|
Читайте также: |

2. Одной командой SELECT вывести полный список всех без исключения подразделений компании, включая сведения о местах их расположения:
1. Идентификатор подразделения компании
2. Название подразделения компании
3. Город, в котором расположено подразделение или N/A, если он неизвестен
4. Страна, в которой расположено подразделение или N/A, если она неизвестна
5. Фамилия руководителя подразделения компании или N/A, если он неизвестен
SELECT
DEPARTMENTS.DEPARTMENT_ID AS "ID",
DEPARTMENTS.DEPARTMENT_NAME AS "Название",
NVL(LOCATIONS.CITY, 'N/A') AS "Город",
NVL(COUNTRIES.COUNTRY_NAME, 'N/A') AS "Страна",
NVL(EMPLOYEES.LAST_NAME, 'N/A') AS "Руководитель"
FROM DEPARTMENTS LEFT JOIN LOCATIONS ON DEPARTMENTS.LOCATION_ID = LOCATIONS.LOCATION_ID
LEFT JOIN COUNTRIES ON LOCATIONS.COUNTRY_ID = COUNTRIES.COUNTRY_ID
LEFT JOIN EMPLOYEES ON DEPARTMENTS.MANAGER_ID = EMPLOYEES.EMPLOYEE_ID
ORDER BY DEPARTMENTS.DEPARTMENT_ID;

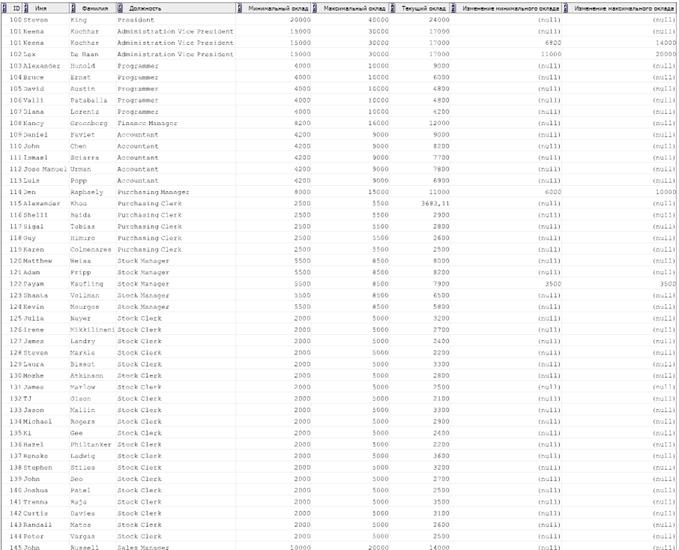
3. Одной командой SELECT вывести список сотрудников, упорядоченный по возрастанию по идентификатору сотрудника и содержащий следующие данные:
1. Идентификатор сотрудника
2. Имя сотрудника
3. Фамилия сотрудника
4. Название текущей должности
5. Минимальный оклад по текущей должности
6. Максимальный оклад по текущей должности
7. Текущий оклад
8. Изменение минимального должностного оклада при последней смене должности сотрудника, если произошло уменьшение, то выводить с минусом, если не было смены должности, то пустое значение (NULL)
9. Изменение максимального должностного оклада при последней смене должности сотрудника, если произошло уменьшение, то выводить с минусом, если не было смены должности, то пустое значение (NULL)
SELECT
E.EMPLOYEE_ID "ID",
E.FIRST_NAME "Имя",
E.LAST_NAME "Фамилия",
J.JOB_TITLE "Должность",
J.MIN_SALARY "Минимальный оклад",
J.MAX_SALARY "Максимальный оклад",
E.SALARY "Текущий оклад",
CASE WHEN J.JOB_ID!= JH.JOB_ID AND JH.START_DATE= MAX(JH.START_DATE) OVER (PARTITION BY JH.EMPLOYEE_ID) THEN J.MIN_SALARY - J1.MIN_SALARY ELSE NULL END "Изменение минимального оклада",
CASE WHEN J.JOB_ID!= JH.JOB_ID AND JH.START_DATE= MAX(JH.START_DATE) OVER (PARTITION BY JH.EMPLOYEE_ID) THEN J.MAX_SALARY - J1.MAX_SALARY ELSE NULL END "Изменение максимального оклада"
FROM EMPLOYEES E JOIN JOBS J ON E.JOB_ID = J.JOB_ID
LEFT JOIN JOB_HISTORY JH ON E.EMPLOYEE_ID = JH.EMPLOYEE_ID
LEFT JOIN JOBS J1 ON JH.JOB_ID = J1.JOB_ID
ORDER BY E.EMPLOYEE_ID;
