Читайте также:
|
Глава 10. Универсальные алгоритмические модели
Природа устроена рационально, а все явления протекают по точному и неукоснительному плану, который, в конечном счете, является математическим.
Аристотель
Виды универсальных алгоритмов, абстрактный алфавит, числовая функция, машина Тьюринга, графическая схема алгоритма, структурная схема алгоритма, логическая схема алгоритма, алгоритмы Маркова, алгоритмы Ван-Хао, словесное описание алгоритма
ЦЕЛИ
Освоив эту главу, учащиеся должны уметь и знать:
· Строить алгоритмические модели;
· Составлять логическую схему алгоритма;
· Записывать графическую схему алгоритма;
· Составлять структурную схему алгоритма;
· Записывать словесную схему алгоритма;
· Выполнять преобразования на основе алгоритмов Маркова и Ван-Хао.
10.1. Преобразование слов в произвольных абстрактных алфавитах
Существуют три основных типа универсальных алгоритмических моделей:
· преобразование слов в произвольных абстрактных алфавитах;
· преобразование числовых функций;
· представление алгоритмов как некоторого детерминированного устройства, способного выполнять простейшие операции.
В первом типе универсальных алгоритмических моделей под алгоритмом понимают задаваемые соответствия между словами в абстрактных алфавитах (АА). Под абстрактным алфавитом понимается конечная совокупность объектов, называемых буквами или символами этого алфавита. Символами абстрактного алфавита считают буквы, цифры, любые знаки, слова, предложения, любые тексты. Следовательно, абстрактный алфавит — это конечное множество различных символов, и, подобно множеству, его можно задать путем перечисления элементов или символов.
Например, А — абстрактный алфавит: А = { +, а, студент, b, c, учебник }.
Абстрактный алфавит является многоступенчатым, т.е. каждый символ может сам являться алфавитом или его частью. Тогда в соответствии с определением первой алгоритмической модели алгоритмами называют преобразование слов в абстрактном алфавите. Соответственно, словом в абстрактном алфавите называют любую конечную упорядоченную последовательность символов. В качестве примера приведем следующую запись:
Слово А = < +, a >, Слово B = < b, +, c >, Слово C = < >, Слово D = < + >. Здесь слово А состоит из двух символов, В – из трех символов, С – не содержит символов и является пустым, D – содержит один символ.
Число символов в слове абстрактного алфавита называется длиной этого слова.
Алфавитным оператором (АО) называют функцию, которая задает соответствие между словами входного и выходного АА.
Пусть задана система с входным абстрактным алфавитом X и выходным Y. Пусть Х = { a, b, ЭВМ, ПЭВМ }; Y = { a + b, a ´ b, система, ВЦ }. Построим АО, который перерабатывает входные слова алфавита Х в выходные слова алфавита Y. На рис. 2.1 показан один из возможных вариантов алфавитного оператора.
Алфавитные операторы бывают однозначные и многозначные. В однозначном АО каждому входному слову ставится в соответствие одно выходное слово. В многозначных АО каждому входному слову может быть поставлено в соответствие некоторое множество выходных слов. АО, который не ставит в соответствие входному слову никакого выходного, называется неопределенным на этом слове. В примере на рис. 10.1. приведен один из возможных вариантов многозначного АО.
Множество слов, на котором АО определен, называется его областью определения.
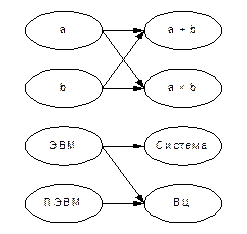
Рис. 10.1. Пример алфавитного оператора
Выделяют алфавитные операторы с конечной и бесконечной областями определения. Если область определения АО конечна, то его обычно задают таблицей соответствий. В левой части таблицы записывают слова, входящие в область определения, в правую часть таблицы — слова, получающиеся в результате применения АО к входным словам. Если область определения алфавитного оператора бесконечна, то его задают набором правил, которые за конечное число шагов позволяют найти выходное слово, соответствующее входному.
Алфавитный оператор, задаваемый с помощью конечной системы правил, называется алгоритмом.
