Читайте также:
|
На сьогодні тестування програмного забезпечення – один з найбільш дорогих етапів життєвого циклу програмного забезпечення, на нього відводиться від 50% до 65% загальних витрат. У царині кодування ПЗ широкого розповсюдження набули різноманітні CASE- засоби, які дозволяють прискорити процеси створення коду. На жаль, в галузі тестування відчувається нестача таких засобів і більшість зусиль витрачається на ручне тестування.
Зазвичай, для проведення тестування застосовуються методи структурного («білий ящик») та функціонального («чорний ящик») тестування.
При функціональному тестуванні вихідний код програми не доступний. Суть полягає в перевірці відповідності поведінки програми її зовнішній специфікації. Критерієм повноти тестування вважається перебір всіх можливих значень вхідних даних, що здійснити на практиці надзвичайно важко. При структурному тестуванні текст програми відкритий для аналізу. Суть даного методу полягає в перевірці внутрішньої логіки ПЗ. Повним тестуванням у цьому випадку буде таке, що приведе до перебору всіх можливих шляхів на графі передач керування програми. Число таких шляхів може досягати десятків тисяч. Крім того, виникає питання про створення тестів, що забезпечують дане покриття. Здійснити повне всеохоплююче тестування навіть простої програми вкрай важко, а часом і неможливо в силу обмеженості часу й ресурсів. Отже, необхідно мати певні критерії за якими мають обиратися контрольні приклади та критерії зупинки процесу тестування.
Чорний ящик – функціональне тестування, завданням функціонального тестування є перевірка відповідності програми своїм специфікаціям. При даному підході текст програми не доступний, і програма розглядається як «чорний ящик». Найпоширенішими видами функціонального тестування є методи випадкового тестування, еквівалентної розбивки й аналізу граничних умов.
Випадкове (стохастичне) тестування. Відповідно до даного методу створюється необхідна кількість незалежних тестів, у яких вхідні дані генеруються випадковим чином. Недоліком даного методу є загальна кількість тестів, які необхідно згенерувати відповідно до вимог надійності, до того ж забезпечивши незалежність цих тестів. Так, наприклад, для забезпечення надійності програмного забезпечення з імовірністю відмови не більше 10-5 і з помилкою не більше 5%, потрібно згенерувати 299 572 тестів. З метою скорочення кількості необхідних тестів Майєрсом було запропоновано розглядати розбиття безлічі вихідних даних на еквівалентні класи.
Тестування за класами еквівалентності. Відповідно до даної методики необхідно розбити множину значень вхідних даних на кінцеве число підмножин (які будуть називатися класами еквівалентності), щоб кожний тест, що є представником певного класу, був еквівалентним будь-якому іншому тесту цього класу. Два тести є еквівалентними, якщо вони виявляють ті самі помилки. Проектування тестів за методом класів еквівалентності проводиться у два етапи: 9 - виділення за специфікацією класів еквівалентності; - побудова множини тестів. На першому етапі відбувається вибір зі специфікації кожної вхідної умови та розбиття її на дві або більше групи, що відповідають так званим ―правильним‖ класам еквівалентності (ПКЕ) та ―неправильним‖ класам еквівалентності (НКЕ), тобто множинам допустимих для програми й недопустимих значень вхідних даних. Цей процес залежить від вигляду вхідної умови. Наприклад: якщо вхідна умова описує множину (|х|<=0.5), то визначається один ПКЕ (-0.5<=х <=0.5) і два НКЕ (х< -0.5; х>0.5). На другому етапі методу класів еквівалентності виділені класи використовуються для побудови тестів. Для НКЕ тести проектуються таким чином, що кожен тест покриває один і тільки один НКЕ, доки всі НКЕ не будуть покриті. Метод класів еквівалентності дозволяє значно скоротити кількість тестів у порівнянні з методом випадкового тестування, але також має свої недоліки. Основний з них - це складність виділення класів еквівалентності, особливо НКЕ, а також можливий пропуск певних типів високоефективних тестів (тобто тестів, що характеризуються великою ймовірністю виявлення помилок). Так, наприклад, мінімальні й максимальні припустимі значення вхідних параметрів дозволяють виявити більшість помилок, пов'язаних з відповідностями й переповненнями типів даних. Для вирішення даної проблеми був запропонований метод аналізу граничних умов.
Метод аналізу граничних умов Під граничними умовами розуміють ситуації, що виникають безпосередньо на границі певної вхідної або вихідної умови, вище або нижче її. Метод аналізу граничних умов відрізняється від методу класів еквівалентності наступним: 10 - вибір будь-якого представника класу еквівалентності здійснюється таким чином, щоб перевірити тестом кожну границю цього класу; - при побудові тестів розглядаються не тільки вхідні умови, але й вихідні (тобто певні специфіковані обмеження на значення вхідних даних). Загальні правила методу аналізу граничних умов: побудувати тести для границь множини допустимих значень вхідних даних і тести з недопустимими значеннями, що відповідають незначному виходу за межі цієї множини. Наприклад, для множини [-1.0; 1.0] будуються тести -1.0; 1.0; - 1.001; 1.001; Зауважимо, що на практиці з метою локалізації несправностей створюють також тести, що відповідають допустимим значенням, тобто є внутрішніми для множини та ті, що незначно відхиляються від граничних значень: -1.0; 1.0; -1.001; 1.001;0.999;- 0.999 Якщо множина допустимих значень вхідних даних дискретна, то будуються тести для мінімального й максимального значення вхідних умов і тести для значень, більших або менших цих величин. Наприклад, якщо вхідний файл може містити від 1 до 255 записів, то вибираються тести для порожнього файлу та файлу, що містить 1, 254, 255 і 256 записів. 