4. Получить одной командой SELECT отчет, содержащий нижеследующую информацию по всем без исключения подразделениям компании, отсортированную по возрастанию по идентификатору подразделения компании:
1. Идентификатор подразделения компании
2. Название подразделения компании
3. Фамилия руководителя подразделения компании
4. Адрес места расположения подразделения компании
5. Город, где расположено подразделение компании
6. Штат, где расположено подразделение компании
7. Страна, где расположено подразделение компании
8. Регион, где расположено подразделение компании
9. Количество сотрудников, приписанных к подразделению компании
10. Количество различных должностей в подразделении компании
11. Количество записей об истории занятия должностей сотрудниками данного подразделения компании
SELECT DISTINCT
D.DEPARTMENT_ID "Dep id",
D.DEPARTMENT_NAME "Название",
E.LAST_NAME "Руководитель",
L.STREET_ADDRESS "Адрес",
L.CITY "Город",
L.STATE_PROVINCE "Штат",
C.COUNTRY_NAME "Страна",
R.REGION_NAME "Регион",
COUNT(E1.EMPLOYEE_ID) OVER (PARTITION BY D.DEPARTMENT_ID) "Количество сотрудников",
COUNT(DISTINCT E1.JOB_ID) OVER (PARTITION BY D.DEPARTMENT_ID) "Укальные должности",
COUNT(JH.EMPLOYEE_ID) OVER (PARTITION BY D.DEPARTMENT_ID) "Занятия должностей"
FROM DEPARTMENTS D LEFT JOIN EMPLOYEES E ON E.EMPLOYEE_ID = D.MANAGER_ID
LEFT JOIN LOCATIONS L ON D.LOCATION_ID = L.LOCATION_ID
LEFT JOIN COUNTRIES C ON L.COUNTRY_ID = C.COUNTRY_ID
LEFT JOIN REGIONS R ON C.REGION_ID = R.REGION_ID
LEFT JOIN JOB_HISTORY JH ON JH.DEPARTMENT_ID = D.DEPARTMENT_ID
LEFT JOIN EMPLOYEES E1 ON D.DEPARTMENT_ID = E1.DEPARTMENT_ID
ORDER BY D.DEPARTMENT_ID

5. Одной командой SELECT вывести таблицу, в которой отразить количество сотрудников в подразделениях компании с идентификаторами 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120 по годам, ориентируясь по значению в столбце hire_date (дата приёма на работу) в таблице сотрудников.
Строки таблицы должны соответствовать годам с 1987 по 2001 (всего 15 строк) и быть упорядоченными по году по возрастанию.
Столбцы:
1-й столбец - год,
2-й столбец - количество сотрудников, работавших в данном году в подразделении с идентификатором 10,
3-й столбец - количество сотрудников, работавших в данном году в подразделении с идентификатором 20,
4-й столбец - количество сотрудников, работавших в данном году в подразделении с идентификатором 30,
...
13-й столбец - количество сотрудников, работавших в данном году в подразделении с идентификатором 120.