Следует различать понятие алгоритма и алфавитного оператора. В АО основное — это соответствие между словами, а не способ его установления. В алгоритме же основное — способ установления соответствия между словами. Следовательно, алгоритм - это АО с правилами, определяющими его действие.
Два алгоритма называются равными, если равны их АО и совпадают системы правил, задающих действие этих алгоритмов на входные слова.
Алгоритмы считаются эквивалентными, если они имеют совпадающие АО, но не совпадающие способы их задания.
Например, пусть алгоритм A1 определяется следующим образом:
X = {a, b, c} – входной абстрактный алфавит;
Y = {a, b, g} – выходной абстрактный алфавит;
Алфавитный оператор (АО1): a ® a, b ® b, c ®g.
Система правил, задающая действие алфавитного оператора: А, В, С.
Пусть алгоритм A2 определяется следующим образом:
X = {a, b, c} – входной абстрактный алфавит;
Y = {a, b, g} – выходной абстрактный алфавит;
Алфавитный оператор (АО2): a ® a, b ® b, c ®g.
Система правил, задающая действие алфавитного оператора: А, В, С.
Тогда алгоритм А1 равен алгоритму А2. Если в алгоритме А2 система правил, задающая действие алфавитного оператора АО2: В, С, А, то алгоритм А1 эквивалентен алгоритму А2.
10.2. Числовые функции
Из определения алгоритма следует, что он ставит в соответствие исходным данным выходные. Поэтому каждому алгоритму можно поставить в соответствие функцию, которую он вычисляет. Рассмотрим теперь второй тип алгоритмических моделей. Их называют числовые функции.
Функцию называют вычислимой, если имеется способ получения ее значений. В алгоритмах часто используются рекурсивные функции, представляющие собой частичный класс вычислимых функций.
Процедуру, которая прямо или косвенно обращается к себе в процессе выполнения алгоритма, называют рекурсивной.
Рекурсия — это способ задания функций, когда ее значения для произвольных значений аргументов выражаются известным образом через значения определяемой функции для меньших значений аргументов.
Алгоритмы, определяющие способы задания рекурсивных функций, часто называют алгоритмами, сопутствующими рекурсивным функциям. Выделяют три способа построения рекурсивных функций: на основе оператора суперпозиции; на основе оператора рекурсии и на основе оператора построения по первому нулю.
Функции, полученные без использования оператора построения по первому нулю, называются примитивно - рекурсивными.
Рекурсивные функции, определенные не для всех возможных значений аргумента, называются частично - рекурсивными.
Рассмотрим рекурсивную функцию (РФ).
В ней различают:
1. Имя, т.е. ее обозначение.
2. Запись (W = f(x1, x2, x3) или F = f(x1,..., xn)).
3. Значение функции.
Значение функции отвечает конкретным значениям аргумента. Например, в функции f(x1, x2, x3), аргументы x1, x2, x3 имеют следующие значения x1 = 1, x2 = 3, x3 = 100. Эту же функцию можно эквивалентно представить в следующем виде: f(1, 3, 100).
Рекурсивные функции бывают простые и сложные. Простейшие РФ называют базовыми. Представляющие эти РФ алгоритмы называются одношаговыми. Из базовых РФ на основе операторов можно получать любые составные РФ. Выделяют три типа базовых рекурсивных функций.
1. Функции любого числа независимых переменных, тождественно равные нулю. Их обозначают f0, j0.
Если функция записывается в виде j0 или f0, то любой совокупности значений аргументов данной функции ставится в соответствие значение ноль. Например, j0(0) = 0, j0(3, 5, 7) = 0, j0(4, 17) = 0.
2. Тождественные функции любого числа независимых переменных вида jn,i, причем 1 £ i £ n.
Представляющий эту функцию алгоритм запишется: если функциональный знак имеет вид jn,i, то значением функции следует считать значение (слева направо) i - того независимого переменного. Пример, W = j3,2(X, Y, Z) = Y, j3,3(3, 4, 8) = 8. j3,4(3, 4, 8) = 0 — эта запись не имеет смысла, т.к. n = 3, i = 4 и не выполняется условие 1 £ i £ n. Для тождественных функций n, i ¹ 0.
