Читайте также:
|
В дифференциальной психометрике проблемы валидности и надежности тесно взаимосвязаны, тем не менее мы последуем традиции раздельного изложения методов проверки этих важнейших психометрических свойств теста.
Надежность и точность. Как уже отмечалось в разделе 3.1, общий разброс (дисперсию) результатов произведенных измерений можно представить как результат действия двух источников разнообразия: самого измеряемого свойства и нестабильности измерительной процедуры, обусловливающей наличие ошибки измерения. Это представление выражено в формуле, описывающей надежность теста и виде отношения истинной дисперсии к дисперсии эмпирически зарегистрированных баллов:
 (3.2.1)
(3.2.1)
Так как истинная дисперсия и дисперсия ошибки связаны очевидным соотношением, формула (3.2.1) легко преобразуется в формулу Рюлона:
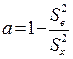 (3.2.2)
(3.2.2)
где а - надежность теста;  . -дисперсия ошибки.
. -дисперсия ошибки.
Величина ошибки измерения - обратный индикатор точности измерения. Чем больше ошибка, тем шире диапазон неопределенности на шкале (доверительный интервал индивидуального балла), внутри которого оказывается статистически возможной локализация истинного балла данного испытуемого. Таким образом, для проверки гипотезы о значимости отличия балла испытуемого от среднего значения оказывается недостаточным только оценить ошибку среднего, нужно еще оценить ошибку измерения, обусловливающую разброс в положении индивидуального балла (рис. 7).

Рис. 7. Соотношение распределений Sm – стандартное отклонение эмпирического среднего, St – стандартное отклонение ошибки
Как же определить ошибку измерения? На помощь приходят корреляционные методы, позволяющие определить точность (надежность) через устойчивость и согласованность результатов, получаемых как на уровне целого теста, так и на уровне отдельных его пунктов.
Надежность целого теста имеет две разновидности.
1. Надежность-устойчивость (ретестовая надежность). Измеряется с помощью повторного проведения теста на той же выборке испытуемых, обычно через две недели после первого тестирования. Для интервальных шкал подсчитывается хорошо известный коэффициент корреляции произведения моментов Пирсона:

где х1i. - тестовый балл i -го испытуемого при первом измерении;
х2i. - тестовый балл того же испытуемого при повторном измерении;
n - количество испытуемых.
Оценка значимости этого коэффициента основывается на несколько иной логике, чем это обычно делается при проверке нулевой гипотезы - о равенстве корреляций нулю. Высокая надежность достигается тогда, когда дисперсия ошибки оказывается пренебрежительно малой. 'Относительную долю дисперсии ошибки легко определить по формуле
 (3.2.4)
(3.2.4)
Таким образом, для нас существеннее близость к единице, а не отдаленность от нуля. Обычно в тестологической практике редко удается достичь коэффициентов, превышающих 0,8. При г = 0,75 относительная доля стандартной ошибки равна 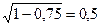 . Этой ошибкой, очевидно, нельзя пренебречь. При такой ошибке эмпирически полученное отклонение индивидуального тестового балла от среднего по выборке оказывается, как правило, завышенным. Для того чтобы выяснить «истинное» значение тестового балла индивида, применяется формула
. Этой ошибкой, очевидно, нельзя пренебречь. При такой ошибке эмпирически полученное отклонение индивидуального тестового балла от среднего по выборке оказывается, как правило, завышенным. Для того чтобы выяснить «истинное» значение тестового балла индивида, применяется формула
 (3.2.5)
(3.2.5)
где 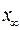 - истинный балл; '
- истинный балл; '
хi — эмпирический балл i -го испытуемого;
r - эмпирически измеренная надежность теста;
 - среднее для теста.
- среднее для теста.
Предположим, испытуемый получил балл IQ по шкале Стэнфорда.-Бине, равный 120 нормализованным очкам, М = 100, г = 0,9. Тогда истинный балл  = 0,9
= 0,9 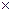 120 + 0,1 100 =118.
120 + 0,1 100 =118.
Конечно, требование ретестовой надежности является корректным лишь по отношению к таким психическим характеристикам индивидов, которые сами являются устойчивыми во времени. Если мы создаем тест для измерения эмоциональных состояний (бодрости, тревоги и т. д.), то, очевидно, требовать от него ретестовой надежности бессмысленно: у испытуемых быстрее изменится состояние, чем они забудут свои ответы по первому тестированию.