SELECT
Y "YEAR",
SUM(CASE WHEN DEPARTMENT_ID = 10 THEN 1 ELSE 0 END) AS "10",
SUM(CASE WHEN DEPARTMENT_ID = 20 THEN 1 ELSE 0 END) AS "20",
SUM(CASE WHEN DEPARTMENT_ID = 30 THEN 1 ELSE 0 END) AS "30",
SUM(CASE WHEN DEPARTMENT_ID = 40 THEN 1 ELSE 0 END) AS "40",
SUM(CASE WHEN DEPARTMENT_ID = 50 THEN 1 ELSE 0 END) AS "50",
SUM(CASE WHEN DEPARTMENT_ID = 60 THEN 1 ELSE 0 END) AS "60",
SUM(CASE WHEN DEPARTMENT_ID = 70 THEN 1 ELSE 0 END) AS "70",
SUM(CASE WHEN DEPARTMENT_ID = 80 THEN 1 ELSE 0 END) AS "80",
SUM(CASE WHEN DEPARTMENT_ID = 90 THEN 1 ELSE 0 END) AS "90",
SUM(CASE WHEN DEPARTMENT_ID = 100 THEN 1 ELSE 0 END) AS "100",
SUM(CASE WHEN DEPARTMENT_ID = 110 THEN 1 ELSE 0 END) AS "110",
SUM(CASE WHEN DEPARTMENT_ID = 120 THEN 1 ELSE 0 END) AS "120"
FROM (SELECT 1986 + LEVEL Y FROM DUAL CONNECT BY LEVEL <= 2001 - 1986) LEFT JOIN EMPLOYEES ON Y=TO_CHAR(HIRE_DATE, 'YYYY')
GROUP BY Y
ORDER BY Y
6. Одной командой SELECT получить список руководителей подразделений компании, выведя следующие данные:
1. Идентификатор руководителя подразделения компании
2. Фамилия руководителя подразделения компании
3. Идентификатор подразделения компании, которым руководит данный руководитель
4. Название подразделения компании, которым руководит данный руководитель
5. Количество подчиненных данного руководителя (включая подчиненных второго, третьего и т.д. уровней)
6. Количество подчиненных данного руководителя (включая подчиненных второго, третьего и т.д. уровней), работающих в подразделении, которым руководит данный руководитель.
Записи упорядочить по возрастанию по идентификатору подразделения компании, указанному в п.3.
ВОЗМОЖНО, НЕВЕРНО
SELECT
E.EMPLOYEE_ID "Manager ID",
E.LAST_NAME "Last name",
D.DEPARTMENT_ID "Department ID",
D.DEPARTMENT_NAME "Department name",
(SELECT COUNT(*) FROM EMPLOYEES START WITH MANAGER_ID = D.MANAGER_ID CONNECT BY PRIOR MANAGER_ID = EMPLOYEE_ID) AS "Num of employees",
(SELECT COUNT(*) FROM EMPLOYEES WHERE D.MANAGER_ID = EMPLOYEE_ID START WITH MANAGER_ID = D.MANAGER_ID CONNECT BY PRIOR MANAGER_ID = EMPLOYEE_ID) AS "Num employees in dept"
FROM EMPLOYEES E JOIN DEPARTMENTS D ON D.MANAGER_ID = E.EMPLOYEE_ID ORDER BY D.DEPARTMENT_ID;
7. Одной командой SELECT вывести информацию по подразделениям компании, имеющим в названии больше одного слова:
1. Идентификатор подразделения
2. Второе слово в названии подразделения
Слова в названии подразделения разделяются пробелами.
Данные необходимо упорядочить по возрастанию по идентификаторам подразделений компании.
ВОЗМОЖНО, НЕВЕРНО
SELECT DEPARTMENT_ID AS "ID",
REGEXP_SUBSTR(DEPARTMENT_NAME,' [^ ]+', 1, 2) AS "Второе слово"
FROM DEPARTMENTS
WHERE INSTR(DEPARTMENT_NAME, ' ') > 0
ORDER BY DEPARTMENT_ID;

8. Одной командой SELECT вывести список сотрудников, у которых в фамилии или имени какая-либо буква повторяется трижды или более раз.
Вывести:
1. Идентификатор сотрудника
2. Фамилию сотрудника
3. Имя сотрудника
Упорядочить результат по идентификатору сотрудника по возрастанию.
