Читайте также:
|
1. 1. Совместное использование всей базы данных.
2. 2. Совместное использование таблиц базы данных.
3. 3. Совместное использование объектов базы данных или страниц доступа к данным в Интернете.
4. 4. Репликация базы данных.
5. 5. Создание приложения в архитектуре «клиент-сервер».
Различие в первых двух возможностях обусловлено особенностями архитектуры Access и является специфичным именно для этой СУБД.
Можно поместить всю базу данных Access на сетевой сервер или в общую папку. Далее следует убедиться, что для базы данных задано открытие в режиме совместного доступа. Этот режим используется по умолчанию. Чтобы установить этот режим, необходимо в меню Сервис выбрать команду Параметры, затем на вкладке Другие в группе параметров Режим открытия по умолчанию выбрать параметр общий доступ (рис. 10.8).
Путем соответствующей настройки можно также определить параметры, управляющие блокировкой данных и обновлением данных в общей базе данных, такие, как «блокировка по умолчанию» (определяет блокируемую информационную единицу).
Совместное использование всей базы данных является наиболее простым способом организации совместного доступа. Все работают с одними и теми же данными, формами, отчетами, запросами, макросами и модулями. Это приемлемо, когда информационные потребности всех пользователей совпадают.
Существует и другой путь — разделение базы данных на две части: собственно данные и остальные объекты базы данных. В этом случае можно поместить на сетевой сервер только таблицы базы данных, а остальные объекты хранить на компьютерах пользователей. При этом работа с базой данных происходит быстрее, так как по сети передаются только данные. Если разделить базу данных на серверную часть (таблицы) и клиентскую часть, пользователь получит возможность изменять формы, отчеты и другие объекты в собственной клиентской базе данных, не влияя при этом на других пользователей.
При формировании запросов таблицы, к которым они относятся, могут находиться в другой БД. При этом используется так называемое присоединение таблиц. Пользователи могут корректировать данные в присоединенной таблице, но не могут менять ее структуру.
Преимущества использования присоединения:
· доступ к БД осуществляется быстрее, поскольку отсутствуют траты времени на передачу объектов по сети;
· резервирование данных и обновление других объектов упрощается, если таблицы хранятся отдельно от остальных объектов БД;
· пользователь может менять свои формы и отчеты, не оказывая влияние на компоненты, разработанные другими пользователями.
Присоединенные таблицы могут находиться не только в другой БД Access, но даже в БД других СУБД.
Распределенные базы данных могут быть расположены как в локальной, так и в глобальной сети. Обеспечить совместное использование данных из БД при работе в Интернете можно несколькими способами. Имеется возможность вывести один (или несколько) объект базы данных в формате статического HTML или генерируемого сервером HTML, а также создать страницы доступа к данным, а затем отображать их в обозревателе в Интернете.
Существуют различные способы выполнения репликации и синхронизации баз данных в Access:
· портфельная репликация;
· команды репликации в меню Сервис Microsoft Access;
· репликация в проекте Microsoft Access;
· программная репликация;
· диспетчер репликации Microsoft.
При использовании нескольких компьютеров имеется возможность создавать с помощью портфеля Microsoft Windows реплики базы данных Microsoft Access и поддерживать синхронизацию этих реплик. При этом находящиеся в разных местах пользователи могут одновременно работать каждый со своей копией, а затем синхронизировать их через подключение удаленного доступа или через Интернет.
При работе в среде «клиент-сервер» можно использовать имеющиеся дополнительные возможности и способы защиты, обеспечиваемые сервером. Данные сохраняются в таблицах на сервере базы данных, например на Microsoft SQL Server, а не в локальных таблицах в Microsoft Access. При открытии файла базы данных Access (.mdb) в режиме общего доступа Microsoft Access создает файл сведений о блокировке (.ldb) с тем же именем и в той же папке, что и файл базы данных. В файле сведений о блокировке сохраняются имя компьютера и имена всех совместно работающих пользователей базы данных в системе защиты. Microsoft Access использует эти сведения для управления совместной работой.
