4 rows selected
Комментарий:
Решение с использованием раздела MODEL:
Создаем одномерный массив DIMENSION BY(1 n), имеет псевдоним n.
В блоке MEASURES используем CAST('' as VARCHAR2(4000)) для преобразования типов varchar2 c размером 4000(maximum length size bytes). И также measure по TRIM(info).
Так как trim(str2) – это текстовая информация от INFO, в которой не существует лишних пробелов, поэтому str2 имеет тип VARCHAR2 (тип пола INFO). В str2[1] добавляем очередное встретившее слово из str1[1] c одном пробелом. На самом деле, масимальный размер str2 можно равен 80*2 = 160 (так как str2[1]= str2[1]||' ' || + строк с размером не больше 80). Eсли меньше, иногда возникает такую ошибку:
Error report:
SQL Error: ORA-25137: Data value out of range
*Cause: Value from cast operand is larger than cast target size.
В блоке RULES используем ITERATE(80), это значит цикл выполнится 80 раз, так как максимальный размер строка Info равно 80. На каждой итерации цикла мы изменяем значения str1, str2, и убираем лишные пробели c использованием таких функциях SUBSTR(), INSTR(), TRIM().
Сортируем результаты по скорректированным данным поля INFO (order by 2).
5. Создать запрос для вывода списка дисциплин, по которым на сессии было получено максимальное количество пятерок.
--Вариант 1
SELECT номер_дисциплины, название
FROM успеваемость JOIN дисциплины USING (номер_дисциплины)
WHERE оценка = 5
GROUP BY номер_дисциплины, название
HAVING COUNT(*) = (SELECT MAX(COUNT(*))
FROM успеваемость
WHERE оценка = 5
GROUP BY номер_дисциплины);
--Вариант 2
WITH
alias_tables AS
(SELECT номер_дисциплины, COUNT(*) count_5
FROM успеваемость
WHERE оценка = 5
GROUP BY номер_дисциплины)
SELECT номер_дисциплины, название
FROM дисциплины JOIN alias_tables USING (номер_дисциплины)
WHERE count_5 = (SELECT MAX(count_5) FROM alias_tables);
Результат:
НОМЕР_ДИСЦИПЛИНЫ НАЗВАНИЕ
---------------------- ------------------------------
2003 Математика
1 rows selected
Комментарий:
Таблица успеваемости была объединена с таблицей дисциплины по номеру дисциплины, и в эотм отбираем строки, в которые экзамены сдали на 5. Затем, в предложении HAVING подсчитывается максимальный количества пятерок группируем по номеру дисциплины от таблицы успеваемости.
6. Есть таблица с парами значений, связанными отношением. Одно значение может быть связано с несколькими, те в свою очередь могут быть связаны друг с другом. В результате, значения транзитивно образуют связанные множества. На входе имеем некое значение, нужно получить все элементы множества, к которому оно относится. Результат вывести в виде строки с запятой в качестве разделителя.
CREATE TABLE graphs (node_from NUMBER(1), node_to NUMBER(1));
INSERT INTO graphs VALUES (1, 2);
INSERT INTO graphs VALUES (1, 3);
INSERT INTO graphs VALUES (2, 4);
INSERT INTO graphs VALUES (2, 5);
INSERT INTO graphs VALUES (3, 6);
INSERT INTO graphs VALUES (7, 8);
INSERT INTO graphs VALUES (7, 9);
INSERT INTO graphs VALUES (8, 9);
UNDEF node_peak;
WITH
two_ways_graphs AS (
SELECT node_from, node_to FROM graphs
UNION
SELECT node_to, node_from FROM graphs),
result_tables AS (SELECT DISTINCT node_from
FROM two_ways_graphs
WHERE node_from <> &&node_peak
START WITH node_from = &node_peak
CONNECT BY NOCYCLE PRIOR node_from = node_to)
SELECT SUBSTR (SYS_CONNECT_BY_PATH (node_from, ','), 2) res
FROM (SELECT node_from,
ROW_NUMBER () OVER (ORDER BY node_from) rn
FROM result_tables)
where rn = (select count(*) from result_tables)
START WITH rn = 1
CONNECT BY rn = PRIOR rn + 1;
/* для converting multiple rows to sing row with comma, мы также имеем функции
SELECT wm_concat(node_from) res
FROM result_tables;*/
Результат:
Если node_peak=2, то:
RES
-----------------------------
1,3,4,5,6
1 rows selected
Если node_peak=8, то:
RES
------------------------------------------------------------
7,9
1 rows selected
Комментарий:
Строим таблицу graphs со 2 парами значений, связанными отношением node_from, node_to
CREATE TABLE graphs (node_from NUMBER(1), node_to NUMBER(1));
Для того, чтобы одно значение может быть связано с несколькими, те в свою очередь могут быть связаны друг с другом. Созадаем связанные множества, можно представить в виде направленных графов.



 1 7
1 7


 2 3 8 9
2 3 8 9
4 5 6
Сначала создаются вспомогательные таблицы с помощью предложения WITH.
Таблица two_ways_graphs – Вывод связанные отношении node_from, node_to друг с другом
Таблица result_tables: на входе имеем некое значение, на выходе получить все элементы множества, к которому оно относится. Для того, с использованием иерархии зависимостей снизу вверх без цикли (CONNECT BY NOCYCLE PRIOR node_from = node_to), начиная с заданным значением (START WITH node_from = &node_peak). При этом, не выводим сам заданное значение.