SELECT
EMPLOYEE_ID "ID",
LAST_NAME "Фамилия",
FIRST_NAME "Имя"
FROM EMPLOYEES
WHERE
REGEXP_LIKE(LOWER(LAST_NAME),'([[:alpha:]]).*\1.*\1') OR REGEXP_LIKE(LOWER(FIRST_NAME), '([[:alpha:]]).*\1.*\1');
9. Одной командой SELECT вывести имена сотрудников
- встречающиеся в таблице сотрудников не менее трех раз
и
- не являющиеся именами руководителей подразделений компании или именами непосредственных руководителей кого-либо.
В результате:
- должны быть выведены только имена сотрудников
- каждое из отобранных имён должно быть выведено только один раз.
SELECT E.FIRST_NAME AS "Имя"
FROM EMPLOYEES E
LEFT JOIN EMPLOYEES E0 ON E0.MANAGER_ID = E.EMPLOYEE_ID
LEFT JOIN DEPARTMENTS D ON D.MANAGER_ID = E.EMPLOYEE_ID
WHERE (E0.EMPLOYEE_ID IS NULL) AND (D.DEPARTMENT_ID IS NULL)
GROUP BY E.FIRST_NAME
HAVING COUNT(E.FIRST_NAME) > 2;
10. Одной командой SELECT вывести список сотрудников компании, руководящих (прямо или опосредованно) одним единственным подчинённым.
В выводимом списке должны быть следующие столбцы:
1. Фамилия сотрудника-руководителя,
2. Должность сотрудника-руководителя,
3. Название подразделения компании, в котором работает сотрудник-руководитель,
4. Фамилия единственного сотрудника-подчиненного,
5. Должность единственного сотрудника-подчиненного.
Результат необходимо отсортировать:
1. По окладу сотрудника-руководителя (по возрастанию)
2. По идентификатору сотрудника-руководителя (по возрастанию)
SELECT
E1.LAST_NAME "Фамилия руководителя",
J0.JOB_TITLE "Должность руководителя",
D1.DEPARTMENT_NAME "Название подразделения",
E2.LAST_NAME "Фамилия подчиненного",
J1.JOB_TITLE "Должность подчиненного"
FROM EMPLOYEES E0 JOIN EMPLOYEES E1 ON (E0.MANAGER_ID = E1.EMPLOYEE_ID)
JOIN JOBS J0 ON (E1.JOB_ID = J0.JOB_ID)
JOIN DEPARTMENTS D1 ON (E1.DEPARTMENT_ID = D1.DEPARTMENT_ID)
JOIN EMPLOYEES E2 ON (E1.EMPLOYEE_ID = E2.MANAGER_ID)
JOIN JOBS J1 ON (E2.JOB_ID = J1.JOB_ID)
GROUP BY E1.LAST_NAME, J0.JOB_TITLE, D1.DEPARTMENT_NAME, E2.LAST_NAME, J1.JOB_TITLE, E1.SALARY, E1.EMPLOYEE_ID
HAVING COUNT(E0.MANAGER_ID) = 1
ORDER BY E1.SALARY, E1.EMPLOYEE_ID;
11. Проверить наличие циклов в таблице подчиненностей. Вывести циклические зависимости в строчку.
