Читайте также:
|
Основной синтаксис файла robots. txt очень прост. Вы указываете название робота (например, googlebot), а затем указываете действие. Робот идентифицируется по агенту пользователя, а затем на следующих строках указываются действия. Вот основные действия, которые вы можете указать:
• Disallow: для тех страниц, доступ к которым вы хотите закрыть от роботов (столько строк Disallow, сколько вам нужно);
• Noindex: для тех страниц, доступ к которым вы хотите закрыть от поискового движка и не индексировать (или удалить из индекса, если они были ранее проиндексированы). Эта функция неофициально поддерживается Google и не поддерживается движками Yahoo! и Bing.
Есть некоторые ограничения:
• каждая группа (агент пользователя/Disallow) должна отделяться пустой строкой, однако внутри группы пустых строк существовать не должно (от строки агента пользователя и до последнего Disallow);
• символ # может использоваться в файле robots.txt для комментариев (все, что находится в строке после символа #, игнорируется). Комментарий можно использовать как на всю строку, так и на остаток строки;
• каталоги и имена файлов чувствительны к регистру: private, Private и PRIVATE – эти имена для поисковых движков уникальны.
Вот пример файла robots.txt:
User-agent: Googlebot
Disallow:
User-agent: msnbot
Disallow: /
# заблокировать всем роботам доступ к каталогам tmp и logs
User-agent: *
Disallow: /tmp/
Disallow: /logs # для каталогов и файлов с названием logs
В этом примере делается следующее:
• роботу Googlebot разрешается заходить куда угодно;
• роботу msnbot запрещается просмотр всего сайта;
• всем роботам (кроме Googlebot) блокируется посещение каталога /tmp/ или каталогов (либо файлов) с названием /logs (т. е. /logs или logs.php).
Обратите внимание, что на поведение Googlebot не влияют такие инструкции, как Disallow: /. Поскольку в файле robots.txt для Googlebot есть персональные инструкции, то он будет игнорировать директивы, помеченные как предназначенные для всех роботов (с использованием звездочки).
Неопытные web-мастера часто встречаются с проблемой, которая возникает тогда, когда у них инсталлирован SSL (чтобы страницы можно было выдавать через HTTP и HTTPS). Файл robots.txt по адресу http://www.yourdomain.com/robots.txt не будет восприниматься поисковыми движками как указание насчет просмотраhttps://www.yourdomain.com. Для этого вам нужно будет создать дополнительный файл robots.txt по адресу https://www.yourdomain.com/robots.txt.
Итак, если вы хотите разрешить просмотр всех страниц вашего сервера HTTP и запретить просмотр всех страниц сервера HTTPS, то вам нужно реализовать следующее:
Для HTTP:
User-agent: *
Disallow:
Для HTTPS:
User-agent: *
Disallow: /
Это самые основы применения файлов robots.txt, однако существуют и более сложные методы. Некоторые из этих методов поддерживаются не всеми движками, как это показано в следующем списке:
• Crawl delay (Задержка перед просмотром).
Эта директива поддерживается Yahoo! Bing и Ask. Она дает указание пауку ждать указанное количество секунд до того, как начать просмотр страниц. Цель этой директивы – снизить нагрузку на сервер издателя:
User-agent: msnbot
Crawl-delay: 5
• Pattern matching (Сопоставление с образцом).
Сопоставление с образцом используется Google, Yahoo! и Bing. Ценность этой директивы велика. Вы можете делать сопоставление с образцом (при помощи группового символа "звездочка"). Вот пример использования сопоставления с образцом для блокирования доступа ко всем подкаталогам, которые начинаются с private (например: /private1/, /private2/, /private3/ и т. д.):
User-agent: Googlebot
Disallow: /private*/
Вы можете обозначить конец строки при помощи знака доллара. Например, для блокирования таких URL, которые заканчиваются на. asp:
User-agent: Googlebot
Disallow: /*.asp$
Вы можете пожелать предотвратить доступ роботов к любым URL, которые содержат параметры. Для блокирования доступа ко всем URL, которые содержат знак вопроса, просто используйте знак вопроса:
User-agent: *
Disallow: /*?*
Возможности по сопоставлению шаблонов в файле robots. txt более ограничены, чем возможности таких языков программирования, как Perl, так что знак вопроса не имеет никакого специального значения и может использоваться как любой другой символ.