1) використовувати перше правило для кожної вихідної умови; 2) якщо вхідні й вихідні дані програми являють собою впорядковану множину (послідовний файл, лінійний список та ін.), то при тестуванні зосередити увагу на першому й останньому елементі множини; 3) повторити процедуру для всіх знайдених граничних умов. 11 Аналіз граничних умов - один з найбільш корисних методів проектування тестів. Але він часто виявляється неефективним через те, що граничні умови іноді ледь вловимі, а їхнє виявлення досить важко.
Білий ящик - Структурне тестування, або тестування «білого ящика», - це методика аналізу вихідного коду програми. Існує три різновиди структурного тестування: тестування на основі потоку керування програми, на основі потоку даних та мутаційне тестування. При використанні першого типу тестується логіка програми, що представлена у вигляді графа керування: вершинами є оператори, а гілками - переходи між ними. При тестування на основі потоку даних увага приділяється взаємозв'язкам між змінними. Виділяються вершини, у яких змінна ініціалізується та в яких використовується, і вивчаються переходи й взаємозв'язки між такими вершинами. Мутаційне тестування полягає у внесенні несправностей у вихідний код програми та порівняння роботи вихідної програми та програми мутанта. Оскільки здійснити вичерпне структурне тестування вкрай важко, необхідно вибрати такі критерії його повноти, які допускали б їхню просту перевірку й полегшували б цілеспрямований підбір тестів.
Критерій покриття операторів (C0):
Кожен оператор програми повинен буди виконаний (покритий) хоча б один раз. Цей критерій є найбільш слабким з використовуваних у структурному тестуванні, тому що проходження всіх операторів не гарантує перевірку правильності послідовності попарних переходів між ними.
Критерій покриття рішень(C1):
Кожна гілка алгоритму (кожний перехід між вершинами) має бути пройдена (виконана) хоча б один раз. Виконання даного критерію, у загальному випадку, забезпечує й покриття операторів, проте критерій С1 не є ідеальним. Так, наприклад, він не забезпечує перевірку правильності обробки операторів логічних переходів та циклів.
Критерій покриття рішень(C1¥):
Критерій покриття шляхів (С кожен шлях в алгоритмі, де шлях – це послідовність вершин (nstart, n1,..., nm, nfinal) має бути протестований хоча б один раз. Два шляхи вважаються ідентичними, якщо послідовності вершин ідентичні. Це найбільш повний критерій, проте його реалізація ускладнена через величезну кількість необхідних тестів. Так, наприклад, проблемою є тестування циклічних структур, в силу необхідності їх багаторазового повторення. Для спрощення даної процедури було запропоновано два наступних критерії:
Граничне тестування циклу: відповідно до даного критерію має бути виконаний вхід у кожний цикл (проте виконання ітерацій не вимагається).
Внутрішнє тестування циклу: відповідно до даного критерію має бути виконаний вхід у кожний цикл і як мінімум одна ітерація. Вочевидь, що виконання другого критерію забезпечує виконання критерію граничного тестування циклів, але разом з тим, вимагає більшої кількості тестів. Вище було зазначено, що часто виникають проблеми з тестуванням логічних конструкцій розгалуження. Для цього були запропоновані критерії покриття умов. Використання даних критеріїв може дати підбір тестів, що забезпечують перехід у програмі, що пропускається при використанні критерію C1. Наприклад, при використанні критерію покриття переходів при тестуванні фрагмента: if(x&&y) function1(); else function2(); для переходу на гілку else досить, щоб виконалася тільки умова not(x), що не гарантує перевірку працездатності оператора умови в цілому, тобто того, що при not(y) теж буде здійснений перехід на гілку else.
3.2. Інструкція користувача
Загальна навігація
Для переходу між елементами діалогу використовують стандартний підхід прийнятий для роботи з елементами інтерфейсу:
Tab – переміщення до наступного елементу управління (кнопка, поле введення, список та т. ін.);
Shift+Tab – переміщення до попереднього елементу управління;
, ¯, ®, – переміщення між рівноправними елементами управління;
Enter – підтвердження вибору;
Space – аналогічно Enter у випадку, якщо фокус знаходиться на кнопці;
Escape – скасування дії, що виконується;
Delete – видалення символу, безпосередньо під курсором;
Backspace – видалення символу безпосередньо перед курсором;
Ліва кнопка миші – вибір елементу управління.
Початок роботи із програмою
Після завантаження web-додатку з’явиться сторінка системного входу, яка має вид показаний на рисунку 3.2.1.