В многопользовательской среде с одними и теми же записями могут одновременно работать несколько человек. Поскольку в то время, когда один пользователь пытается редактировать записи, другие пользователи также могут вносить в них изменения или даже удалять данные, при работе иногда возникают противоречия.
Microsoft Access позволяет отслеживать состояние записей во время внесения в них изменений и обеспечить использование самых свежих данных. Если два (или более) пользователя пытаются внести изменения в одну и ту же запись, на экране появляется сообщение, помогающее разрешить конфликт. Чтобы облегчить отслеживание состояния записей, Microsoft Access отображает специальные маркеры в области выделения текущей записи, которые позволяют понять, в каком состоянии находится запись.
Реплицирование может применяться не только при работе нескольких пользователей в сети, но и, например, при использовании как настольного, так и переносного компьютера. При этом на переносном компьютере создается «оторванная» реплика, с которой можно работать автономно. Впоследствии, в случае необходимости (если в реплику вносились изменения, которые должны быть учтены в основной базе данных) можно произвести синхронизацию.
Поскольку исходная БД при репликации изменяется, то Перед созданием реплики следует создать резервную копию исходной базы данных.
2. SQL. Возможности задания состава колонок, выводимых в ответ.
Запрос SELECT способен извлечь информацию из строго определенных столбцов таблицы. Для этого искомые столбцы перечисляются в запросе.
Столбцы таблицы можно отобразить в любом порядке, соответствующем порядку, в котором они перечислены в запросе. Исходный порядок столбцов в таблице может не соблюдаться.
DISTINCT — аргумент, устраняющий повторные значения из выборки запроса SELECT
Задание состава колонок при объединении таблиц:
· JOIN <…> USING (column_list) служит для указания списка столбцов, которые должны существовать в обеих таблицах. Такое выражение USING, как:
· семантически идентично выражению ON, например:
A LEFT JOIN B USING (C1,C2,C3,...)
C1=B.C1 AND A.C2=B.C2 AND A.C3=B.C3,…
· Выражение NATURAL [LEFT] JOIN для двух таблиц определяется так, чтобы оно являлось семантическим эквивалентом INNER JOIN или LEFT JOIN с выражением USING, в котором указаны все столбцы, имеющиеся в обеих таблицах.
При использовании представления (view), набор колонок определяется запросом, создающим представление. Пример синтаксиса:
CREATE VIEW view1
AS SELECT column1, column2, column(n)
FROM table1, table2, table(n)
WHERE [condition];
По умолчанию, имена столбцов представления получаются автоматически из запрашиваемых таблиц. Произвольные имена, которые могут стать именами полей, даются в круглых скобках (), после имени таблиц. Они не будут запрошены, если совпадают с именами полей запрашиваемой таблицы. Тип данных и размер этих полей могут отличаться от запрашиваемых полей, которые передаются в представление. Обычно вы не указываете новых имен полей, но если вы все таки сделали это, вы должны делать это для каждого поля в представлении.
3. Задача.
Построить ER-модель для следующей предметной области.
На предприятии работает N сотрудников. Для каждого из них фиксируется: Фамилия, имя, отчество, дата рождения, пол, адрес, телефон; образование, специальность, должность, разряд. Один работник может владеть несколькими специальностями.
Сотрудник работает в каком-то одном подразделении.
Сотрудники работают на условиях сдельной оплаты труда. Для них оплата труда зависит от количества и сложности выполненной работы.
По каждому виду работ хранится: его полное название, код, разряд работы, расценка за единицу работы.
Ведется ежедневный учет, какие работы и в каком количестве и каком количестве выполнены каждым из сотрудников.
Заведующий кафедрой
бизнес-аналитики
Т.К.Кравченко ______________
БАЗЫ ДАННЫХ
-----------------------------------------------------------------------------------------------------------------------------
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ N 20.