SELECT * FROM(SELECT LTRIM(SYS_CONNECT_BY_PATH(EMPLOYEES.MANAGER_ID,','),',')"Cycl", CONNECT_BY_ISCYCLE CYCL
FROM EMPLOYEES CONNECT BY NOCYCLE PRIOR EMPLOYEES.EMPLOYEE_ID = EMPLOYEES.MANAGER_ID)WHERE CYCL = 1;
12. Имеется таблица:
| Id | Linked_id | Part |
| -1 | Содержание | |
| Глава 1 | ||
| Часть 1 | ||
| Часть 2 | ||
| Глава 2 | ||
| Часть 1 | ||
| Часть 2 |
Получить результат в виде:
Оглавление
1 Глава 1
1.1 Часть 1
1.2 Часть 2
2 Глава 2
2.1 Часть 1
2.2 Часть 2
WITH
b AS (SELECT a.*, ROW_NUMBER() OVER(PARTITION BY Linked_id ORDER BY Part) RW FROM (
SELECT 0 Id, -1 Linked_id, 'Содержание' Part FROM dual
UNION ALL
SELECT 1 Id, 0 Linked_id, 'Глава 1' Part FROM dual
UNION ALL
SELECT 2 Id, 1 Linked_id, 'Часть 1' Part FROM dual
UNION ALL
SELECT 3 Id, 1 Linked_id, 'Часть 1' Part FROM dual
UNION ALL
SELECT 4 Id, 0 Linked_id, 'Глава 2' Part FROM dual
UNION ALL
SELECT 5 Id, 4 Linked_id, 'Часть 1' Part FROM dual
UNION ALL
SELECT 6 Id, 5 Linked_id, 'Часть 2' Part FROM dual) a)
SELECT LTRIM(LTRIM(LTRIM(SYS_CONNECT_BY_PATH(RW, '.'), '.'),'1'),'.') || ' ' || PART "Оглавление"
FROM b
START WITH Id = 0
CONNECT BY PRIOR Id = LINKED_ID;

13. Имеется таблица с тремя столбцами: именем, фамилией и коэффициентом повторения. Требуется написать запрос, выводящий таблицу, содержащую строки с именами и фамилиями сотрудников. Число строк для каждого сотрудника должно определяться коэффициентом повторения.
Строки должны быть объединены в группы и отсортированы по фамилии и имени.
Кроме того, должны быть пронумерованы элементы внутри группы и должна присутствовать сквозная нумерация.
CREATE TABLE P (FIRST_NAME VARCHAR2(30), LAST_NAME VARCHAR2(30), REP NUMBER(3));
INSERT INTO P VALUES ('XN', 'XF', 3);
INSERT INTO P VALUES ('XXN', 'XXF', 4);
INSERT INTO P VALUES ('XXXN', 'XXXF', 4);
INSERT INTO P VALUES ('XXXXN', 'XXXXN', 2);
SELECT rownum "#", G# "# in group", FIRST_NAME "First name", LAST_NAME "Last name"
FROM(
SELECT DISTINCT * FROM(
SELECT LEVEL G#, FIRST_NAME, LAST_NAME FROM P CONNECT BY LEVEL <= REP)
ORDER BY 2, 1);
14. Из заданных наборов символов вывести исключить те наборы символов, которые отличаются только порядком. Например, заданы наборы:
rtyew
trwye
rtgbfdsa
tgrbafsd
Результат:
rtyew
rtgbfdsa
15. Определить сумму чисел в произвольной символьной строке. Например, для строки fgh123hhh76 результат должен быть 199.
WITH T AS (SELECT 'FGH123HHH76' STR FROM DUAL)
SELECT SUM(REGEXP_SUBSTR(STR,'[0-9]+', 1, LVL)) AS "Sum" FROM(
SELECT LEVEL LVL, STR FROM T CONNECT BY LEVEL <= (SELECT LENGTH(STR) FROM T));
Sum
---
16. В произвольной строке, состоящей из символьных элементов, разделенных запятыми, отсортировать элементы по алфавиту. Например, символьную строку
abc,cde,ef,gh,mn,test,ss, df,fw,ewe,wwe
преобразовать к виду:
abc,cde,df,ef,ewe, fw,gh,mn,ss,test,wwe.
SELECT MAX(LTRIM(SYS_CONNECT_BY_PATH(STR, ','), ',')) "Str" FROM (
SELECT REGEXP_SUBSTR('ABC,CDE,EF,GH,MN,TEST,SS, DF,FW,EWE,WWE', '[A-Z]+', 1, LEVEL) STR FROM DUAL
CONNECT BY REGEXP_SUBSTR('ABC,CDE,EF,GH,MN,TEST,SS, DF,FW,EWE,WWE', '[A-Z]+', 1, LEVEL) IS NOT NULL ORDER BY STR);
Str
---------------------------
ABC,CDE,DF,EF,EWE,FW,GH,MN,SS,TEST,WWE
17. Вывести информацию о кафедрах, преподавателях и читаемых ими предметах в виде:
Кафедра 1
Сидоров
Математика
Физика
Смирнов
Химия
Кафедра 2……..