3. Функции следования.
Представляющий эти функции алгоритм запишется: если функциональный знак имеет вид l, то значением функции следует считать число, непосредственно следующее за числом, являющимся значением алгоритма. Например, операцию получения значения функции следования обозначают “ ‘ ” т.е., 0’ = 1, 1’ = 2... l‘(5) = 6.
Отметим, что базовые функции имеют значения, если заданы значения их аргументов.
Рассмотрим оператор суперпозиции или подстановки. Оператор по функции F от n аргументов и по функциям f1, f2,..., fn строит новую функцию Ф так, что справедливо выражение:
Ф º F(f1, f2,..., fn).
Алгоритм, представляющий данный оператор, запишется: значения функций f1, f2,..., fn принять за значения аргументов функции F и вычислить ее значение.
Пример. Если f1 = l(y), а F = l(x) и x = l(y), то на основе оператора суперпозиции получится новая функция r(y) = l(l(y)) = l(y’) = y’’. Тогда получили новую функцию r(y) º Ф.
Иногда в алгоритмах вводится знак «::= », что означает «по определению» или «присвоить». Применение этого знака реализует оператор подстановки, который обозначается S.
Например, построение функции Ф из функций F и fi с помощью оператора суперпозиции можно записать в следующем виде:
Ф::= S[F; f1, f2,..., fn].
Для r(y)::= S[l(x), l(y)].
Рассмотрим оператор рекурсии. Он реализуется на основе двух функций, одна из которых имеет (n-1) независимую переменную, а другая, кроме указанных, еще две, т.е. (n+1).
При этом один из дополнительных аргументов войдет вместе с аргументами первой функции в число аргументов вновь получаемой, а другой, дополнительный, — при выполнении оператора рекурсии.
Оператор рекурсии обозначается R. Его применение записывают в виде следующей строки.
f::= R[f1, f2, x(y)], где f — получаемая функция;
f1 — функция (n-1) независимых переменных;
f2 — функция (n+1) независимых переменных;
x — главный из дополнительных аргументов;
y — вспомогательный аргумент.
Оператор рекурсии задает функцию с помощью двух условий, в которые входят функции f1 и f2.
Например, построение функции предшествования.
f(0) = f1, f(i’) = f2(i, f(i)), пр(0) = 0, пр(1) = 0, пр(2) = 1, пр(3) = 2... Здесь пр - это обозначение функции предшествования.
Рассмотрим оператор построения функции по первому нулю. Он по заданной функции, зависящей от (n+1) аргументов, строит новую функцию от n аргументов. Здесь вспомогательный аргумент — исчезает. Например, для функции вида: f::=m [ f1 (x)], х — исчезающий аргумент.
Тогда алгоритм запишется: придавать вспомогательному аргументу последовательные значения с нуля до тех пор, пока не окажется, что функция f1 не стала равна нулю (в первый раз). Полученное значение вспомогательного аргумента принять за значение определяемой функции, соответствующее тем значениям основных аргументов, при которых осуществляется описанный процесс.
С помощью перечисленных операторов и функций строится любая сложная функция, которая может представить исследуемый алгоритм.
Сформулируем тезис Чёрча. Какова бы ни была вычислимая неотрицательная целочисленная функция от неотрицательных целочисленных аргументов, всегда существует тождественно равная ей рекурсивная функция.
Тогда тезис Черча можно интерпретировать для анализа алгоритмов следующим образом: каков бы ни был алгоритм, перерабатывающий наборы целых неотрицательных чисел, всегда существует алгоритм, представляющий РФ, который ему эквивалентен.
Тогда реализация алгоритма, в определенном смысле, эквивалентна вычислению значений РФ. При этом невозможность построения РФ будет означать невозможность построения алгоритма.
10.3. Построение алгоритмов по принципу «разделяй и властвуй»
Существует много стандартных приёмов, используемых при построении алгоритмов. Например, сортировка вставками является одним из таких стандартных приемов. При этом алгоритм действует по шагам и происходит последовательное добавление элементов одного за другим к отсортированной части массива. При решении сложных задач большой размерности их часто разбивают на части, определяют решения, а затем из них получают решение всей задачи. Этот прием, если принять его рекурсивно, как правило, приводит к эффективному решению основной задачи, подзадачи которой составляют ее меньшие версии. Этот прием называется принцип «разделяй и властвуй». На основе принципа «разделяй и властвуй» можно построить более быстрый алгоритм сортировки.