Вопросы:
1. SQL. Возможности задания условий отбора.
SELECT — оператор DML языка SQL, возвращающий набор данных (выборку) из базы данных, удовлетворяющих заданному условию. В большинстве случаев, выборка осуществляется из одной или нескольких таблиц. В последнем случае говорят об операции слияния (англ. join). В тех СУБД, где реализованы представления и хранимые процедуры, также возможно получение соответствующих наборов данных. SELECT [DISTINCT | DISTINCTROW | ALL] select_expression,… [FROM table_references [WHERE where_definition] [GROUP BY {unsigned_integer | col_name | formula} [ASC | DESC], …] [HAVING where_definition] [ORDER BY {unsigned_integer | col_name | formula} [ASC | DESC], …]
· WHERE — используется для определения, какие строки должны быть выбраны или включены в GROUP BY.
· GROUP BY — используется для объединения строк с общими значениями в элементы меньшего набора строк.
· HAVING — используется для определения, какие строки после GROUP BY должны быть выбраны.
· ORDER BY — используется для определения, какие столбцы используются для сортировки результирующего набора данных.
Пример: SELECT f_name, l_name from employee_data where f_name = ‘Иван’; Этот оператор выводит имена и фамилии всех сотрудников, которые имеют имя Иван. Отметим, что слово Иван в условии заключено в одиночные кавычки. Можно использовать также двойные кавычки. Кавычки являются обязательными, так как MySQL будет порождать ошибку при их отсутствии. Кроме того сравнения MySQL не различают регистр символов, что означает, что с равным успехом можно использовать «Иван», «иван» и даже «ИвАн». Существуют различные оконные функции. ROW_NUMBER() OVER может быть использована для простого ограничения числа возвращаемых строк. Например, для возврата не более десяти строк: SELECT * FROM (SELECT ROW_NUMBER() OVER (ORDER BY KEY ASC) AS rownumber, COLUMNS FROM tablename) AS foo WHERE rownumber <= 10 оконная функция RANK() Функция RANK() OVER работает почти так же, как ROW_NUMBER, но может вернуть более чем n строк при определённых условиях. Например, для получения top-10 самых молодых людей: SELECT * FROM (SELECT RANK() OVER (ORDER BY age ASC) AS ranking, person_id, person_name, age FROM person) AS foo WHERE ranking <= 10
В MySQL можно к запросу дописать LIMIT (0,30) – Это выведет первые 30 записей (или меньше, если в таблице меньше 30). Так делает phpMyAdmin – прим.ред.
2. Базовая ER-модель. Виды объектов
ER-модели широко используются в практике создания баз данных, но при этом методики ER-моделирования различных CASE-систем отличаются от «классической» методики моделирования инфологической модели и различаются между собой.
Прежде всего, рассмотрим отличия «базовой» методики моделирования предметной области от используемых в CASE-системах. Принципиально важным является решение вопроса о том, что же отражает ER-модель. Во методологиях многих CASE-средств хотя считается, что ER-модель является концептуальной моделью БД, на самом деле она является не описанием предметной области, а реляционной БД. Поэтому рекомендуется строить две ER-модели: первая будет отображать предметную область, безотносительно к тому, что будет храниться в базе данных, а вторая — содержать только те элементы, которые будут храниться в БД.
В данном случае важна специфика языка построения ER-модели в конкретной CASE-системе. Так, например, во многих системах нет понятия «условного свойства», т.е. свойства, которое может присутствовать не у всех объектов класса. В данном случае, например, в методологиях типа IDEF1X возможно несколько вариантов: условное свойство изображать как обычный атрибут; объект, обладающий условным свойством, изобразить как обобщенный объект; или выделить «обладание свойством» в отдельный объект.
Большинство CASE-систем содержат изобразительные средства для отображения обобщенных объектов, но алгоритм преобразования к СУБД отличается в разных системах. Это, безусловно, скажется на подходе к моделированию предметной области: при невозможности отобразить многоаспектную классификацию придется изображать подклассы как самостоятельные объекты.
Понятие множественного свойства также отсутствует в большинстве CASE-систем. Для изображения каждого множественного свойства приходится использовать отдельный объект, зависящий по идентификации от основного объекта, обладающего этим свойством.