Осталось выполнить основной запрос, который вывести в виде строки с запятой в качестве разделителя, мы строит иерархию сверху вниз CONNECT BY rn = PRIOR rn + 1, где rn – это ROW_NUMBER () OVER (ORDER BY node_from), и c помощью функцией SUBSTR (SYS_CONNECT_BY_PATH (node_from, ','), 2), поставим запитой между node_from. У нас есть такая функция wm_concat (для converting multiple rows to sing row with comma), может ли использовать вместо иерархию?
SELECT wm_concat(node_from) res
FROM result_tables;
7. Имеется таблица с тремя столбцами: именем, фамилией и коэффициентом размножения. Требуется написать запрос, выводящий таблицу, содержащую строки с именами и фамилиями двух сотрудников. Число строк для каждого сотрудника должно определяться коэффициентом размножения. То есть, если Иван Петров имел коэффициент размножения 3, а Сергей Сидоров – коэффициент размножения 5, то в результатах запроса должны быть 3 строки для сотрудника Петрова и 5 строк для Сидорова.
Строки должны быть объединены в группы и отсортированы по фамилии и имени.
Кроме того, должны быть пронумерованы элементы внутри группы и должна присутствовать сквозная нумерация. Этот запрос должен работать для произвольного количества строк в исходной таблице.
Пример выходного отчёта:
| Сквозной № | № в группе | Имя | Фамилия |
| Иван | Петров | ||
| Иван | Петров | ||
| Иван | Петров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров | ||
| Сергей | Сидоров |
CREATE TABLE factors
(first_name VARCHAR2(20), last_name VARCHAR2(20), multi_factor NUMBER(2));
INSERT INTO factors VALUES ('Иван', 'Петров', 3);
INSERT INTO factors VALUES ('Сергей', 'Сидоров', 5);
INSERT INTO factors VALUES ('Николай ', 'Аршавин', 4);
SELECT ROWNUM "Сквозной №", row2 "№ в группе", first_name "Имя", last_name "Фамилия"
FROM
(SELECT row1, row2, first_name, last_name
FROM (SELECT ROWNUM row1, first_name, last_name, multi_factor
FROM factors) num_factors
JOIN
(SELECT rownum row2
FROM all_objects
WHERE ROWNUM <= (SELECT MAX(multi_factor) FROM factors)) row_nums
ON num_factors.multi_factor>=row_nums.row2
ORDER by 4,3,2);
Результат:
Сквозной № № в группе Имя Фамилия
---------------------- ---------------------- -------------------- --------------------
1 1 Николай Аршавин
2 2 Николай Аршавин
3 3 Николай Аршавин
4 4 Николай Аршавин
5 1 Иван Петров
6 2 Иван Петров
7 3 Иван Петров
8 1 Сергей Сидоров
9 2 Сергей Сидоров
10 3 Сергей Сидоров
11 4 Сергей Сидоров
12 5 Сергей Сидоров
12 rows selected
Комментарий:
Сначала создаем таблицу с тремя столбцами: именем (first_name), фамилией(last_name) и коэффициентом размножения(multi_factor).
CREATE TABLE factors
(first_name VARCHAR2(20), last_name VARCHAR2(20), multi_factor NUMBER(2));
С помощью rownum и таблицы all_objects, строится подзапроса row_nums - последовательность натуральных чисел, начиная с 1 и заканчивая максимальным значением фактора MAX(multi_factor).
Таблица num_factors соединяются с таблицой row_nums с помощью операции JOIN по условию ON num_factors.multi_factor>=row_nums.row2. И зачем добавить сквозную нумерацию и сортирем по фамилии и имени (ORDER by 4,3,2).
8. Создать запрос для вывода списка фамилий студентов, которые не сдали ни одного экзамена в сессию, т.е. они могли делать попытки, но эти попытки были неудачными.
SELECT фамилия
FROM студенты
WHERE номер_студента NOT IN (SELECT DISTINCT номер_студента
FROM студенты JOIN группы USING (номер_группы)
JOIN учебные_планы USING (код_специальности)
WHERE (номер_студента,номер_дисциплины) IN
(select номер_
успеваемость WHERE оценка > 2));
Результат:
Устинов
Улиткин
Ежов
5 rows selected
9. Используя обращение только к таблице DUAL, построить SQL-запрос, возвращающий один столбец, содержащий календарь на текущий месяц текущего года:
номер дня в месяце (две цифры),
полное название месяца по-английски заглавными буквами (в верхнем регистре),
год (четыре цифры),
полное название дня недели по-английски строчными буквами (в нижнем регистре).
Каждое "подполе" должно быть отделено от следующего одним пробелом. В результате не должно быть начальных и хвостовых пробелов. Количество возвращаемых строк должно точно соответствовать количеству дней в текущем месяце. Строки должны быть упорядочены по номерам дней в месяце по возрастанию.