Рисунок 3.2.1 – Системний вхід
Для входу до перекладача існує шість типів користувачів: адміністратор, супер абонент, абонент, експерт, користувач і гість. На сторінці системного входу всі вони аутентифікуються та авторизуються й переходять на відповідну сторінку: адміністратора (рисунок 3.2.2), супер абонента (рисунок 3.2.3), абонента (рисунок 3.2.4), експерта (рисунок 3.2.5), користувача (рисунок 3.2.6) та гостя (рисунок 3.2.7).

Рисунок 3.2.2 – Сторінка адміністратора

Рисунок 3.2.3 – Сторінка супер абонента
Сторінка адміністратора
Адміністратор має право керувати користувачами перекладача. Йому доступні такі дії: додавати та видаляти користувача, редагувати дані користувачів (група користувачів, логін, пароль й електронна поштова скринька).
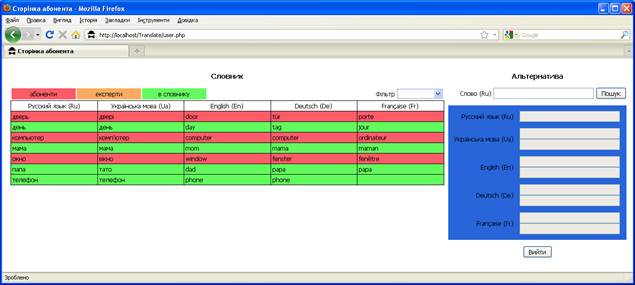
Рисунок 3.2.4 – Сторінка абонента

Рисунок 3.2.5 – Сторінка експерта

Рисунок 3.2.6 – Сторінка користувача
Для того, щоб редагувати дані користувача або видаляти користувача, його потрібно спочатку вибрати. Для цього служить радіо-кнопка ліворуч від логіну користувача (див. рисунок 3.2.2).