Важное различие в подходах также связано с именами объектов. При описании предметной области, имя объекта может быть как уникальным, так и неуникальным. Но в методологиях большинства CASE-систем уникальное наименование объекта должно быть выбрано в качестве идентификатора уже на стадии концептуального моделирования. Другими словами, проблема выбора ключа реляционной таблицы переносится на стадию инфологического проектирования.
Изобразительные средства и методики графического представления ER-моделей, используемые в разных системах автоматизации проектирования несколько отличаются друг от друга.
К несущественным различиям можно отнести терминологические расхождения и различия в условных обозначениях различных СASE-средств, т.е. различных обозначениях сущностей (прямоугольники, блоки с закругленными углами, овалы и т.п.) и связей (стрелки, лапки, точки и т.п.). Поскольку рассматриваемые различия не являются существенными, то легко выполнить преобразование из одной формы представления в другую, что и позволяют автоматически делать многие CASE-средства.
Встречаются такие существенные различия между CASE-системами как некоторые возможности, имеющиеся в одних системах и отсутствующие в других. В этих случаях нужно либо использовать определенные искусственные приемы, либо просто не отображать ситуацию в модели. Например, во многих системах инфологического моделирования свойства объекта могут быть только единичные и определенные (не условные), поэтому если свойство отсутствует у каких-либо объектов, то надо выделять отдельные сущности.
3. Задача.

Построить модель в ERWin
Заведующий кафедрой
бизнес-аналитики
Т.К.Кравченко ______________
БАЗЫ ДАННЫХ
-----------------------------------------------------------------------------------------------------------------------------
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ N 21
Вопросы:
1. Простые объекты и их свойства. Отображение в реляционной модели. ДИГО!
Отображение простых объектов
Определение состава полей основной таблицы. Для каждого простого объекта и его единичных свойств строится отношение, атрибутами которого являются идентификаторы объекта и реквизиты, соответствующие каждому из единичных свойств.
Определение ключа таблицы. Ключом является любой из уникальных идентификаторов объекта, отвечающий требованиям стабильности (неизменяемость значения) и мнемоничности (легкость запоминания). Ключ также может быть составным, например идентификатор объекта, от которого зависит определяемый. Для простых объектов может быть полезно генерировать искусственный ключ типа «счетчик».
Отображение множественных свойств объекта. Если у объекта имеются множественные свойства, то каждому из них ставится в соответствие отдельное отношение. Его полями будут идентификатор объекта и поле, отображающее множественное свойство, а ключ этого отношения будет включать оба эти атрибута.
Отображение условных свойств объекта. Если многие объекты обладают рассматриваемым условным свойством, то его можно хранить в базе данных так же, как и обычное свойство. Если только незначительное число объектов обладает указанным свойством, то можно выделить отдельное отношение, которое будет включать идентификатор объекта и атрибут, соответствующий рассматриваемому свойству.
Отображение составных свойств объекта. Если объект имеет составное свойство, то возможно либо всему составному свойству поставить в соответствие одно поле, либо каждому из составляющих элементов составного свойства – отдельное поле.
Отображение связи между объектами
Универсальный способ отображения связи между объектами — введение вспомогательного связующего файла, содержащего идентификаторы связанных объектов. Ключ этого отношения будет составным.
Отображение связи типа М:М. Если между объектами предметной области имеется связь М:М, то для хранения такой информации потребуются три отношения: по одному для каждой сущности и одно дополнительное — для отображения связи между ними. Последнее отношение будет содержать идентификаторы связанных объектов. Ключ этого отношения будет составным.
Отображение связи типа 1:М. Если между объектами предметной области имеется связь 1:М, то можно, как в случае связи М:М, использовать отдельную связующую таблицу, но ключом связующей таблицы будет уже только идентификатор объекта.
Однако если между объектами предметной области имеется связь 1:М и класс принадлежности n-связной сущности является обязательным, то можно использовать только два отношения (по одному для каждой сущности). В отношение, соответствующее сущности, к которой идет единичная связь, нужно дополнительно добавить идентификатор связанного с ней объекта.