--решение 1
WITH tbl_dates AS
(SELECT TRUNC(SYSDATE,'month') + LEVEL-1 variant_day
FROM Dual
Connect By Level <= To_char(Last_day(Sysdate),'dd'))
Select TO_CHAR(variant_day,'DD fmMONTH yyyy day','NLS_DATE_LANGUAGE=ENGLISH')
As "Format current Days"
From Tbl_dates;
--решение 2
WITH tbl_dates AS
(SELECT to_char(variant_day,'DD MONTH YYYY day','NLS_DATE_LANGUAGE = ENGLISH') day_of_current_month
FROM (SELECT TRUNC(SYSDATE,'month') + LEVEL-1 variant_day
From Dual
Connect By Level <= Last_day(Sysdate) - Trunc(Sysdate,'MM')+1))
SELECT REGEXP_REPLACE(day_of_current_month,'(){2,}', ' ') format_days
From Tbl_dates;
Результат:
Format current Days
---------------------------
01 JUNE 2012 friday
02 JUNE 2012 saturday
03 JUNE 2012 sunday
04 JUNE 2012 monday
05 JUNE 2012 tuesday
06 JUNE 2012 wednesday
07 JUNE 2012 thursday
08 JUNE 2012 friday
09 JUNE 2012 saturday
10 JUNE 2012 sunday
11 JUNE 2012 monday
12 JUNE 2012 tuesday
13 JUNE 2012 wednesday
14 JUNE 2012 thursday
15 JUNE 2012 friday
16 JUNE 2012 saturday
17 JUNE 2012 sunday
18 JUNE 2012 monday
19 JUNE 2012 tuesday
20 JUNE 2012 wednesday
21 JUNE 2012 thursday
22 JUNE 2012 friday
23 JUNE 2012 saturday
24 JUNE 2012 sunday
25 JUNE 2012 monday
26 JUNE 2012 tuesday
27 JUNE 2012 wednesday
28 JUNE 2012 thursday
29 JUNE 2012 friday
30 JUNE 2012 saturday
30 rows selected
Комментарий:
Сначала создается вспомогательная таблица tbl_dates(пользуемся иерархией)– вывод столбца, содержащий календарь на текущий месяц текущего года: номер дня в месяце (две цифры), полное название месяца по-английски заглавными буквами (в верхнем регистре), год (четыре цифры), полное название дня недели по-английски строчными буквами (в нижнем регистре)
to_char(variant_day,'DD MONTH YYYY day','NLS_DATE_LANGUAGE = ENGLISH')
Далее, удаления лишних пробелов с использованием функция Replace
TO_CHAR(variant_day,'DD fmMONTH yyyy day','NLS_DATE_LANGUAGE=ENGLISH')
или REGEXP_REPLACE(day_of_current_month,'(){2,}', ' ')
10. Создать запрос для вывода списка фамилий студентов-хвостистов с указанием дисциплин, которые им необходимо еще досдать в данную сессию.
--Решение 1:
WITH alias_tab AS
(SELECT номер_студента, номер_дисциплины
FROM студенты JOIN группы USING (номер_группы)
JOIN учебные_планы USING (код_специальности)
MINUS
SELECT номер_студента, номер_дисциплины
FROM успеваемость
WHERE оценка > 2)
SELECT фамилия, название
FROM alias_tab JOIN студенты USING (номер_студента)
JOIN дисциплины USING (номер_дисциплины);
--Решение 2:
SELECT фамилия, название
FROM
(SELECT номер_студента, номер_дисциплины
FROM студенты JOIN группы USING (номер_группы)
JOIN учебные_планы USING (код_специальности)
MINUS
SELECT номер_студента, номер_дисциплины
FROM успеваемость
WHERE оценка > 2) alias_tab
JOIN студенты USING (номер_студента)
JOIN дисциплины USING (номер_дисциплины);
--Решение 3:
SELECT фамилия, название
FROM
(SELECT номер_студента, номер_дисциплины
FROM студенты JOIN группы USING (номер_группы)
JOIN учебные_планы USING (код_специальности)
WHERE
(номер_студента,номер_дисциплины) NOT IN
(select номер_студента, номер_дисциплины
FROM успеваемость
WHERE оценка > 2)) alias_tab
JOIN студенты USING (номер_студента)
JOIN дисциплины USING (номер_дисциплины);
Результат:
ФАМИЛИЯ НАЗВАНИЕ
--------------- ------------------------------
Гриценко Математика
Гриценко Физика
Котенко Математика
Котенко Физика
Нагорный Физика
Устинов Менеджмент
Устинов Экономика
Устинов Математика
Улиткин Менеджмент
Улиткин Экономика
Улиткин Математика
Ежов Менеджмент
Ежов Экономика
Ежов Математика
14 rows selected
11. Создать запрос для вывода списка фамилий студентов с указанием количества несданных ими в сессию дисциплин.
SELECT фамилия, count(номер_дисциплины) "Kоличества несданных дисциплин"
FROM
(SELECT номер_студента, номер_дисциплины
FROM студенты JOIN группы USING (номер_группы)
JOIN учебные_планы USING (код_специальности)
WHERE (номер_студента,номер_дисциплины) NOT IN
(select номер_студента, номер_дисциплины
FROM успеваемость
WHERE оценка > 2)) alias_tab
JOIN студенты USING (номер_студента)
JOIN дисциплины USING (номер_дисциплины)
GROUP BY фамилия;
Результат:
ФАМИЛИЯ Kоличества несданных дисциплин
--------------- ------------------------------
Ежов 3
Нагорный 1
Устинов 3
Гриценко 2
Улиткин 3
Котенко 2
6 rows selected
Комментарий:
Из множества студентов и дисциплин, которые они должны сдать, отбираем тех студентов с теми дисциплинами, которые они не сдали, или сдали но получили неудовлетворенную оценку. Результат сохранит в подзапросе alias_tab.