Для шкал порядка в качестве меры устойчивости к перетестированию используется коэффициент ранговой корреляции Спирмена:
 , (3.2.6)
, (3.2.6)
где di — разность рангов /-го испытуемого в первом и втором ранговом ряду.
С помощью компьютера определяется более надежный коэффициент ранговой корреляции Кендалла (1975).
2. Надежность- согласованность (одномоментная надежность).
Эта разновидность надежности не зависит от устойчивости, имеет особую содержательную и операциональную природу. Простейшим способ ее измерения состоите коррелировании параллельных форм теста (Анастази Д., 1982, кн. 1,с. 106). Чаще всего параллельные формы теста получают расщеплением составного теста на «четную» и «нечетную» половины: к первой относятся четные пункты, ко второй - нечетные. По каждой половине рассчитываются суммарные баллы и между двумя рядами баллов по испытуемым определяются допустимые (с учетом уровня измерения) коэффициенты корреляции. Если параллельные тесты не нормализованы, то предпочтительнее использовать ранговую корреляцию. При таком расщеплении получается коэффициент, относящийся к половинам теста. Для того чтобы найти надежность целого теста пользуются формулой Спирмена - Брауна:
 (3.2.7)
(3.2.7)
где rx - эмпирически рассчитанная корреляция для половин.
Делить тест на две половины можно разными способами, и каждый раз получаются несколько разные коэффициенты (Аванесов В. С., 1982, с. 122), поэтому в психометрике существует способ оценки синхронной надежности, который соответствует разбиению теста на такое количество частей, сколько в нем отдельных пунктов. Такова формула Кронбаха:
 (3.2.8)
(3.2.8)
где а - коэффициент Кронбаха;
k- количество пунктов теста;
 - дисперсия по j -му пункту теста;
- дисперсия по j -му пункту теста;
 - дисперсия суммарных баллов по всему тесту.
- дисперсия суммарных баллов по всему тесту.
Обратите внимание на структурное подобие формулы Кронбаха (3.2.2) и формулы Рюлона (3.2.8).
Несколько раньше была получена формула Кьюдера - Ричардсона, аналогичная формуле Кронбаха для частного случая - когда ответы на каждый пункт теста интерпретируются как дихотомические переменные с двумя значениями (1 и 0):

 (3.2.9)
(3.2.9)
где KR20 - традиционное обозначение получаемого коэффициента;
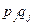 -дисперсия i -и дихотомической переменной, какой является
-дисперсия i -и дихотомической переменной, какой является
i -й пункт теста; р =  , q = 1 - p
, q = 1 - p
В 1957 г. Дж. Ките предложил следующий критерий для оценки статистической значимости коэффициента a:
 (3.2.10)
(3.2.10)
где 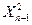 - эмпирическое значение статистики % квадрат с п-1 степенью свободы;
- эмпирическое значение статистики % квадрат с п-1 степенью свободы;
k - количество пунктов теста;
n - количество испытуемых;.
a - надежность.
Формулы (3.2.8) и (3.2.9) позволяют оценить взаимную согласованность пунктов теста, используя при этом только подсчет дисперсий. Однако коэффициенты а и KR2I> позволяют оценить и среднюю корреляцию между i -м и j -м произвольными пунктами теста, так как связаны с этой средней корреляцией следующей формулой:
 11)
11)
где  - средняя корреляция между пунктами теста. Легко увидеть идентичность формулы (3.2.11) обобщенной формуле Спирмена - Брауна, позволяющей прогнозировать повышения синхронной надежности теста с увеличением количества пунктов теста в k раз (Аванесов В. С., 1982, с. 121). Из этой формулы видно, что при больших k малое значение
- средняя корреляция между пунктами теста. Легко увидеть идентичность формулы (3.2.11) обобщенной формуле Спирмена - Брауна, позволяющей прогнозировать повышения синхронной надежности теста с увеличением количества пунктов теста в k раз (Аванесов В. С., 1982, с. 121). Из этой формулы видно, что при больших k малое значение  может сочетаться с высокой надежностью. Пусть = 0,1, a k =100, тогда по формуле (3.2.11)
может сочетаться с высокой надежностью. Пусть = 0,1, a k =100, тогда по формуле (3.2.11)

Широкое распространение компьютерных программ факторного анализа для исследования взаимоотношений между пунктами теста (по одномоментным данным) привело к обоснованию еще одной достаточно эффективной формулы надежности теста, которой легко воспользоваться, получив стандартную распечатку компьютерных результатов факторного анализа по методу главных компонент:
 (3.2.12)
(3.2.12)
где θ - коэффициент, получивший название тета-надежности теста;
k - количество пунктов теста;
λ1 - наибольшее значение характеристического корня матрицы
интеркорреляций пунктов (наибольшее собственное значение, или абсолютный вес первой главной компоненты).