Отображение связи типа 1:1. Если связь между объектами 1:1 и класс принадлежности обеих сущностей является обязательным, для отображения обоих объектов и связи между ними можно использовать одну таблицу. Но если класс принадлежности каждого из них является необязательным, то следует использовать три отношения: по одному для каждой сущности и одно — для отображения связи между ними.
Отображение альтернативной связи. Альтернативная связь обычно используется при изображении агрегированного объекта и означает, что в действии участвует либо один объект, либо другой, но не оба вместе. Для отражения связи с каждым из альтернативных классов объектов рекомендуется использовать отдельную таблицу.
2. Языки запросов. Общая характеристика.
Язык запросов — это искусственный язык, на котором делаются запросы к базам данных и другим информационным системам, особенно к информационно-поисковым системам. важным свойством реляционной модели является существование некоторого набора операций и формальных языков, с помощью которых можно построить запрос (последовательность запросов) к набору связанных отношений, в результате выполнения которого будет получено одно или несколько других отношений с искомыми данными в нужном сочетании.
Выделяют следующие разновидности языков реляционной алгебры:
· dBASe-подобные языки приближены к языкам структурного программирования, обеспечивают создание интерфейса пользователя и типовые операции обработки; — СУБД реляционного типа, такие, как dBASe, Paradox, FoxPro, Clipper, Rbase и др., используют языки манипулирования данными, обеспечивающие основные операции обработки реляционных баз данных, образующих класс dBASE-подобных (X-Base).
· графические реляционные языки, которые ориентированы на конечных пользователей; — Типичным представителем является язык QBE(Query By Example), реализованный в среде электронных таблиц, в ряде СУБД, в пакете Microsoft Query.
Данный язык относится к языкам манипулирования данными. Работа выполняется со схемой реляционной таблицы с использованием простейших синтаксических конструкций.
· SQL-подобные языки запросов, реализованные а большинстве многопользовательских и распределенных систем управления базами данных.
Все языки запросов имеют много общего. Но, с другой стороны, даже языки, относящиеся к одному классу, отличаются в деталях своей реализации.
В реляционных СУБД для выполнения операций над отношениями используются две группы языков, имеющие в качестве своей математической основы теоретические языки запросов, предложенные Э.Коддом:
- реляционная алгебра;
- реляционное исчисление.
Эти языки представляют минимальные возможности реальных языков манипулирования данными в соответствии с реляционной моделью и эквивалентны друг другу по своим выразительным возможностям. Существуют не очень сложные правила преобразования запросов между ними.
В реляционной алгебре операнды и результаты всех действий являются отношениями. Языки реляционной алгебры являются процедурными, так как отношение, являющееся результатом запроса к реляционной БД, вычисляется при выполнении последовательности реляционных операторов, применяемым к отношениям. Операторы состоят из операндов, в роли которых выступают отношения, и реляционных операций. Результатом реляционной операции является отношение.
Языки исчислений, в отличие от реляционной алгебры, являются непроцедурными (описательными, или декларативными) и позволяют выражать запросы с помощью предиката первого порядка (высказывания в виде функции), которому должны удовлетворять кортежи или домены отношений. Запрос к БД, выполненный с использованием подобного языка, содержит лишь информацию о желаемом результате. Для этих языков характерно наличие наборов правил для записи запросов. В частности, к языкам этой группы относится SQL.
3. Задача.
База данных содержит таблицы:
CENNIK (KODMAT, NAIMMAT, CENA)
POSTAVKA (KODMAT, KODPOST, DATAP, KOLV)
SPPOSTAV (KODPOST, NAIMPOST)
где:
KODMAT – код материала, NAIMMAT – наименование материала, CENA – цена, KODPOST – код поставщика,NAIMPOST – наименование поставщика, DATAP – дата поставки, KOLV – количество.
Сколько поставок чугуна было в 2003 г. произведено заводом «Серп и молот» (SQL).