С использованием Count(номер_дисциплины) от alias_tab будет указать количество несданных ими в сессию дисциплин.
12. Создать запрос для вывода списка названий специальностей, по которым учится максимальное количество групп.
SELECT название_специальности
FROM
(SELECT код_специальности, название_специальности, COUNT(*) кол_групп
FROM группы JOIN специальности USING(код_специальности)
GROUP BY код_специальности, название_специальности
HAVING COUNT(*)=(SELECT MAX(COUNT(*))
FROM группы
GROUP BY код_специальности));
Результат:
НАЗВАНИЕ_СПЕЦИАЛЬНОСТИ
----------------------------------------
СИСТЕМЫ АВТОМАТИЧЕСКОГО УПРАВЛЕНИЯ
ЭКОНОМИКА ПРЕДПРИЯТИЙ
2 rows selected
Комментарий:
Сначала объединяем таблицы группы и специальности по столбцу код_специальности и считаем количество групп для данной специальности, группируем по специальностям.
Из этого результата отбираем специальности (HAVING), у которых есть количество групп равно максимальное количество групп от таблицы групп по специальности.
13. Создать запрос для вывода списка групп, в которых нет должников.
SELECT номер_группы
FROM группы
WHERE номер_группы NOT IN (
SELECT DISTINCT номер_группы
FROM студенты JOIN группы USING (номер_группы)
JOIN учебные_планы USING (код_специальности)
WHERE (номер_студента,номер_дисциплины) NOT IN
(SELECT номер_студента, номер_дисциплины
FROM успеваемость
WHERE оценка > 2))
Результат:
НОМЕР_ГРУППЫ
---------------
0 rows selected
Нет групп, в которых нет должников
Комментарий:
Сначала из множества студентов и дисциплин, которые они должны сдать, считаем тех студентов с теми дисциплинами, которые они не сдали, или сдали но получили неудовлетворенную оценку. Построим подзапрос из этого результата с группыми, в которых учатся эти студенты (должники). Далее выводим только списка групп от таблицы группы, в которых номер_группы нет находятся в этом подзапросе.
14. Создать запрос для получения информации о группах:
| Группа | Кол-во студентов | Название Специальности | Кол-во круглых отличников | Кол-во должников |
| …… |
WITH
students_discipline AS
(SELECT номер_группы, номер_студента stud, номер_дисциплины discp
FROM студенты JOIN группы USING (номер_группы)
JOIN учебные_планы USING(код_специальности)
),
dolzhnikov AS(
SELECT номер_группы, COUNT(*) cnt_dolz
FROM(SELECT DISTINCT номер_группы,stud
FROM students_discipline
WHERE (stud, discp) NOT IN
(SELECT номер_студента, номер_дисциплины
FROM успеваемость
WHERE оценка > 2))
GROUP BY номер_группы
),
excellents AS(
SELECT номер_группы, COUNT(номер_студента) cnt_excell
FROM студенты
WHERE номер_студента NOT IN
(SELECT DISTINCT stud
FROM students_discipline
WHERE (stud, discp) NOT IN
(SELECT номер_студента, номер_дисциплины
FROM успеваемость
WHERE оценка = 5))
GROUP BY номер_группы
)
SELECT номер_группы "группа", COUNT(*) "кол-во студентов"
, название_специальности "название cпециальности"
, NVL(cnt_excell, 0) "кол-во круглых отличников", NVL(cnt_dolz,0) "кол-во должников"
FROM студенты JOIN группы using (номер_группы)
JOIN специальности USING(код_специальности)
LEFT JOIN dolzhnikov USING (номер_группы)
LEFT JOIN excellents USING (номер_группы)
GROUP BY номер_группы, название_специальности, NVL(cnt_excell,0), NVL(cnt_dolz,0)
ORDER BY 1;
Результат:
Группа Кол-во студентов Название Cпециальности Кол-во круглых отличников Кол-во должников
--------------- ---------------------- ---------------------------------------- ------------------------- ----------------------
121 3 СИСТЕМЫ АВТОМАТИЧЕСКОГО УПРАВЛЕНИЯ 1 1
122 2 СИСТЕМЫ АВТОМАТИЧЕСКОГО УПРАВЛЕНИЯ 0 2
123 2 ЭКОНОМИКА ПРЕДПРИЯТИЙ 0 1
124 2 ЭКОНОМИКА ПРЕДПРИЯТИЙ 0 2
4 rows selected
Комментарий:
Сначала создается вспомогательные таблицы:
- Таблица students_discipline - множества студентов и дисциплин, которые они должны сдать
- Таблица dolzhnikov - множества номер_групп с количеством их должников
- Таблица excellents - множества номер_групп с количеством их круглых отличников
Осталось выполнить основной запрос: Все перечисленные таблицы (количество_студентов, должники, круглые_отличники) соединяются с таблицей группы по столбцу номер_группы.
15. Создать три таблицы Системы Автоматического Управления, Математическое Обеспечение ЭВМ, Вычислительные Сети и Системы. Используя возможности многотабличной вставки, записать в эти таблицы информацию о студентах в соответствии со специальностью, на которой они учатся.
