Читайте также:
|
Начальным этапом любого метода индексирования является отбор из документов терминов, которые бы наилучшим образом характеризовали их содержимое. Такая необходимость вызвана тем, что непосредственное сканирование текстов документов во время поиска занимает слишком много времени, особенно в поисковых системах сети Интернет. С другой стороны, хранение полных текстов документов в базах данных поисковых систем привело бы, во-первых, к резкому росту их объема, и, во-вторых, поставило бы проблему соблюдения авторских прав.
Для выделения из документа индексационных терминов используются главным образом статистические закономерности распределения частоты появления различных слов в текстах. В частности, в теории индексирования особый интерес представляют явления, поведение которых носит гиперболический характер. Другими словами, произведение фиксированных степеней переменных остается для таких явлений постоянным.
Наиболее известный гиперболический закон, относящийся к статистической обработке текстов, сформулирован Дж. Ципфом. Он касается распределения слов в достаточно больших выборках текста и используется для решения задачи выделения ключевых слов (терминов) произвольного документа. Основываясь на общем "принципе наименьшего усилия"[2], Дж. Ципф вывел универсальный закон, который применим ко всем созданным человеком текстам [8, 10, 14].
Рассмотрим некоторый текст, количество слов в котором обозначим как  , а число вхождений каждого слова
, а число вхождений каждого слова  в этот текст обозначим как
в этот текст обозначим как 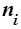 . Частота появления[3] слова в таком случае будет определяться формулой
. Частота появления[3] слова в таком случае будет определяться формулой
 . .
|
Если расположить слова текста в порядке убывания частоты их появления, начиная с наиболее часто встречающихся, то произведение частоты слова 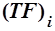 на порядковый номер частоты будет постоянным для любого данного слова :
на порядковый номер частоты будет постоянным для любого данного слова :
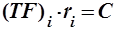 , ,
| (2.2) |
где 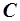 – некоторая константа,
– некоторая константа, 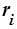 – порядковый номер (ранг) частоты слова . Наиболее часто встречающиеся слова будут иметь ранг 1, следующие за ними – 2 и т. д. Если несколько слов имеет одинаковую частоту, то ранг присваивается только одному значению из каждой группы.
– порядковый номер (ранг) частоты слова . Наиболее часто встречающиеся слова будут иметь ранг 1, следующие за ними – 2 и т. д. Если несколько слов имеет одинаковую частоту, то ранг присваивается только одному значению из каждой группы.
Выражение (2.2) описывает функцию вида 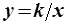 и её график – гипербола, или прямая в логарифмических координатах (рис. 5).
и её график – гипербола, или прямая в логарифмических координатах (рис. 5).

| 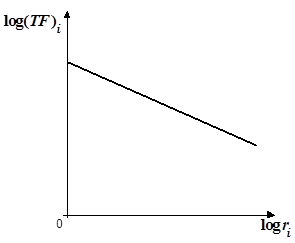
|
Рис. 5. Закон Ципфа
Эксперименты показывают, что частота и количество слов , входящих в текст с этой частотой (другими словами, количество слов, имеющих одинаковый ранг частоты), также связаны между собой. Обозначим это количество как 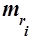 . Форма кривой зависимости
. Форма кривой зависимости 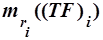 сохраняет свои параметры для всех текстов в пределах одного языка. Вид такой зависимости представлен на рис. 6.
сохраняет свои параметры для всех текстов в пределах одного языка. Вид такой зависимости представлен на рис. 6.
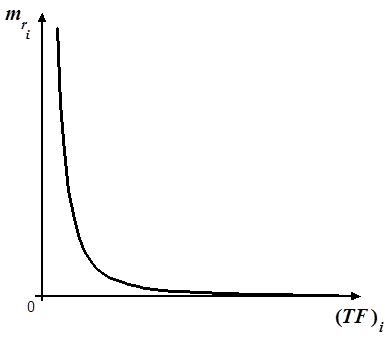
Рис. 6. Зависимость числа слов каждого ранга от частоты их встречаемости
Вероятность 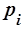 встретить произвольно выбранное слово , очевидно, будет равна частоте встречаемости этого слова в тексте:
встретить произвольно выбранное слово , очевидно, будет равна частоте встречаемости этого слова в тексте:
 . .
|
Таким образом, согласно закону Ципфа, если самое распространенное слово встречается в тексте, например 50 раз, то следующее по частоте слово с высокой долей вероятности встретится 25 раз.
Связь, задаваемая зависимостью (2.2), описывает реальные данные приближенно. Более точное совпадение с экспериментом дает несколько измененное уравнение
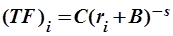 . .
| (2.3) |
Здесь и  – параметры распределения, а
– параметры распределения, а 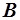 – малая константа, называемая поправкой Мандельброта. Она улучшает совпадение для общеупотребительных слов, имеющих низкий ранг, а параметр – для слов, имеющих высокий ранг. Значение константы в разных языках различно, но внутри одной языковой группы оно остается неизменным вне зависимости от анализируемого текста.
– малая константа, называемая поправкой Мандельброта. Она улучшает совпадение для общеупотребительных слов, имеющих низкий ранг, а параметр – для слов, имеющих высокий ранг. Значение константы в разных языках различно, но внутри одной языковой группы оно остается неизменным вне зависимости от анализируемого текста.
Выражение (2.3) называется каноническим законом Ципфа [5]. Оно используется для составления поискового образа документа, то есть для извлечения из текста документа слов, наиболее адекватно отражающих его смысл.
Практика показывает, что наиболее значимые слова лежат в средней части графика зависимости (рис. 7). Иными словами, самыми ценными для представления содержания документов являются термины не слишком редкие и не слишком частые. Слова, которые попадаются слишком часто, в основном оказываются предлогами, союзами и т. д. Редко встречающиеся слова также не имеют решающего смыслового значения в большинстве случаев.

Рис. 7. Выделение ключевых слов по закону Ципфа
Границы выделения ключевых слов определяют качество поиска в ИПС. Высокочастотные термины хоть и не являются специфическими, но все же дают большое число совпадений при сравнении терминов запроса и документа. Тем самым обеспечивается выдача многих релевантных документов, то есть увеличивается полнота поиска. С другой стороны, низкочастотные термины вносят относительно небольшой вклад в поиск нужных документов, так как редкие термины дают малое число совпадений образов запроса и документа. Но если они все же совпадают, то соответствующий найденный документ почти наверняка является релевантным [10, 14].
Ширина и границы диапазона частот зависят от используемых механизмов поиска, а также от анализируемых документов, и отличаются друг от друга в разных ИПС.
Во всех существующих методах индексирования применяется процедура исключения некоторых высокочастотных терминов, которые заведомо не являются ценными для отражения содержания документа [16]. Для исключения общеупотребительных слов, к которым относятся предлоги, союзы, артикли, вспомогательные глаголы, частицы, местоимения и т. п., используются стоп-словари. Стоп-словарь (стоп-лист, стоп-список, отрицательный словарь) – это словарь служебных и неинформативных терминов, которые не должны входить в число терминов индексации. Число служебных слов в отрицательном словаре составляет обычно несколько сотен, в зависимости от системы.
Дата добавления: 2015-07-10; просмотров: 591 | Нарушение авторских прав