Заведующий кафедрой
бизнес-аналитики
Т.К.Кравченко ______________
-----------------------------------------------------------------------------------------------------------------------------
БАЗЫ ДАННЫХ
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ N 22.
Вопросы:
1. SQL. Создание и использование представлений.
Представление – это виртуальная таблица, определяемая запросом, содержащим оператор SELECT. Эта виртуальная таблица состоит из данных одной или нескольких реальных таблиц, а для пользователей представление выглядит, как реальная таблица. И действительно, с представлением можно работать, как с обычной таблицей. Пользователи могут обращаться к этим виртуальным таблицам в операторах TrАnsАсt-SQL (T-SQL) таким же образом, как и к таблицам. К представлению можно применять операции SELECT, INSERT, UPDATE и DELETE. Синтаксис SQL CREATE VIEW: CREATE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition На самом деле представление хранится просто как заранее определенный оператор SQL. При доступе к представлению оптимизатор запросов SQL Server объединяет текущий выполняемый оператор SQL с запросом, который был использован для определения данного представления. Представление удаляется с помощью запроса: DROP VIEW view_name Представление обновляется при помощи: CREATE OR REPLACE VIEW view_name AS SELECT column_name(s) FROM table_name WHERE condition Преимущество использования представлений заключается в том, что можно создавать представления с различными атрибутами без необходимости дублирования данных. Представления полезны в целом ряде ситуаций: - С помощью представлений обеспечивается ещё один уровень защиты данных - Использование представлений позволяет отделить прикладную схему представления данных от схемы хранения - Для слияния секционированных данных.
В Аксессе представления создаются с помощью мастеров, конструкторов, etc – прим. ред.
49) Возможности организации ввода информации в реляционных СУБД. Оператор INSERT заполняет таблицу данными. Вот общая форма INSERT. INSERT into table_name (column1, column2, …) values (value1, value2…);
· Значениями для одних столбцов являются текстовые строки, и они записываются в кавычках.
· Значениями для других являются числа (целые), и они не имеют кавычек.
Значение для ключевого столбца задает система MySQL, которая находит в столбце наибольшее значение, увеличивает его на единицу, и вставляет новое значение.
inc -это ключевое поле naim — в этом столбце мы указываем название товара. cena -в этом столбце мы указываем цену товара. kol -это количество товара. srok — это срок годности продукта. Также в Access можно войти в режим Таблица и непосредственно забить данные с клавиатуры(Новая запись, Вставкаà новая запись, щёлкнуть мышью). Могут использоваться значения по умолчанию, формат поля и маска ввода. 1) По умолчанию – постоянное значение, которое затем может быть изменено. 2) Маска ввода – позволяет определить значения, которые можно ввести. Облегчает ввод и отслеживает правильность. 3) Формат поля – влияет на отображение, но не на значение поля. Здесь полезно сказать о всех видах интерфейсов, которые можно разработать и которые можно поиметь готовыми. Это и оболочки типа MyManager, и скрипты в экселе на бейсике, и подключение к студии через ADO.NET, и PHP – прим.ред.
2. Стандарты SQL.
В силу широкого использования язык SQL сначала стал де-факто стандартом языка запросов, а затем было официально разработано несколько международных стандартов SQL. Кроме того, некоторые страны имеют национальные стандарты SQL.
Язык SQL имеет официальный стандарт — ANSI/ISO. Большинство разработчиков придерживаются этого стандарта, однако часто расширяют его для реализации новых возможностей обработки данных.
Первый стандарт языка появился в 1989 г. — SQL-89 — и поддерживался практически всеми коммерческими реляционными СУБД. Он имел весьма общий характер и допускал широкое толкование. Достоинствами SQL-89 можно считать стандартизацию синтаксиса и семантики операторов выборки и манипулирования данными, а также фиксацию средств ограничения целостности базы данных. Однако в нем отсутствовали такие важные разделы как манипулирование схемой базы данных и динамический SQL.