• Директива Allow.
Директива Allow поддерживается только в Google, Yahoo! и Ask. Она работает как противоположность директивы Disallow и дает возможность конкретно указывать те каталоги или страницы, которые можно просматривать. Когда эта возможность реализуется, она может частично перекрыть предыдущую директиву Disallow. Это может пригодиться в том случае, когда были запрещены большие разделы сайта (либо когда запрещен весь сайт целиком).
Вот пример, в котором роботу Googlebot разрешается доступ только в каталог google:
User-agent: Googlebot
Disallow: /
Allow: /google/
• Директива Noindex.
Эта директива работает точно так же, как и команда meta robots noindex (которую мы скоро обсудим). Она говорит поисковым движкам, что надо однозначно исключить страницу из индекса. Поскольку Disallow предотвращает просмотр, но не индексирование, то Noindex может быть очень полезной функцией для того, чтобы гарантировать отсутствие страниц в результатах поиска. Однако по состоянию на октябрь 2009 г. эту директиву в файле robots.txt поддерживает только Google.
• Sitemap.
Мы обсуждали XML Sitemap в начале этой главы. Вы можете использовать robots.txt для предоставления пауку механизма автоматического обнаружения местонахождения файла XML Sitemap. Поисковому движку можно сказать о местонахождении этого файла одной простой строкой в файле robots.txt:
Sitemap: sitemap_location
sitemap_location – это полный URL к Sitemap (такой, как http://www.yourdomain.com/sitemap.xml). Вы можете разместить эту строку в любом месте вашего файла.
Полные указания по применению файла robots.txt смотрите на сайте Robots.txt.org (http://www.robotstxt.org/orig.html). Для экономии времени и сил вы можете также воспользоваться инструментом генерирования файла robots.txt, который разработал Dave Naylor (http://www.davidnaylor.co.uk/the-robotstxt-builder-a-new-tool.html).
Будьте очень осторожны при внесении изменений в файл robots.txt. Например, простая опечатка может внезапно сказать поисковым движкам, что они больше не должны вообще просматривать ваш сайт. После обновления файла robots.txt всегда полезно проверить его при помощи инструмента Test Robots.txt (http://www.google.com/webmasters/tools/crawl-access) из набора инструментов Google Webmaster Tools.
Атрибут Rel="NoFollow”
В 2005 г. три основных поисковых движка (Yahoo! Google, и Microsoft) достигли согласия насчет поддержки инициативы, направленной на снижение эффективности автоматического спама. В отличие от версии meta robots директивы NoFollow, новую директиву можно было использовать как атрибут внутри тега <a> или тега ссылки (чтобы указать, что ссылающийся сайт не ручается за качество той страницы, на которую сделана ссылка). Это позволяет создателю контента делать ссылку на web-страницу без передачи ей всех тех нормальных преимуществ поисковых движков, которые следуют из ссылки (доверие, якорный текст, рейтинг PageRank и т. д.).
Первоначальным намерением было дать возможность блогам и форумам (и прочим сайтам с генерируемыми пользователями ссылками) снизить количество спамеров, которые создавали пауков для автоматического создания ссылок. Однако этот функционал был расширен, поскольку Google (в частности) рекомендует применять NoFollow для платных ссылок, т. е. поисковые движки считают, что для подъема рейтинга сайта (или страницы) должны засчитываться только такие ссылки, которые являются чисто редакционными и делаются издателями бесплатно (без всякой компенсации).