Отметим, что многие алгоритмы по природе своей рекурсивны, т.е. решая некоторую задачу, они обращаются сами к себе для решения её подзадач. Идея метода «разделяй и властвуй» состоит как раз в этом. Сначала решаемая задача разбивается на задачи меньшего размера. Затем эти задачи решаются (с помощью рекурсивного вызова - или непосредственно, если размер задачи достаточно мал). Наконец, полученные решения объединяются и получается решение исходной задачи.
Для задачи сортировки процесс решения выглядит так. Сначала массив разбивается на две половины, каждая из которых сортируется отдельно. После чего два упорядоченных массива соединяют в один. Рекурсивное разбиение задачи происходит до тех пор, пока размер массива не станет равным единице (любой массив длины 1 можно считать упорядоченным).
Нетривиальным этапом является объединение двух упорядоченных массивов в один. Оно выполняется с помощью различных вспомогательных процедур.
10.4. Представление алгоритма в виде детерминированного устройства
Математик А. Тьюринг - один из основателей анализа сложности алгоритма. Он разработал идеи представления алгоритмов на основе детерминированных устройств. Такое устройство называется машиной Тьюринга (МТ). Модель машины Тьюринга является третьей алгоритмической моделью. Она состоит из трех частей - ленты, считывающего устройства (головки) и управляющего устройства (УУ) (рис. 10.2).

Рис. 10.2. Представление машины Тьюринга
На рис. 10.2 цифра 1 обозначает ленту МТ. Она представляет собой бесконечную память машины. В качестве ленты можно использовать любой носитель памяти (бумажную или магнитную ленту). Отметим, что лента считается бесконечной длины в обе стороны. Она разбивается на стандартные ячейки одинакового размера. В каждой ячейке может быть записан только один любой символ конечного алфавита. Число возможных символов конечно, и они образуют абстрактный алфавит машины А = {a1, a2,..., am}. Отсутствие символа в ячейке обозначается специальным «пустым» символом «».
МТ имеет считывающую головку (цифра 2 на рис. 10.2), способную считывать содержимое ячеек. Головка всегда располагается над одной из ячеек ленты. Она может читать и писать символы, стирать их. Лента перемещается вдоль головки в обе стороны таким образом, чтобы в любой момент считывать содержимое одной ячейки ленты. На каждом шаге работы машины головка находится в одном из множества состояний Q = { q1,..., qn }, среди которых выделяют начальное q 1 и конечное qz, состояния.
Элементарный шаг машины Тьюринга состоит из следующих действий:
· головка считывает символ, записанный в ячейке, над которой она находится;
· считанный символ ak и текущее состояние головки qj однозначно определяют новое состояние qi, новый записываемый символ аl и перемещение головки dp (на одну ячейку влево, вправо или остаться на месте).
Кроме этого, МТ имеет устройство управления (УУ), которое в каждый момент находится в одном из состояний Q = { q 1, q 2,..., qn }. Состояние устройства управления называется внутренним состоянием МТ. Одно из состояний является заключительным состоянием МТ и управляет окончанием работы машины. Устройство управления хранит и выполняет команды машины, например, вида qjak → qialdp.
Данные в машине Тьюринга — это слова в абстрактном алфавите ленты. На ленте МТ записывают исходные данные и конечные результаты.
Полное состояние машины Тьюринга называется конфигурацией и включает в себя состояние головки, состояние ленты (слово, записанное за ней) и положение головки на ленте. Конфигурация машины Тьюринга описывается тройкой a1qa2, где q — текущее состояние головки, а 1 — слово слева, а а 2 — слово справа от головки (включая символ, над которым находится головка). Конфигурация, изображенная на рис. 10.2, может быть записана так: аi «» qj ak am. Конкретную машину Тьюринга (и алгоритм соответственно) можно задать, перечислив элементы алфавита А, множества состояний Q и команды машины.
