, если мы имеем источник, выдающий с равной вероятностью числа 0 и 1 (то есть P(0)=P(1)=1/2), то информация, приходящаяся на одну цифру равна -log(1/2) = 1 бит.
Рассмотрим несколько примеров, в каждом из которых будем предполагать, что вероятности всех символов одинаковы. В случае русского алфавита (33 буквы) количество информации, приходящейся на одну букву равно log(33)=5.044 битов, в случае латинского - log(26)=4.7, для десятичных цифр - 3.32 бита на символ.
Как уже говорилось выше, если источник выдает цифры 0 и 1 с одинаковой вероятностью 1/2, то количество информации, приходящейся на одну цифру равно -log(1/2)=1 биту. Предположим теперь, что цифры появляются с различной вероятностью, P(0)=p, P(1)=q=1-p. Тогда количество информации, содержащейся в одной цифре, так же будет различным. Если P(0)=0.99 и P(1)=0.01, то количество информации, соответствующей цифре "0" будет равно -log(0.99)=0.0145 битов, а цифре "1" - -log(0.01)=6.64 бита.
Пусть мы имеем достаточно длинное (длины n) сообщение в таком алфавите. В нем "0" появится в среднем p*n раз, а "1" - q*n=(1-p)*n раз. Учитывая количество информации, содержащейся в каждой цифре, мы можем сказать, что общее количество информации в сообщении длины n равно
- p*n*log(p) - q*n*log(q) = n*(- p*log(p) - q*log(q)),
а среднее количество информации, приходящееся на один символ равно
- p*log(p) - q*log(q).
Переходя к общему случаю, мы получим следующий результат.
Пусть алфавит состоит из N различных символов, которые появляются с вероятностями p(1),..., p(N) независимо друг от друга. Тогда среднее количество информации приходящееся на один символ равно
H = - p(1)*log(p(1)) -... - p(n)*log(p(N)).
Эта величина называется энтропией заданного потока символов (В 1948 г. Клод Шеннон в своих работах по теории связи выписывает формулы для вычисления количества информация и энтропии. Термин "энтропия" используется Шенноном по совету патриарха компьютерной эры фон Неймана, отметившего, что полученные Шенноном для теории связи формулы для ее расчета совпали с соответствующими формулами статистической физики, а также то, что "точно никто не знает" что же такое энтропия).
Для двухсимвольного алфавита, если вероятности появления символов одинаковы и равны 1/2, то энтропия потока равна 1 бит/символ. Если же P(0)=0.99, P(1)=0.01, то энтропия потока примерно равна 0.08 бит/символ. Напомню, что эти рассуждения применимы только в потоку независимых символов, когда вероятность появления очередного символа не зависит от предыдущих.
Еще одна величина, связанная с энтропией - избыточность. Избыточностью мы будем называть присутствие в сообщении большего количества символов, чем это необходимо. Например, в системе с двумя символами "О" и "Р", мы можем из записывать как "000"и "111" соответственно. Эти соображения подводят нас к следующему определению избыточности.
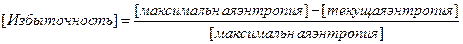
В приведенном выше примере избыточность равна (3-1)/3=0.67, так как 3 двоичные цифры могут нести 3 бита информации, а несут только 1. Все естественные языки имеют довольно большую избыточность, благодаря чему мы можем понимать сообщение, даже если часть букв в нем испорчена или отсутствует.
Все сказанное выше относится к случаю, когда все символы в сообщении появляются независимо друг от друга. В реальной жизни это почти всегда не так. Например в слове "информа_ия" пропущенной почти наверняка является весьма редкая буква "ц". Это означает, что вероятность появления буквы зависит от предшествующих (и последующих). В полном объеме учесть все эти зависимости весьма сложно. На практике достаточно хорошей моделью оказывается цепь Маркова. В своем простейшем виде, - цепь Маркова первого порядка, мы просто полагаем, что вероятность появления очередной буквы зависит лишь от предыдущей. Таким образом, чтобы задать Марковскую цепь первого порядка на множестве букв русского алфавита, нам требуется задать 32*32-матрицу P, в которой на (i,j)-м месте стоит p[i,j] - вероятность появления j-й буквы алфавита после i-й. Конечно, можно рассматривать и Марковскую цепь более высокого порядка, в которой вероятность появления очередной буквы зависит от нескольких предыдущих, - двух, трех и так далее. Но так как объем данных, требуемый для описания таких моделей быстро растет с ростом порядка цепи, то цепи Маркова с порядком больше трех практически не используются.
Для Марковской цепи первого порядка с матрицей p[i,j] количество информации в сообщении "буква номер j следует за буквой номер i" равна -log p[i,j].
Для нахождения среднего количества информации, приходящейся на один символ (энтропии), следует усреднить это выражение по всем парам (i,j):

Эта формула естественно обобщается и на уровень цепей Маркова высших порядков. Если для одного и того же потока рассматривать цепи все более высокого порядка, то энтропия будет снижаться. Например, для английского языка:
- если мы будем считать все буквы равновероятными и независимыми друг от друга, то энтропия будет равна log(26)=4.7 бит/символ.
- Если считать, что каждая буква имеет свою вероятность и буквы независимыми друг от друга (Марковская цепь нулевого порядка), то энтропия будет равна примерно 4.05 бит/символ.
- При рассмотрении английского текста как Марковской цепи второго порядка энтропия окажется равной 3.32 бит/символ.
- При рассмотрении цепи третьего порядка энтропия равна 3.10 бит/символ.
Для того, что бы оценить реальную избыточность языка применялся следующий метод. Испытуемым предъявлялся некоторый текст и предлагалось предсказать в нем следующую букву. На основании таких тестов были получены оценки реальной энтропии естественного (английского) языка. Оказалось, что она колеблется от 0.6 до 1.3 бита/символ в зависимости от текста. Следовательно, "идеальный" архиватор должен сжимать текстовые файлы до 8-16% от первоначальной длины. На практике максимальный достигнутый уровень сжатия для текстовых файлов (архиватор HA) равен 24-30%.
Дата добавления: 2015-07-10; просмотров: 72 | Нарушение авторских прав