Рисунок 3.2.7 – Сторінка гостя
Список користувачів виводиться у вигляді таблиці. Користувачі групуються за типом користувача, а потім, в межах типу, за алфавітом.
При додаванні користувача або редагуванні даних, виводяться поля з пустими даними (додавання) чи з даними для редагування (рисунок 3.2.8).

Рисунок 3.2.8 – Редагування даних
При спробі видалення користувача, система запитує чи впевнений адміністратор у тому, що він бажає видалити користувача.
Для завершення роботи, адміністратору потрібно натиснути кнопку Вийти.
Сторінка супер абонента
Супер абонент має право додавати нове слово на розгляд абонентів, яке після цього або додається до словника, або передається на розгляд експертів. На своїй сторінці він може переглядати базу даних словника (ліворуч), додавати нове слово для розгляду абонентами (праворуч) або завершити роботу.
Дані, що знаходяться в базі даних, розділяються на три типи: слова, що розглядаються абонентами (в таблиці розташовані в рядках з рожевим тлом); слова, що знаходяться на розгляді експертів (оранжеве тло); слова, що знаходяться в словнику (світло-зелене тло). Дані можна відфільтрувати за допомогою випадаючого списку Фільтр (рисунок 3.2.9).

Рисунок 3.2.9 – Фільтрування даних
Додавання слова здійснюється за допомогою форми розташованої праворуч на сторінці супер абонента (див. рисунок 3.2.3). Доступним є поле Слово (Ru) для введення слова російською мовою та кнопка пошук, яка спрацьовує тільки якщо в полі введено слово (інакше видається відповідне повідомлення). При введені існуючого в базі даних слова, з’являється надпис, про його статус та переклад на різні мови (рисунок 3.2.10).

Рисунок 3.2.10 – Існуюче слово та його переклад
Якщо вводиться нове слово, то з’являються поля для введення його перекладу (українською, англійською, німецькою та французькою мовами). Крім того, додається кнопка Додати (рисунок 3.2.11). Переклад українською та англійською мовами є обов’язковим. При додаванні слова в словник, воно з’являється в базі даних словника зі статусом – розглядається абонентами.
При виборі кнопки Вийти супер абонент завершує свою роботу й web-додаток повертає користувача на сторінку системного входу.

Рисунок 3.2.11 – Додати нове слово
Сторінка абонента
Абонент має право додавати альтернативні переклади слів, що введені супер абонентом. Він може також, як і супер абонент, переглядати базу даних словника.
При введенні в поле Слово (Ru) неіснуючого слова видається відповідне повідомлення, інакше, в залежності від статусу слова, можливі такі випадки:
– слово знаходиться в словнику – видається його переклад (рисунок аналогічний рисунку 3.2.10);
– слово зажадає експертної оцінки – видаються варіанти перекладу слів запропоновані абонентами (рисунок 3.2.12);

Рисунок 3.2.12 – Варіанти перекладу слова
– слово розглядається абонентами – якщо альтернативні переклади цим абонентом вже були введені, то він їх може просто переглянути (рисунок 3.2.13), інакше ввести свої варіанти та натиснути кнопку Підтвердити (рисунок 3.2.14). Якщо після введення альтернатив з’ясується, що всі абоненти вже ввели свої варіанти, то статус слова змінюється і воно передається або на розгляд експертів, або додається в словник (якщо варіанти всіх абонентів співпали).

Рисунок 3.2.13 – Існуючі альтернативи

Рисунок 3.2.14 – Введення альтернатив
Для завершення роботи абонент повинен натиснути кнопку Вийти.
Сторінка експерта
Експерти мають право розглядати альтернативні переклади слів і колегіально виносити висновок про правильність того чи іншого варіанту перекладу. Експерт може переглядати базу даних словника з можливістю її фільтрації.
В полі Слово (Ru) експерт може вибрати тільки слово, що зажадає експертної оцінки, інакше видається повідомлення про відсутність таких слів.
Після вибору із можливих альтернатив (рисунок 3.2.15), всі експерти повинні підтвердити свій вибір шляхом аутентифікації (ввести пароль та натиснути кнопку Підтвердити). Тільки після цього слово заноситься до словника.