CREATE TABLE сист_авто_упр
AS (SELECT * FROM студенты WHERE 1=2);
CREATE TABLE мат_обес_эвм
AS (SELECT * FROM студенты WHERE 1=2);
CREATE TABLE выч_сети_и_сист
AS (SELECT * FROM студенты WHERE 1=2);
INSERT FIRST
WHEN название_специальности = 'СИСТЕМЫ АВТОМАТИЧЕСКОГО УПРАВЛЕНИЯ' THEN
INTO сист_авто_упр VALUES (номер_студента,фамилия, имя, отчество, стипендия, номер_группы)
WHEN название_специальности = 'МАТЕМАТИЧЕСКОЕ ОБЕСПЕЧЕНИЕ ЭВМ' THEN
INTO мат_обес_эвм VALUES (номер_студента, фамилия, имя, отчество, стипендия, номер_группы)
WHEN название_специальности = 'ВЫЧИСЛИТЕЛЬНЫЕ СЕТИ И СИСТЕМЫ' THEN
INTO выч_сети_и_сист VALUES (номер_студента,фамилия,имя,отчество,стипендия, номер_группы)
SELECT номер_студента, фамилия, имя, отчество, стипендия, номер_группы, название_специальности
FROM студенты JOIN группы using(номер_группы)
JOIN специальности using(код_специальности);
Результат:
SELECT * FROM СИСТ_АВТО_УПР;
НОМЕР_СТУДЕНТА ФАМИЛИЯ ИМЯ ОТЧЕСТВО СТИПЕНДИЯ НОМЕР_ГРУППЫ
---------------------- --------------- --------------- --------------- ---------------------- ---------------
3412 Поляков Анатолий Алексеевич 200 121
3413 Старова Любовь Михайловна 250 121
3414 Гриценко Владимир Николаевич 300 121
3415 Котенко Анатолий Николаевич 0 122
3416 Нагорный Евгений Васильевич 200 122
5 rows selected
SELECT * FROM МАТ_ОБЕС_ЭВМ;
НОМЕР_СТУДЕНТА ФАМИЛИЯ ИМЯ ОТЧЕСТВО СТИПЕНДИЯ НОМЕР_ГРУППЫ
---------------------- --------------- --------------- --------------- ---------------------- ---------------
0 rows selected
SELECT * FROM ВЫЧ_СЕТИ_И_СИСТ;
НОМЕР_СТУДЕНТА ФАМИЛИЯ ИМЯ ОТЧЕСТВО СТИПЕНДИЯ НОМЕР_ГРУППЫ
---------------------- --------------- --------------- --------------- ---------------------- ---------------
0 rows selected
Комментарий:
Сначала Создаем три таблицы сист_авто_упр, мат_обес_эвм, выч_сети_и_сист с структурой, как и таблица студенты.
Далее используем многотабличной вставки с предложением FIRST для заполния эти таблицы информацией о студентах, которые учатся на соответствующей специальности.
16. Создать представление для получения информации по специальностям: Средняя оценка среди студентов специальности, сдавших экзамены; Количество студентов специальности, сдавших экзамены, Общее количество студентов на специальности.
CREATE VIEW инф_по_спец (название_специальности, ср_оценк_ср_студ,
кол_сдавших_студ, кол_студентов) AS
SELECT название_специальности, ср_оценк_ср_студ, кол_сдавших_студ, кол_студентов
FROM
(SELECT код_специальности, название_специальности, COUNT(номер_студента) кол_студентов
FROM студенты JOIN группы USING (номер_группы)
JOIN специальности USING (код_специальности)
GROUP BY код_специальности, название_специальности) --подзапрос 1
JOIN
(SELECT код_специальности, ROUND(AVG(оценка), 2) ср_оценк_ср_студ,
COUNT(DISTINCT Номер_студента) Кол_сдавших_студ
FROM Успеваемость
JOIN
(SELECT номер_студента, номер_дисциплины, MAX(дата) дата
FROM успеваемость
Where номер_студента NOT IN
(SELECT DISTINCT номер_студента
FROM студенты JOIN группы USING (номер_группы)
JOIN учебные_планы USING (код_специальности)
WHERE (номер_студента, номер_дисциплины) NOT IN
(SELECT номер_студента, номер_дисциплины
FROM успеваемость
Where Оценка >= 3))
GROUP BY Номер_студента, Номер_дисциплины)
USING (Номер_студента,Номер_дисциплины,Дата)
JOIN студенты USING (Номер_студента)
JOIN группы USING (номер_группы)
GROUP BY код_специальности)--подзапрос 2
USING(Код_специальности);
Результат:
select * from инф_по_спец
НАЗВАНИЕ_СПЕЦИАЛЬНОСТИ...СР_ОЦЕНК_СР_СТУД...КОЛ_СДАВШИХ_СТУД КОЛ_СТУДЕНТОВ
---------------------------------------- ---------------------- ---------------------- ----------------------
СИСТЕМЫ АВТОМАТИЧЕСКОГО УПРАВЛЕНИЯ 4.75 2 5
ЭКОНОМИКА ПРЕДПРИЯТИЙ 4 1 4
2 rows selected
Комментарий:
Создаем представление «инф_по_спец» со столбцами название_специальности (название специальности), ср_оценк_ср_студ (cредняя оценка среди студентов специальности, сдавших экзамены), кол_сдавших_студ (kоличество студентов специальности, сдавших экзамены), кол_студентов (oбщее количество студентов на специальности) с помощью CREATE VIEW.
Перый подзапрос содержит информацию о количестве студентов на специальности.