select lpad(r3,length(r3) + 3*level - 3,' ')
from(select distinct Кафедра r1, to_char(null) r2, to_char(кафедра) r3
from Преподаватели
union all
select to_char(Номер_преподавателя), Кафедра, to_char(Фамилия)
from Преподаватели
union all
select to_char(НОМЕР_ПРЕДМЕТА), to_char(Номер_преподавателя),Название
from ПРЕДМЕТ
where Номер_преподавателя is not null)
start with r2 is null
connect by prior r1 = r2;

18. Есть таблица с такой структурой
| Col1 | Col2 | Col3 |
| a | d | T |
| d | t | A |
| a | t | D |
| m | n | L |
| l | m | N |
Записи, которые могут быть получены из других записей перестановкой значений в столбцах, должны выводиться только один раз. В нашем случае ответ должен быть такой:
| Col1 | Col2 | Col3 |
| a | d | T |
| l | m | N |
SELECT "C0", "C1", "C2"
FROM (
SELECT c0,
c1,
c2,
row_number() over (partition by
LEAST(c0,c1,c2),
CASE
WHEN ((c0>=c1 AND c0<=c2) OR (c0 >=c2 AND c0 <=c1))
THEN c0
WHEN ((c1>=c0 AND c1<=c2) OR (c1>=c2 AND c1<=c0))
THEN c1
ELSE c2
END,
GREATEST(c0,c1,c2)
order by "C0") ns
FROM
(SELECT 'a' c0,'b' c1,'c' c2 FROM dual
UNION
SELECT 'b' c0,'a' c1,'c' c2 FROM dual
UNION
SELECT 'a' c0,'c' c1,'c' c2 FROM dual
UNION
SELECT 'a' c0,'a' c1,'c' c2 FROM dual
UNION
SELECT 'a' c0,'b' c1,'c' c2 FROM dual
UNION
SELECT 'b' c0,'a' c1,'c' c2 FROM dual
)t)t
where ns = 1
19. Создать запрос для получения информации об успеваемости студентов в виде:
| ФИО | Дисциплина | Оценка | Дата | Примечания |
| Петров | Математика | 20.1.2008 | ||
| Физика | 22.1.2008 | |||
| Химия | 25.1.2008 | |||
| Химия | 27.1.2008 | Пересдача | ||
| Усов | Математика | 12.06.99 | ||
| Экономика | 15.06.99 | |||
| Менеджмент | 17.06.99 | |||
| Менеджмент | 18.06.99 | Пересдача |
Задачу решить двумя способами:
а) с использованием аналитических функций;
б) без использования аналитических функций.

ВОЗМОЖНО, НЕВЕРНО
А)
SELECT
CASE WHEN RW = 1 THEN FAM ELSE NULL END "ФАМИЛИЯ",
ДИСЦИПЛИНА,
ОЦЕНКА,
ДАТА,
ПРИМЕЧАНИЯ
FROM (SELECT ФАМИЛИЯ FAM, ROW_NUMBER() OVER (PARTITION BY СТУДЕНТЫ.НОМЕР_СТУДЕНТА ORDER BY ФАМИЛИЯ) RW,
НАЗВАНИЕ ДИСЦИПЛИНА, ОЦЕНКА, ДАТА,
CASE WHEN ROW_NUMBER() OVER (PARTITION BY СТУДЕНТЫ.ФАМИЛИЯ, ПРЕДМЕТ.НАЗВАНИЕ ORDER BY СТУДЕНТЫ."НОМЕР_СТУДЕНТА") = 2 THEN 'ПЕРЕСДАЧА' ELSE TO_CHAR(NULL) END ПРИМЕЧАНИЯ
FROM СТУДЕНТЫ JOIN (SELECT * FROM УСПЕВАЕМОСТЬ ORDER BY ДАТА) X ON СТУДЕНТЫ."НОМЕР_СТУДЕНТА" = X."НОМЕР_СТУДЕНТА"
JOIN ПРЕДМЕТ ON X."НОМЕР_ПРЕДМЕТА" = ПРЕДМЕТ."НОМЕР_ПРЕДМЕТА");
-- во внутреннем запросе соединяю таблицы и вычисляю номера строк во внешнем далее отображаю фамилию только для первых строк
Б)
WITH A AS
(SELECT T.НОМЕР_СТУДЕНТА N, T.ДАТА D, T.ОЦЕНКА O, T.НОМЕР_ПРЕДМЕТА ND, COUNT (*) CNT1 FROM(
SELECT T.НОМЕР_СТУДЕНТА, T.ДАТА, T.ОЦЕНКА, T.НОМЕР_ПРЕДМЕТА FROM УСПЕВАЕМОСТЬ T
INNER JOIN УСПЕВАЕМОСТЬ T1 ON T.НОМЕР_СТУДЕНТА = T1.НОМЕР_СТУДЕНТА WHERE T.ДАТА >= T1.ДАТА) T
GROUP BY T.НОМЕР_СТУДЕНТА, T.ДАТА, T.ОЦЕНКА, T.НОМЕР_ПРЕДМЕТА
ORDER BY T.НОМЕР_СТУДЕНТА, T.ДАТА, T.НОМЕР_ПРЕДМЕТА),
B AS (
SELECT A1.N,A1.D,A1.O,A1.ND,A1.CNT1, COUNT(*) CNT2 FROM (