Рисунок 3.2.15 – Експертиза слова
Після завершення роботи експертів треба вибрати кнопку Вийти.
Сторінка користувача
Користувачі мають право переглянути тільки слова розташовані в словнику, а також здійснити пошук потрібного слова (російською, українською, англійською, німецькою та французькою мовами) та його перекладу. Для пошук слів потрібно вибрати мову (за допомогою випадаючого списку), ввести потрібне слово та вибрати кнопку Пошук. В результаті над заголовком таблиці з’явиться рядок із шуканим словом. Тло рядка буде світло-зеленого кольору, а слово, що введене, буде розташовано на зеленому тлі (рисунок 3.2.16). Якщо слово матиме декілька перекладів, то вони будуть розташовані в декілька рядків.
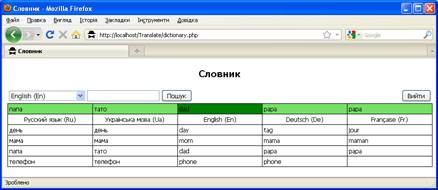
Рисунок 3.2.16 – Пошук слів у словнику
Завершити роботу можна за допомогою кнопки Вийти.
Сторінка гостя
Гість має право переглянути тільки перші п’ять слів розташованих у словнику (демо версія) без можливості пошуку. Доступною є можливість вибору мови та кнопки Вийти (див. рисунок 3.2.7).
Розділ 4. Організація виробництва
4.1. Захист сайту від несанкціонованого доступу
Іноді буває потрібно закрити від стороннього доступу PHP сторінку, якщо Ви робите захищеної частини сайту. Це може бути якась прихована інформація для ваших клієнтів або відвідувачів сайту, якийсь адміністраторський інтерфейс для вас і т.д. Можна придумати сотні різних завдань вимагають обмеження доступу.
Закрити таку сторінку можна кількома взаємодоповнюючими один одного способами:
Захист паролем (логін / пароль) за допомогою змінних $ _SERVER ["PHP_AUTH_USER"] і $ _SERVER ["PHP_AUTH_PW"].
Захист по IP адресою клієнта за допомогою змінної $ _SERVER ["REMOTE_ADDR"].
Захист по MAC адресу в локальних мережах (додатково до захисту по IP).
Розберемо спочатку перший спосіб, який є основним. Він дозволяє закрити доступ до сторінки за логіном і паролем, таким чином доступ можуть отримати тільки люди знаючі логін і пароль. До того ж їх можна розділяти за цією ознакою і видавати відповідно різну інформацію для кожного. Реалізується за допомогою видачі спеціальних полів в заголовку протоколу HTTP. Створимо функцію auth_send ():
<?phpfunction auth_send(){ header('WWW-Authenticate: Basic realm="Closed Zone"'); header('HTTP/1.0 401 Unauthorized'); echo "<html><body bgcolor=white link=blue vlink=blue alink=red>","<h1>Ошибка аутентификации</h1>","<p>Обратитесь к администратору для получения логина и пароля.</p>","</body></html>"; exit;};?>Цю функція повідомляє браузеру про те, що для доступу потрібна авторизація за логіном і паролем. І видає також сторінку в HTML для користувача.
<?php // код auth_send()... $login = "admin"; $password = "admin"; if (!isset($_SERVER['PHP_AUTH_USER'])) { auth_send(); } else { $auth_user = $_SERVER['PHP_AUTH_USER']; $auth_pass = $_SERVER['PHP_AUTH_PW']; if (($auth_user!= $login) || ($auth_pass!= $password)) { send_auth(); }; }; echo "<html><body bgcolor=white link=blue vlink=blue alink=red>","<h1>Добро пожаловать!</h1>","<p>Вы зашли по логину ",$auth_user," и паролю ",$auth_pass,".</p>","</body></html>";?>
Код перевірки логіна і пароля не надто складний в даному випадку, так як реалізований для однієї людини. Логіка роботи проста, якщо немає змінної $ _SERVER ['PHP_AUTH_USER'] і $ _SERVER ['PHP_AUTH_PW'] або їх значення не збігаються з потрібними, то викликаєте функцію auth_send (). Не забувайте, що в ній в кінці викликається exit, тому виконання програми припиняється.