Второй подзапрос содержит информацию о средней оценке среди студентов специальности, сдавших экзамены, и о количестве студентов специальности, сдавших экзамены. Для этого строим множество всех студентов, которые не сдали все объятельные экзамены
(SELECT DISTINCT номер_студента
FROM студенты JOIN группы USING (номер_группы)
JOIN учебные_планы USING (код_специальности)
WHERE (номер_студента, номер_дисциплины) NOT IN
(SELECT номер_студента, номер_дисциплины
FROM успеваемость
WHERE оценка >= 3))
Далее, Отбираем последний день сдал или пересдал экзамен для каждого студентов, сдавших экзамены, с им номером дисциплины
SELECT номер_студента, номер_дисциплины, MAX(дата) дата
FROM успеваемость
Where номер_студента NOT IN
(SELECT DISTINCT номер_студента
FROM студенты JOIN группы USING (номер_группы)
JOIN учебные_планы USING (код_специальности)
WHERE (номер_студента, номер_дисциплины) NOT IN
(SELECT номер_студента, номер_дисциплины
FROM успеваемость
Where Оценка >= 3))
GROUP BY Номер_студента, Номер_дисциплины
Далее, соединяется с “успеваемость” USING (Номер_студента,Номер_дисциплины,Дата)
Затем определяется cредняя оценка среди студентов специальности ROUND(AVG(оценка), 2) и количество студентов специальности, сдавших экзамены, COUNT(DISTINCT номер_студента). DISTINCT необходимо, так как студенты в каждой группе может иметь несколько записей о разных экзаменах.
Подзапрос 1 соединяется с подзапросом 2 по коду специальности (USING(код_специальности))
17. Увеличить вдвое стипендию студентам, которые сдали все предусмотренные учебным планом для их специальности экзамены с первого раза на отлично.
UPDATE студенты
SET стипендия = стипендия*2
WHERE номер_студента NOT IN
(SELECT DISTINCT номер_студента /*Студенты, которые не пытались сдавать хотя бы один экзамен */
FROM студенты JOIN группы USING (номер_группы)
JOIN учебные_планы USING (код_специальности)
WHERE (номер_студента, номер_дисциплины) NOT IN (
SELECT номер_студента, номер_дисциплины
FROM успеваемость)
UNION /*Студенты, которые хотя бы один сдавали на оценку, <5 и не с первого раза на отлично */
SELECT DISTINCT номер_студента
FROM успеваемость
WHERE оценка < 5);
Результат:
| Before “Update” | After “Update” |

| 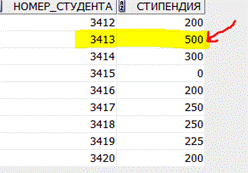
|
Комментарий:
Cначала строим подзапро: множество номеров студентов, которые с первого раза все сдали на отлично.
Увеличим вдвое стипендию (SET стипендия = стипендия*2) студентам, которые сдали все предусмотренные учебным планом для их специальности экзамены с первого раза на отлично(в раздел WHERE).
18. Создать запрос для определения среднего интервала между датами сдачи экзаменов для каждого студента.
WITH
tbl_order_dates AS
(SELECT номер_студента,дата
FROM успеваемость
ORDER BY номер_студента,дата),
tbl_diff_dates AS
(SELECT номер_студента
,дата - LAG(дата) OVER(PARTITION BY номер_студента ORDER BY дата) diff_date
FROM tbl_order_dates),
tbl_avg_diff_dates AS
(SELECT номер_студента, TO_CHAR(AVG(diff_date)) avg_diff_date
FROM tbl_diff_dates
WHERE diff_date IS NOT NULL
GROUP BY номер_студента)
SELECT номер_студента, avg_diff_date
FROM tbl_avg_diff_dates
UNION
SELECT номер_студента, 'ничего не сдавал или сдавал только 1 экзамен'
FROM студенты
WHERE номер_студента NOT IN (SELECT номер_студента FROM tbl_avg_diff_dates)
Результат:
НОМЕР_СТУДЕНТА AVG_DIFF_DATE
---------------------- --------------------------------------------
3412 2
3413 2
3414 5
3415 ничего не сдавал или сдавал только 1 экзамен
3416 ничего не сдавал или сдавал только 1 экзамен
3417 ничего не сдавал или сдавал только 1 экзамен
3418 3
3419 ничего не сдавал или сдавал только 1 экзамен
3420 ничего не сдавал или сдавал только 1 экзамен
9 rows selected
Комментарий:
Сначала создается вспомогательный таблицы:
tbl_order_dates: Вывод список студентов и дата из успеваемость, и сортируем по порядке номер_студента,дата
tbl_diff_dates: Вывод список студентов и разность между соседними экзаменами для одного студента.
дата - LAG(дата) OVER(PARTITION BY номер_студента ORDER BY дата) diff_date
Результат возращает ‘NULL’ для записей первого экзамена или сдавал только одни экзамен
tbl_avg_diff_dates: Вывод список студентов и среднего интервала AVG(diff_date) между датами сдачи экзаменов для студенты, который сдавал более один экзамен (WHERE diff_date IS NOT NULL)
Далее, определит все студенты, которые ничего не сдавал или сдавал только один экзамен:
SELECT номер_студента, 'ничего не сдавал или сдавал только 1 экзамен'
FROM студенты
Where Номер_студента Not In (Select Номер_студента From Tbl_avg_diff_dates)
И с помощью UNION мы получим результат, вывод среднего интервала между датами сдачи экзаменов для каждого студента.