Как и предыдущие формулы, формула (3.2.12) также относится к оценке надежности теста, направленного на измерение одной характеристики. Но, кроме того, она применима и для многофакторного теста, хотя и нуждается в пересчете после первоначального отбора пунктов, релевантных фактору (после того, как на основании многофакторного анализа отобраны пункты по одному фактору, снова проводится факторный анализ - только для этих отобранных пунктов).
Надежность отдельных пунктов теста. Надежность теста обеспечивается надежностью пунктов, из которых он состоит. Чтобы повысить ретестовую надежность теста в целом, надо отобрать из исходного набора пунктов, апробируемых в пилотажных психометрических экспериментах, такие пункты, на которые испытуемые дают устойчивые ответы. Для дихотомических пунктов (типа «решил - не решил», «да - нет») устойчивость удобно измерять с использованием четырехклеточной матрицы сопряженности:
Тест 1
Да Нет
| a | B |
| c | D |
Да Тест 2
Нет
Здесь в клеточке а суммируются ответы «Да», данные испытуемым при первом и втором тестировании, в клеточке b - число случаев, когда испытуемый при первом тестировании отвечал «Да», а при втором - «Нет» и т. д. В качестве меры корреляции вычисляется фи-коэффициент:
 (3.2.13)
(3.2.13)
Как известно, значимость фи-коэффициента определяется с по мощью критерия хи-квадрат:
 (3.2.14)
(3.2.14)
Если вычисленное значение хи-квадрат выше табличного с одной степенью свободы, то нулевая гипотеза (о нулевой устойчивости) отвергается. Удобство использования фи-коэффициента состоит в том, что он одновременно оценивает степень оптимальности данного пункта теста по силе (трудности): фи-коэффициент оказывается тем меньшим, чем сильнее частота ответов «да» отличается от частоты ответа «нет».
Кроме того, сама четырехклеточная матрица позволяет проследить возможную несимметричность в устойчивости ответов «да» и «нет» (это важнее для задач, чем для вопросов: например, может оказаться, что все испытуемые, уже решившие однажды данную задачу, решают ее при повторном тестировании; это наводит на мысль о том, что при втором тестировании происходит сбережение опыта, приобретенного при первом тестировании). Выявленные в результате такого анализа неустойчивые и неинформативные (слишком сильные или слишком слабые) пункты должны быть исключены из теста. Пункты следует считать недостаточно устойчивыми, если на репрезентативной выборке величина  превышает 0,71. При этом φ< 0,5.
превышает 0,71. При этом φ< 0,5.
Для т<?го чтобы повысить одномоментную (синхронную) надежность теста, следует из исходной пилотажной батареи пунктов отбросить те, которые плохо согласованы с остальными[12]. В отсутствие компьютера согласованность для пунктов также очень просто определяется с помощью четырехклеточной матрицы. В этом случае в первом столбце суммируются ответы испытуемых из «высокой».группы (пр величине суммарного балла), во втором столбце - из «низкой».
Высокая Низкая
| A | B |
| C | D |
Да
Нет
При нормальном распределении частот суммарных баллов «высокая» и «низкая» группы отсекаются справа и слева 27%-ными маргинальными квантилями (рис. 8).
Для оценки согласованности с суммарным баллом применяется полная[13] или упрощенная формула фи-коэффициента:
 (3.2.15)[14]
(3.2.15)[14]
где  - количество ответов «верно» («да») на i -й пункт теста;
- количество ответов «верно» («да») на i -й пункт теста;
N* - сумма всех элементов матрицы;
N* = n • 0,54 где n - объём выборки;
Pi = а + b - При включении в эстремальную группу 1/3 выборки
N* = 0,66 • n.

Рис. 8. Квантили «высокой» и «низкой» группы на графике распределения тестовых баллов
В некоторых случаях подобный анализ позволяет уточнить ключ для пункта: если пункт получает значимый положительный фи-коэффициент, то ключ определяется значением «+1», если пункт получает значимый отрицательный фи-коэффициент значением «-1». Если пункт получает незначимый фи-коэфф.ициент, то его целесообразно исключить из теста.