Наступний щабель захисту реалізується з фільтрації IP адреси клієнтів. Звичайно в інтернеті багато провайдерів видають IP адреси на час і цей захист використовувати марно, але якщо йдеться про корпоративні локальних мережах, то дана перевірка забезпечить додатковий захист.
<?php // список разрешенных IP адресов через пробел $allowed_ips = "192.168.10.15 192.168.10.2 212.34.124.56"; $ips = explode(" ",$allowed_ips); if (array_search($_SERVER["REMOTE_ADDR"],$ips) === FALSE) { echo "<p>Ваш IP не найден!!!"; exit; };?> Тут в рядку $ allowed_ips через пробіл вказані IP адреси, яким дозволений доступ. Далі отримуємо масив за допомогою explode () і робимо пошук адреси клієнта з $ _SERVER ["REMOTE_ADDR"]. Я для пошуку застосував функцію array_search (), так як неверняка її код реалізований на Сі буде працювати трохи швидше, ніж те, що ми можемо написати на PHP за допомогою циклів for або foreach. Але швидкість тут не головне:) І остання ступінь захисту це перевірка MAC адреси. Вона відноситься до розряду параноїдальних і її варто використовувати, якщо ви отримуєте доступ з локальної мережі і дані, які ви захищаєте дійсно дуже важливі. Я поки реалізував цю перевірку тільки на системі Linux, в силу відносної простоти реалізації. Але Ви можете її спробувати реалізувати під будь-яку іншу платформу. Пишемо функцію:<?phpfunction resolve_mac_for_ip($ip){ $found_mac = NULL; $f_in = fopen("/proc/net/arp","r"); if ($f_in!= NULL){ fgets($f_in); while (!feof($f_in)){ $t = fgets($f_in); if ($t!= NULL){ $str_split = preg_split ("/[\s]+/", $t); if ($str_split[0]==$ip) { $found_mac = $str_split[3]; break; }; }; }; fclose($f_in); }; return $found_mac;}; echo "Ваш IP=",$_SERVER["REMOTE_ADDR"]," і MAC=",resolve_mac_for_ip($_SERVER["REMOTE_ADDR"]);?>Як лінуксоїди вже зрозуміли вона заснована на ARP таблиці системи, доступ до якої можна отримати за допомогою файлу / proc / net / arp. Функція шукає по рядках необхідний IP адресу і повертає його MAC адреса:
Ваш IP=192.168.10.15 и MAC=00:04:31:E4:F8:37В системі Windows можливо теж є якісь способи отримати MAC простіше, але з тих, які реально працюють, це висновок ARP таблиці системи командою:
C:\WINDOWS\>arp -a Інтерфейс: 192.168.10.15 on Interface 0x1000003 Адрес IP Физический адрес Тип 192.168.10.1 00-50-22-b0-6a-aa динамічний 192.168.10.2 00-0f-38-68-e9-e8 динамічний 192.168.10.3 00-04-61-9e-26-09 динамічний 192.168.10.5 00-0f-38-6a-b1-18 динамічнийВ даному розділі дипломної роботи проводиться економічне обгрунтування доцільності розробки програмного забезпечення. Зокрема розраховується комплексний показник якості проектного рішення, який показує його переваги в порівнянні з аналогами. А також на основі показника якості та ціни споживання проектного рішення та його аналога визначається коефіцієнт конкурентноздатності, який показує спроможність даного проектного рішення конкурувати з аналогами.
Дане програмне забезпечення призначене для спрощення та пришвидшення процесу проектування веб-додатків. Застосування даного проектного рішення повинно суттєво скоротити час і трудомісткість розробки сенсорів фізичних величин на ПАХ та покращити їх якість.
Дата добавления: 2015-07-11; просмотров: 339 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Программа та методика тестування | | | Запозичення з класичних мов |