Перед началом работы на пустую ленту записывается исходное слово а абстрактного алфавита. Головка устанавливается над первым его символом и, как следствие, начальной конфигурацией является запись вида q1a.
Работа машины Тьюринга состоит в изменении конфигураций. Конфигурацией машины Тьюринга называется ее полное состояние, по которому можно однозначно определить дальнейшее поведение машины. Оно обозначается тройкой a1 qi a2, где a1 — слово слева от головки, a2 — слово, состоящее из символа, просматриваемого головкой и расположенного справа. Стандартной начальной конфигурацией называется конфигурация вида q 1 a, где просматривается крайний слева символ, записанный на ленте. Стандартной заключительной конфигурацией называется выражение вида q 2 a. Ко всякой произвольной конфигурации k в машине Тьюринга применима только одна команда типа qiaj ® qi'aj'sk, которая переводит конфигурацию k в k'.
Совокупность всех команд, которые может выполнять машина Тьюринга, называется программой. При решении задач с входными данными сопоставляется начальная конфигурация k 0, а выходные данные определяются заключительной конфигурацией, в которую машина Тьюринга переводит k 0.
Например, рассмотрим машину Тьюринга, переводящую последовательность а 1, а 2,..., ап в последовательность b 1, b 2,..., bп, работающую в соответствии с программой qiaj ® qi'aj'sk. Считывающая головка, перемещая ленту направо в соответствии с программой, будет стирать символы а 1, а 2,..., ап и вместо них соответственно записывать выходные символы b 1, b 2,..., bп. Если потребовать, чтобы при просмотре клетки ленты с пустым символом машина Тьюринга переходила в заключительное состояние, то после остановки машины на ленте будет выходная последовательность b 1, b 2,..., bп.
Известно, что на машине Тьюринга можно имитировать все алгоритмические процессы, которые можно представить в математическом виде.
А. Тьюринг показал, что если проблемы не могут быть решены на его машине, то они не могут быть решены ни на какой другой автоматической ЭВМ, т.е. это проблемы, для которых алгоритмы не могут быть составлены даже в принципе. Следовательно, невозможность построения машины Тьюринга означает невозможность построения алгоритма решения данной проблемы. Следует отметить, что речь идет об отсутствии алгоритма, решающего всю данную проблему, что не исключает возможности решения этой проблемы в частных случаях различными для каждого случая методами.
10.5. Универсальные схемы алгоритмов
Все операции, выполняемые в алгоритмах, разделяют на две группы: арифметические операции и логические операции. Арифметические операции выполняют непосредственное преобразование информации. Логические операции определяют последовательность выполнения арифметических операций.
Рассмотрим основные универсальные схемы алгоритмов. К ним относят:
· Алгоритмы Ван - Хао.
· Алгоритмы Маркова.
· Алгоритмы Ляпунова.
· Графические схемы алгоритмов (ГСА).
· Структурные схемы алгоритмов (ССА).
· Словесные схемы алгоритмов (СА).
Универсальные схемы алгоритмов Ван - Хао появились в 50-х годах прошлого столетия. Операторный алгоритм Ван-Хао задается последовательностью приказов специального вида. Каждый приказ имеет определенный номер и указание, какую операцию необходимо выполнить над заданным объектом и с каким номером следует далее выполнять действие над результатом этой операции. Например, некоторый приказ записывается следующим образом (рис. 10.3):
| i: | w | a | b |
Рис. 10.3. Пример приказа
На рис. 10.3 i — номер приказа, w — элементарная операция над заданным объектом, a и b — номера произвольных других приказов. Выполнить приказ i над объектом или числом x означает вычислить w(x) и затем перейти к выполнению над w(x) приказа с номером a, если w(x) не определяется, то перейти к выполнению над числом x приказа с номером b. Заключительному состоянию в алгоритме Ван - Хао соответствует приказ, представленный на рис. 10.4:
| i: | стоп |
Рис. 10.4. Приказ на окончание работы алгоритма Ван-Хао
Такая запись означает, что вычисления следует прекратить.
В настоящее время схемы алгоритмов Ван-Хао не имеют широкого практического применения, а используются для теоретического представления алгоритмов.