SELECT A1.N, A1.D, A1.O, A1.ND, A1.CNT1 FROM A A1
INNER JOIN A A2 ON A1.N = A2.N AND A1.ND = A2.ND WHERE A1.D >= A2.D) A1
GROUP BY A1.N, A1.D, A1.O, A1.ND, A1.CNT1
ORDER BY A1.N, A1.D, A1.O)
SELECT
(CASE WHEN B.CNT1 = 1 THEN C.ФАМИЛИЯ ELSE NULL END) "ФАМИЛИЯ",
D.НАЗВАНИЕ ДИСЦИПЛИНА, B.O "ОЦЕНКА", B.D "ДАТА",
(CASE WHEN B.CNT2 = 2 THEN 'ПЕРЕСДАЧА' ELSE NULL END) "ПРИМЕЧАНИЕ"
FROM (
B INNER JOIN СТУДЕНТЫ C ON B.N = C.НОМЕР_СТУДЕНТА) INNER JOIN ПРЕДМЕТ D ON B.ND = D.НОМЕР_ПРЕДМЕТА;
20. В таблицу записана информация, об удачных и неудачных попытках подключения к базе данных (Пользователь, Время, Удачно\Неудачно). Требуется получить список пользователей, которые совершили подряд три неудачные попытки подключения. После трех подряд неудачных попыток отсчет попыток начинается сначала. эта фраза вызывает у меня подозрения, что пользователей, которые несколько раз трижды предприняли неудачные попытки входа всё-таки хотят видеть в результате несколько раз
ВОЗМОЖНО, НЕВЕРНО
create table Connected
(USERS varchar2(30),
DATE_CONNECT date,
RESULT varchar(4));
commit;
insert into Connected values ('x', sysdate, 'fail');
insert into Connected values ('x', sysdate, 'fail');
insert into Connected values ('x', sysdate, 'ok');
insert into Connected values ('x', sysdate, 'fail');
insert into Connected values ('x', sysdate, 'fail');
insert into Connected values ('x', sysdate, 'ok');
insert into Connected values ('xx', sysdate, 'fail');
insert into Connected values ('xx', sysdate, 'fail');
insert into Connected values ('xx', sysdate, 'fail');
insert into Connected values ('xx', sysdate, 'fail');
insert into Connected values ('xx', sysdate, 'ok');
insert into Connected values ('xx', sysdate, 'fail');
insert into Connected values ('xx', sysdate, 'fail');
insert into Connected values ('xx', sysdate, 'fail');
insert into Connected values ('xxx', sysdate, 'fail');
insert into Connected values ('xxx', sysdate, 'fail');
insert into Connected values ('xxx', sysdate, 'fail');
insert into Connected values ('xxxx', sysdate, 'fail');
insert into Connected values ('xxxx', sysdate, 'fail');
insert into Connected values ('xxx', sysdate, 'ok');
insert into Connected values ('xxxx', sysdate, 'fail');
select distinct a.USERS
from (select USERS, DATE_CONNECT, RESULT, rownum r
from (select USERS, DATE_CONNECT, RESULT, rownum z from Connected
order by USERS, z) order by r) a
left join
(select USERS, DATE_CONNECT, RESULT, rownum r
from (select USERS, DATE_CONNECT, RESULT, rownum z from Connected
order by USERS, z) order by r) b
on a.USERS = b.USERS and a.r = b.r - 1
left join
(select USERS, DATE_CONNECT, RESULT, rownum r
from (select USERS, DATE_CONNECT, RESULT, rownum z from Connected
order by USERS, z) order by r) c
on a.USERS = c.USERS and a.r = c.r - 2
where a.RESULT = 'fail' and b.RESULT = 'fail' and c.RESULT = 'fail';
ВАРИАНТ 11
(Базы данных Студент и Human Resources)
1. Для двух заданных сотрудников найти их ближайшего общего начальника.