При ручных вычислениях фи-коэффициента удобно вначале с помощью формул (3.2.14) и (3.2.15) определить граничное значение значимого (по модулю) фи-коэффициента. Например, при объеме выборки в 100 человек и уровне значимости р < 0,01 пороговое значение вычисляется так:
 (3.2.16)
(3.2.16)
При постоянном использовании компьютера при подсчете суммарных баллов ключ для каждого пункта Q целесообразно определить в виде самого фи-коэффициента (или другого коэффициента корреляции), определенного при коррелировании ответов на пункт с суммарным баллом. Тогда тестовый балл подсчитывается по формуле
 (3.2.17)
(3.2.17)
где хi — суммарный балл i -го испытуемого;
 - ответ «верно» (+1) или «неверно» (-1) i -го испытуемого на i -й пункт;
- ответ «верно» (+1) или «неверно» (-1) i -го испытуемого на i -й пункт;
Сi- ключ для i -го пункта: С = +1 для прямого, С= -1 для обратного.
Более чувствительный коэффициент, который также применяется для дихотомических пунктов, - это точечный бисериальный коэффициент корреляции, учитывающий амплитуду отклонения индивидуальных суммарных баллов от среднего балла:
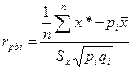 3.2.18)
3.2.18)
где 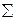 x* - сумма финальных баллов тех индивидов, которые дали утвердительный ответ на i -й пункт теста (решили i -ю задачу);
x* - сумма финальных баллов тех индивидов, которые дали утвердительный ответ на i -й пункт теста (решили i -ю задачу);
Sx - стандартное отклонение для суммарных баллов всех индивидов из выборки;
 - стандартное отклонение по i -му пункту;
- стандартное отклонение по i -му пункту;
- средний балл по всем пунктам.
А. Анастази относит критерий внутренней согласованности теста к валидности (Анастази А., 1982, кн. 1, с. 143), однако если и можно в данном случае говорить о валидности, то только в смысле особой внутренней валидности теста. Как правило, слишком высокая согласованность снижает внешнюю валидность теста по критерию (см. раздел 3.3). Если проверяется согласованность пунктов, составленных одним автором (одним коллективом по стандартной инструкции), то выявление достаточного набора согласованных пунктов свидетельствует о внутренней валидности (согласованности) разработанного диагностического понятия (конструкта).
В компьютерных данных факторного анализа аналогом корреляции пункта с суммарным баллом является нагрузка пункта на ведущий фактор («факторная валидность» в терминах А. Анастази). Если прибегать к геометрическому изображению нагрузки как проекции вектора-пункта на ось-фактор, то структура пунктов хорошо согласованного теста предстанет в виде пучка векторов, плотно прилегающих к фактору и вытянувшихся вдоль его оси (рис. 9).

Рис. 9. Векторная модель соотношения «прямых» и «обратных» эмпирических пунктов с релевантным (измеряемым) фактором и иррелевантными («шумовыми») факторами
Последовательность действий при проверке надежности:
1. Узнать, существуют ли данные о надежности теста, предполагаемого к использованию, на какой популяции и в какой диагностической ситуации проводилась проверка. Если проверки не было или признаки новых популяции и ситуации явно специфичны, провести заново проверку надежности с учетом указанных ниже возможностей.
2. Произвести повторное тестирование на всей выборке стандартизации и подсчитать все коэффициенты, как для целого теста, так и для его отдельных пунктов. Анализ полученных коэффициентов позволит понять, насколько пренебрежима ошибка измерения, дает ли данный тест интервальную шкалу (высокий r) или только диагностичен для крайних групп (высокий φ), насколько устойчиво измеряемое свойство во времени (возможен ли статистический прогноз - проекция тестового балла на будущее), в каких своих пунктах тест менее надежен (анализ этих пунктов позволяет психологически осмыслить содержательный механизм взаимодействия пунктов с испытуемыми).
3. Если возможности обследования испытуемых ограниченны, произвести повторное тестирование только на части выборки (не менее 30 испытуемых), подсчитать (вручную) ранговую или четырех-клеточную корреляцию для оценки внутренней согласованности и стабильности теста в целом.
Дата добавления: 2015-07-11; просмотров: 76 | Нарушение авторских прав