Интерес в практической деятельности представляют нормальные алгоритмы Маркова (НАМ). Они основаны на использовании абстрактных алфавитов и марковских подстановок. В качестве исходных данных и конечных результатов нормальные алгоритмы Маркова (НАМ) используют строки символов, т.е. слова абстрактных алфавитов.
Марковской подстановкой называют операцию над словами, задаваемую парой слов < P, Q >, где P и Q —слова в абстрактном алфавите. Суть подстановки заключается в следующем. В исходном слове С определяется первое вхождение слова Р. Если оно есть, то производится замена этого вхождения словом Q без изменения остальных частей слова С. При этом слова P и Q должны иметь одинаковую размерность.
Пример 10.1. Пусть задано слово С = 832547, и задана пара <P, Q> = <32, 00>. Тогда результатом работы нормального алгоритма Маркова будет слово C’ = 800547.
Пример 10.2. Пусть задано слово С = 832547, и задана пара <P, Q> = <9, 4>). Отметим, что такая марковская подстановка к слову C не применима, так как в нем отсутствует цифра 9.
Нормальные алгоритмы Маркова применяют для анализа и преобразования формульных записей. Тогда НАМ работает следующим образом. Двигаясь по столбцу формул, определяют первую формулу, левая часть которой входит в преобразуемое слово; если такой формулы нет, то процесс окончен. При ее наличии выполняется марковская подстановка, изменяющая преобразуемое слово. После этого проверяется, заключительная ли это подстановка или нет. Если да, то процесс окончен, если нет, то весь процесс повторяется с самого начала.
Например, пусть заданы следующие выражения:
1234567;
9713256;
0001111;
2224444.
И задана пара <P, Q> = <2, B>.
Тогда результат работы НАМ запишется следующим образом:
1В34567;
9713В56;
ВВВ4444.
Нормальные алгоритмы Маркова в основном применяются для преобразования, минимизации и доказательства алгебраических тождеств.
Рассмотрим схемы алгоритмов Ляпунова. Для описания алгоритмов Ляпунова используют логические схемы алгоритмов (ЛСА). Логическими схемами алгоритмов называют выражения, составленные на основе абстрактного алфавита и состоящие из последовательной цепочки операторов и логических условий. В ЛСА операторами являются действия алгоритма, в результате которых происходит обработка и преобразование информации. Операторы обозначают строчными буквами. Прописными буквами в ЛСА обозначают проверяемые логические условия. Последовательность выполнения нескольких операторов представляется в виде их произведения. Операторы в таком предложении выполняются слева направо. После каждого логического условия ставится стрелка вверх (назовем ее условно восходящей), которая обозначает собой переход по условию. Каждая стрелка имеет свой собственный номер. Каждой восходящей стрелке соответствует одна нисходящая (т.е. стрелка вниз) стрелка с тем же номером, что и у восходящей. Таким образом, если заданное логическое условие справедливо, то выполняется следующий оператор, расположенный справа от условного. Если условие ложно - то выполняется оператор, расположенный справа от нисходящей стрелки, имеющей тот же номер.
Приведем пример записи ЛСА:
А0 ¯1 A1 q 1 ¯2 A2 p 2 Ak.
Согласно этому выражению работа алгоритма начинается с выполнения левого оператора. Обычно это оператор А0, представляющий собой начало алгоритма. Затем выполняется следующий справа оператор A1. Следующий за оператором A1 оператор q является логическим условием. Поэтому в зависимости от результатов проверки истинности этого условия будут выполняться либо оператор A2 - если условие q - истинно, либо оператор A1 (по нисходящей стрелке). Аналогичные действия выполняются и для другого логического условия p. Последним в алгоритме является крайний правый оператор, обозначаемый обычно Ak. Он называется оператором окончания алгоритма.
В общем случае ЛСА Ляпунова должны удовлетворять следующим условиям:
Дата добавления: 2015-10-26; просмотров: 248 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| Множество A, любой элемент которого принадлежит множеству B, называется… множества B. | | | Содержать один начальный и один конечный оператор, соответственно А0 и Ak. |