Вы можете реализовать NoFollow с помощью следующего формата:
<a href="http://www.google.com" rel="NoFollow">
Обратите внимание, что несмотря на то, что вы можете использовать NoFollow для ограничения передачи стоимости ссылок между web-страницами, поисковые движки по-прежнему могут передвигаться по этим ссылкам (несмотря на отсутствие семантической логики) и по тем страницам, на которые они указывают. По этому вопросу от поисковых движков были получены противоречивые данные. Если их суммировать, то получается следующее: атрибут NoFollow не запрещает явным образом просмотр или индексирование, так что если вы делаете с ним ссылки на ваши собственные страницы (намереваясь предотвратить их индексирование или ранжирование), то остальные могут их обнаружить и сделать на них ссылки (что нарушит ваши первоначальные планы).
На рис. 6.33 показано, как робот поискового движка интерпретирует атрибут NoFollow, когда он находит его связанным со ссылкой (в данном примере это Link 1).
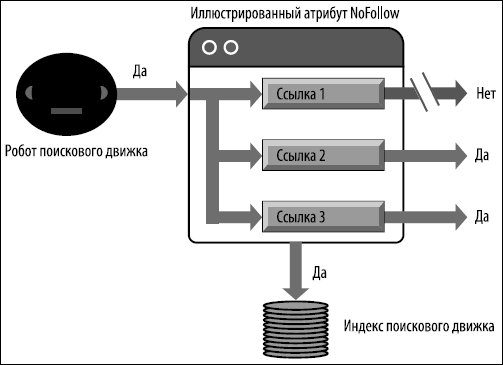
Рис. 6.33. Воздействие атрибута NoFollow
Ссылка с атрибутом NoFollow не передает "сок ссылок". Никакие другие аспекты работы поисковых движков со страницей не изменяются.
После введения атрибута NoFollow стала популярной идея накачки с его помощью рейтинга PageRank. Существовало такое мнение, что когда вы делаете NoFollow по конкретной ссылке, то "сок ссылок" (который должен передаваться этой ссылке) сохраняется, а поисковые движки перераспределяют его другим найденным на этой странице ссылкам. В результате многие издатели реализовали ссылки NoFollow на менее ценные страницы своих сайтов (такие, как "Информация о нас" и "Свяжитесь с нами" или страницы товарных каталогов с альтернативными сортировками). Фактически опубликованные в марте 2009 г. данные из инструмента SEOmoz Linkscape (http://www.seomoz.org/linkscape) показали, что на тот момент примерно 3 % всех ссылок в Интернете были с NoFollow и что 60 % этих NoFollow были применены к внутренним ссылкам.
Однако в июне 2009 г. Matt Cutts (из компании Google) написал пост, после которого стало ясно, что связанный со ссылкой NoFollow "сок" отбрасывается, а не перераспределяется (http://www.mattcutts.com/blog/pagerank-sculpting/). Теоретически вы при желании можете использовать NoFollow, но применение его для внутренних ссылок не даст (по состоянию на сегодняшний день и в соответствии с утверждениями Google) тех преимуществ, на которые мы ранее рассчитывали. В действительности (при некоторых сценариях) это может быть даже вредно.
А вот пример, иллюстрирующий эту проблему. Если издатель использует 500-страничный сайт и на каждой странице имеется ссылка на страницу "Информация о нас" и все эти ссылки помечены как NoFollow, то это отрежет "сок ссылок", который иначе посылался бы на страницу "Информация о нас". Однако поскольку этот "сок ссылок" отбрасывается, то остальная часть сайта никакой пользы не получает. Если же атрибуты NoFollow удалить, то страница "Информация о нас" будет передавать хотя бы часть "сока ссылок" обратно на остальную часть сайта (через ссылки на странице "Информация о нас").
Это хорошая иллюстрация постоянно меняющейся сути оптимизации. То, что раньше было популярной и эффективной тактикой, в настоящий момент рассматривается как неэффективное средство. Некоторые агрессивные издатели будут продолжать накапливать "сок ссылок" при помощи еще более агрессивных методов, таких как реализация ссылок внутри JavaScript или внутри i-фреймов (для которых стоит Disallow в файле robots.txt), так что поисковые движки не будут видеть этих ссылок. Такая агрессивная тактика, вероятно, не стоит затраченных на нее усилий (для большинства издателей).
Дата добавления: 2015-10-13; просмотров: 115 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Файл robots.txt | | | Метатег robots |