19. Создать запрос, который позволит получить информацию о таблицах схемы HR в виде:
| Главная таблица | Столбец первичного ключа | Подчиненная таблица | Столбец вторичного ключа |
WITH HR_tables AS (SELECT *
FROM all_constraints JOIN all_cons_columns
USING (owner, table_name, constraint_name)
WHERE owner = 'HR')
SELECT Primary_HR_tables.table_name "Главная таблица",
Primary_HR_tables.column_name "Столбец первичного ключа",
HR_tables.table_name "Подчиненная таблица",
HR_tables.column_name "Столбец вторичного ключа"
FROM (SELECT *
FROM HR_tables
WHERE constraint_type = 'P') Primary_HR_tables
LEFT JOIN HR_tables
ON HR_tables.r_constraint_name = Primary_HR_tables.constraint_name
AND Hr_tables.Position = Primary_hr_tables.Position
ORDER BY 1,2,3,4;
Результат:
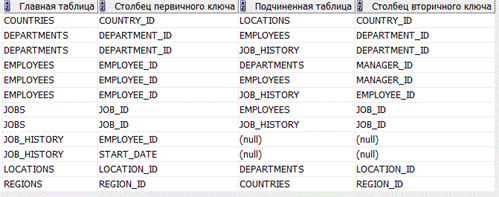
Комментарий:
Сначала создается вспомогательная таблица HR_tables: Выводит все строки из all_constraints, all_cons_columns с владелицей (HR), там есть constraint_name, r_constraint_name, constraint_type (для определения типа PRIMARY KEY), table_name, а также column_name.
Cтроим таблицу Primary_HR_tables будет содержать записи о таблицах схемы HR с типой ограничение PRIMARY KEY.
Таблица Primary_HR_tables соединяется с таблицей HR_tables с условием HR_tables.r_constraint_name = Primary_HR_tables.constraint_name
И Hr_tables.Position = Primary_hr_tables.Position: если ограничение действует на несколько столбцов и тогда нужно организовать вывод так, чтобы первому столбцу PK соответствовал именно первый столбец FK, второму - второй и т.д. На пример, если таблица tbl_parent, имеющий 2 первых ключов id_1 и id_2, соединяются с таблицей tbl_child, имеющий первый ключ id_child.
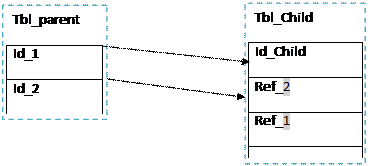 |
Если id_1 и Id_2 имеет position равно 1 и 2 соответственно, то Ref_2 и Ref_1 также имеет position равно 1 и 2 соответственно(position of id_1 и position of id_2).
20. Для произвольной строки, состоящей из чисел, разделенных указанным разделителем, получить строку, отображающую эти числа в обратном порядке. Например, для исходной строки: 0|0|1|2|1|2|10|22|34|15|0|105|66|73 должна быть получена строка: 73|66|105|0|15|34|22|10|2|1|2|1|0|0. Задачу решить:
с использованием регулярных выражений;
с использованием раздела MODEL
WITH tbl_string AS
(SELECT '0|0|1|2|1|2|10|22|34|15|0|105|66|73' str FROM dual)
SELECT RTRIM(res, '|') res
FROM tbl_string
MODEL
PARTITION BY (ROWNUM rn)
DIMENSION BY (0 d)
MEASURES (str, REGEXP_COUNT(str, '\d+') - 1 cnt, CAST('' as VARCHAR2(4000)) res)
RULES ITERATE (4000) UNTIL (ITERATION_NUMBER = cnt[0])
(res[0] = REGEXP_SUBSTR(str[0], '\d+', 1, ITERATION_NUMBER + 1) || '|' || res[0]);
Комментарий:
Решение с использованием раздела MODEL:
Создаем одномерный массив DIMENSION BY (0 d), имеет псевдоним d.
В блоке MEASURES используем регулярное выражение REGEXP_COUNT(str, '\d+'), который возвращает количество digitals ('\d+') между симболом ‘|’ в строку, знак + значит будет несколько раз, в этом примере -14. И функцию CAST('' as VARCHAR2(4000)) для преобразования типов varchar2 c размером 4000(maximum length size bytes).
В блоке RULES используем ITERATE(4000) с UNTIL (ITERATION_NUMBER = cnt[0]), т.е Цикл завершается когда выполнится условие UNTIL. На каждой итерации цикла мы добавим значения res в обратном порядке c использованием функции REGEXP_SUBSTR().
ВАРИАНТ 3
(Базы данных Студент и Human Resources)
1. Из таблицы Employees извлечь строки, в которых значения являются уникальными по всем столбцам.
SELECT * FROM employees e
-- Выводим все значения из таблицы employees, которые удовлетворяют условию, что они уникальны.
WHERE NOT EXISTS (SELECT * FROM employees WHERE
(first_name = e.first_name OR last_name = e.last_name
OR hire_date = e.hire_date OR job_id = e.job_id
OR salary = e.salary OR commission_pct = e.commission_pct
OR manager_id = e.manager_id OR department_id = e.department_id
OR phone_number = e.phone_number OR email = e.email)
AND employee_id!= e.employee_id);
-- будем считать, что поле employee_id уникально по определению (employee_id – первичный ключ).
