Читайте также:
|
ИПС глобальной сети имеет отличия, обусловленные как характером сети, так и особенностями работы пользователей такой системы. Рассмотрим основные особенности использования ИПС в глобальной сети на примере сети Интернет.
Схематично ИПС для Интернета выглядит так, как показано на рис. 10.3:
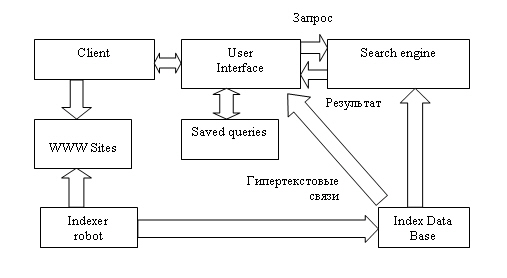
Рис. 10.3. ИПС для Интернета
Client (клиент) на этой схеме - это программа просмотра конкретного информационного ресурса. Такая программа обеспечивает просмотр документов WWW, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь, все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
User interface (пользовательский интерфейс) - способ общения пользователя с поисковым аппаратом: системой формирования запросов и просмотра результатов поиска.
Search engine (поисковая машина) - служит для трансляции запроса на информационнопоисковом языке, в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
Index database (индекс базы данных) - индекс, который является основным массивом данных ИПС и служит для поиска адреса информационного ресурса. Queries (запросы пользователя) - сохраняются в его (пользователя) личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно запоминать запросы, на которые система дает хорошие ответы.
Index robot (робот индексирования) - служит для просмотра данных в Интернете и поддержания базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
WWW sites - это весь Интернет, или, точнее, информационные ресурсы, просмотр которых обеспечивается программами просмотра.
Как мы видим, источником информации о состоянии информационных ресурсов сети является робот-индексировщик. Это программа, которая по определенному алгоритму "заходит" на различные страницы, "читает" их и индексирует.
Индекс поисковых систем Интернета обновляется с периодичностью около недели. Отсюда видно, что в индекс поисковой системы не могут попасть материалы, например, периодических изданий, так как выходят они заведомо чаще, чем обновляется индекс.
Еще одна проблема заключается в том, что не все документы хранятся в виде файлов HTML, с которыми роботу работать легче всего. Если информация хранится в другом формате, может сложиться ситуация, когда адрес страницы, выдаваемой пользователю, содержит параметры, которые робот не знает, и, следовательно, он не может эти данные проиндексировать
Объем информации, опубликованной в Интернете, приводит также к ограничению количества терминов, которыми индексируется документ. Современные ИПС в Интернете используют порядка 100 терминов для индексации документа. Выбор терминов, используемых для индексации, зависит от реализации данной системы. Чаще всего первым критерием является отношение частоты употребления термина в документе к частоте употребления этого термина во всех ранее проиндексированных документах. То есть наибольший вес присваивается тем терминам, которые наиболее часто встречаются в данном документе и наиболее редко - во всех остальных проиндексированных документах. Термины, которые используются в очень большом количестве документов, при индексировании не используются совсем.
Для определения терминов индексирования, используемых для создания поискового образа, робот может также использовать разметку индексируемой страницы. И в индексе присваивать наибольший вес термину, используемому, например, в заголовке. Автор информационного ресурса также может повлиять на индексацию собственной страницы, указав роботу, какие термины надо использовать для индексирования. Но многие поисковые системы отказались от использования описаний ресурсов, представленных авторами. Это было сделано по причине недобросовестности некоторых авторов, которые использовали для описания своих страниц термины, наиболее часто встречающиеся в запросах.
Так как на запрос могут быть выданы ссылки на сотни ресурсов, необходимо предоставить пользователю отсортированный список. Наиболее часто используется сортировка по релевантности. Она происходит по тем же принципам, что и отбор терминов, применяющихся при индексировании.
Как уже отмечалась ранее, произвести точный поиск тем сложнее, чем шире круг потребностей пользователей системы. В глобальной сети эта проблема принимает глобальный же характер.
Очень сильно усложняется поиск по причине непрофессионализма как пользователя, формулирующего запрос, так и автора информационного ресурса. И если непрофессионализм пользователя мешает лишь ему самому (если не считать непроизводительной загрузки поискового сервера), то непрофессионализм автора ресурса стоит гораздо больше. Многие отмечают все время растущий уровень шума в результатах, выдаваемых на запрос.
Для уменьшения уровня этого шума может использоваться платная регистрация ресурса, которая подразумевает, что автор ответственно относится к его содержимому. Существует, например, система платной регистрации RealNames. База данных этой службы используется некоторыми поисковыми системами. Ресурсы, зарегистрированные в базе RealNames, будут помещаться в начало списка найденных документов.
Дата добавления: 2015-07-12; просмотров: 77 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Интерфейс системы | | | Справочно-правовые системы |