SELECT manager_id
FROM employees
WHERE manager_id IN
(
SELECT manager_id
FROM employees
START WITH employee_id=&employee1
CONNECT BY PRIOR manager_id=employee_id
) and rownum=1
START WITH employee_id=&employee2
CONNECT BY PRIOR manager_id=employee_id;
Результат для employee1 = 150 и employee2 = 200:

Комментарий:
Сначала находим всех начальников для превого заданного сотрудника,потом для второго, и выводим первое сходство. т.к. иерархия строится снизу в вверх.
2. Для заданного интервала лет вывести количество каждого дня недели в году.
WITH day_in_year AS
(
SELECT to_char(curdate, 'D') ds, to_char(curdate, 'DAY') d, curyear y
FROM (SELECT to_date(concat('01.01.','&&first_year')) + LEVEL - 1 curdate,
EXTRACT(YEAR FROM to_date(concat('01.01.', '&&first_year')) + LEVEL - 1) curyear
FROM dual
CONNECT BY LEVEL <= to_date(concat('31.12.','&&second_year')) - to_date(concat('01.01.','&&first_year')) + 1)
)
SELECT d "День недели", COUNT(d) "Количество", y "Год"
FROM day_in_year
GROUP BY y, d, ds
ORDER BY 3, ds;

Комментарий:
Выводим все числа и дни недели с начальной заданной даты, до конечной, а так же год для каждого дня недели. Для сортировки выводим номер для недели. Группируем по годам и по дням недели. Считаем по дням недели.
3. Имеется таблица с числовым столбцом. Требуется вывести те числа из заданного диапазона (скажем, от 1 до 5000), которых в таблице нет.
SELECT l
FROM(SELECT LEVEL l
FROM dual
CONNECT BY LEVEL <=5000)
WHERE l NOT IN (SELECT department_id FROM departments)
ORDER BY l;

…

Комментарий:
Тестировался запрос на столбце department_id из таблицы departments. Строим диапазон значений, выводим только те значения, которых в таблице нет.
4. Имеется таблица с двумя столбцами: id NUMBER(9) PRIMARY KEY и info VARCHAR2(80) NOT NULL
В поле INFO содержится текстовая информация, в которой слова отделены друг от друга произвольным количеством пробелов. Также произвольное количество пробелов может быть в начале и в конце данных, содержащихся в поле INFO.
Написать команду SELECT, выводящую числа из поля id и скорректированные данные поля INFO. При этом должны быть убраны начальные и хвостовые пробелы, а между всеми словами должно быть только по одному пробелу
Возрастающая сортировка должна быть выполнена по скорректированным данным поля INFO. Ограничения способа решения: Решение найти с использованием раздела MODEL.
Дата добавления: 2015-08-18; просмотров: 526 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Main_Table PK User_Constraints 7 страница | | | Main_Table PK User_Constraints 9 страница |