Результат:
no rows selected.
2. Создать внешнюю таблицу на файл Alert_orcl.log и создать для нее запрос, позволяющий получать информацию об ошибках Oracle за определенный день месяца. Имя директории Aleart.
Решение не получилось.
3. Создать запрос, который позволит оставить только одно из повторяющихся слов в тексте, идущих друг за другом. Количество повторяющихся слов – произвольное.
SELECT regexp_replace ('&my_string', '([[:alpha:]]+)([[:blank:]]+)(\1)(\2)', '\1\2') AS Res
FROM dual;
4. Создать запрос для вывода трех самых высокооплачиваемых преподавателей, на кафедре, на которой они работают. Если какие-то преподаватели кафедры получает самую низкую зарплату из трех высокооплачиваемых, они тоже должны попасть в список.
SELECT фамилия, кафедра, зарплата
FROM преподаватели t
WHERE зарплата IN (SELECT DISTINCT зарплата -- даем каждому преподавателю ранг, согласно его зарплате
FROM (SELECT зарплата, кафедра, rank() over (partition BY кафедра order by зарплата DESC) as rang
FROM преподаватели)
WHERE rang < 4 -- и выводим только тех, у кого ранг меньше четырех
AND кафедра = t.кафедра);
Результат:
Фамилия Кафедра Зарплата
Костыркин Кафедра 1 4000
Викулина Кафедра 1 3000
Казанко Кафедра 1 2000
Абдулов Кафедра 2 3000
Студейкин Кафедра 2 2500
Позднякова Кафедра 2 2500
5. Создать запрос для вывода данных по фамилиям преподавателей, работающих на той же должности, что и Викулина, но на другой кафедре.
SELECT фамилия
FROM преподаватели
WHERE кафедра!=
(SELECT кафедра FROM преподаватели WHERE фамилия = 'Викулина')
AND должность =
(SELECT должность FROM преподаватели WHERE фамилия = 'Викулина');
-- Выбираем те фамилии преподавателей, которые удовлетворяют условию, что кафедра не равна кафедре Викулиной, а должность такая же, как у Викулиной.
Результат:
Фамилия
Абдулов
Студейкин
6. Определить сумму чисел в произвольной символьной строке. Например, для строки fgh123hhh76 результат должен быть 199.
WITH st AS (SELECT '&&enter_string' str FROM dual) --Ввод строки пользователем
SELECT SUM(regexp_substr(str,'[0-9]+',1,l)) summa --Суммируем числа
FROM
(SELECT level l,str FROM st CONNECT BY level<=
(SELECT LENGTH(str) FROM st)); --Выводим строку столько раз, сколько символов в строке
Результат:
Если ввести «aaa56wjkh 12 1 sdsa», то результат будет:
Summa
7. Создать запрос для получения информации о фамилиях студентов, которые сдали экзамены по всем предметам, предусмотренных для их специальности учебным планом.
WITH bad_guys AS –это те, кто не сдал хотя бы один экзамен
(SELECT номер_студента, номер_дисциплины --То, что студент должен сдать
FROM (студенты NATURAL JOIN группы)
RIGHT JOIN учебные_планы USING (код_специальности)
MINUS --Вычитаем из того, что должен был сдать студент, то, что он по факту сдал
SELECT номер_студента, номер_дисциплины --То, что студент сдал
FROM успеваемость
WHERE оценка > 2)
SELECT *
FROM студенты
WHERE номер_студента NOT IN --Выбираем тех студентов, которые не попали к плохим ребятам
(SELECT номер_студента FROM bad_guys);
Результат:
Номер_студента Фамилия Имя Отчество Стипендия Номер_группы
3413 Старова Любовь Михайловна 250 121
3418 Усов Валерий Харитонович 250 123
3412 Поляков Анатолий Алексеевич 200 121
8. Используя словарь данных, получить информацию о первичных ключах и подчиненных таблицах всех таблиц в схеме HR:
| Имя таблицы | Список столбцов первичного ключа | Список подчиненных таблиц |
В списках имена столбцов и таблиц вывести через запятую.
WITH DATA AS (
SELECT main_tables.table_name as MainTable, main_columns.column_name FPK, depend_tables.table_name as DependTable,
ROW_NUMBER() OVER (PARTITION BY main_tables.table_name ORDER BY depend_tables.table_name) RN,
COUNT(*) OVER (PARTITION BY main_tables.table_name) CNT
FROM user_constraints depend_tables
JOIN user_constraints main_tables
ON depend_tables.r_constraint_name = main_tables.constraint_name
JOIN (SELECT column_name, constraint_name FROM user_cons_columns WHERE position = 1) main_columns
ON depend_tables.r_constraint_name = main_columns.constraint_name)
SELECT MainTable,
trim(both ',' FROM SYS_CONNECT_BY_PATH(FPK,', ')) PK,
trim(both ',' FROM SYS_CONNECT_BY_PATH(DependTable,', ')) user_constraints
FROM DATA
WHERE RN = CNT
START WITH RN = 1
CONNECT BY PRIOR MainTable = MainTable AND PRIOR RN = RN-1
ORDER BY MainTable;
Результат:
Дата добавления: 2015-08-18; просмотров: 146 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| CURRENT_YEAR MON TUE WED THU FRI SAT SUN | | | Main_Table PK User_Constraints 1 страница |