Неполнота стандарта SQL-89 привела к появлению в 1992г. следующей версии языка SQL. SQL-92 охватывает практически все необходимые проблемы: манипулирование схемой базы данных, управление транзакциями и сессиями, динамический SQL. В стандарте существуют три уровня: базовый, промежуточный и полный. Только в последнее время СУБД ведущих производителей обеспечивается совместимость с полным вариантом языка.
Появление новых требований пользователей к СУБД и обрабатываемым данным привели к тому, что в настоящее время ведется работа по разработке SQL 3. Эта версия языка, видимо, будет иметь в своем составе механизм триггеров, определение произвольного типа данных, серьезные объектные расширения. Пока же крупнейшие производители СУБД затягивают разработку этого стандарта, совершенствуя и расширяя собственные версии языка SQL.
3. Задача.
 Построить структуру реляционной базы данных
Построить структуру реляционной базы данных
Заведующий кафедрой
бизнес-аналитики
Т.К.Кравченко ______________
БАЗЫ ДАННЫХ
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ N 23.
Вопросы:
1. Базовая ER-модель. Виды свойств.
Базовая ER-модель является объектной по своей сути, она может быть
использована и при создании объектных баз данных
2. ERWin. Виды сущностей и их создание.
AllFusion ERwin Data Modeler (ранее: ERwin) - CASE-средство для проектирования и документирования баз данных, которое позволяет создавать, документировать и сопровождать базы данных, хранилища и витрины данных. Модели данных помогают визуализировать структуру данных, обеспечивая эффективный процесс организации, управления и администрирования таких аспектов деятельности предприятия, как уровень сложности данных, технологий баз данных и среды развертывания.
AllFusion ERwin Data Modeler (ERwin) предназначен для всех компаний, разрабатывающих и использующих базы данных, для администраторов баз данных, системных аналитиков, проектировщиков баз данных, разработчиков, руководителей проектов. AllFusion ERwin Data Modeler позволяет управлять данными в процессе корпоративных изменений, а также в условиях стремительно изменяющихся технологий.
AllFusion ERwin Data Modeler (ERwin) позволяет наглядно отображать сложные структуры данных. Удобная в использовании графическая среда AllFusion ERwin Data Modeler упрощает разработку базы данных и автоматизирует множество трудоемких задач, уменьшая сроки создания высококачественных и высокопроизводительных транзакционных баз данных и хранилищ данных. Данное решение улучшает коммуникацию в вашей организации, обеспечивая совместную работу администраторов и разработчиков баз данных, многократное использование модели, а также наглядное представление комплексных активов данных в удобном для понимания и обслуживания формате.
В работе «Базы данных: проектирование и использование» были выделены несколько разновидностей объектов (сущностей). Прежде всего, это простые и сложные объекты. Объект называется простым, если он рассматривается в данном исследовании как неделимый. Сложный объект представляет собой объединение других объектов, простых или сложных, также отображаемых в информационной системе. Выделяют несколько разновидностей сложных объектов: составные, обобщенные и агрегированные объекты. Составной объект соответствует отображению отношения «целое – часть». Обобщенный объект отражает наличие связи «род – вид» между объектами предметной области. Агрегированные объекты соответствуют обычно какому-либо процессу, в который оказываются «вовлеченными» другие объекты. В ERWin имеются специальные условные обозначения для изображения простых сущностей и специальный символ, используемый при изображении обобщенных объектов (хотя само понятие «обобщенный объект» в ERWin отсутствует). Остальные разновидности сущностей можно отобразить, используя соответствующие сочетания обозначений простых сущностей и связей между ними.
Для создания новой сущности следует воспользоваться кнопкой. После позиционирования на экране и нажатия на правую кнопку мыши появится
значок, отображающий сущность (рис. 4.12). В выделенную вверху область следует ввести имя сущности.
После этого на экране появится область для ввода имени атрибута этой сущности. Можно последовательно ввести таким образом имена нескольких атрибутов описываемой сущности. Эти атрибуты будут помечены как входящие в первичный ключ. Исходя из этого можно порекомендовать: прежде чем описывать сущность, продумать, какой (какие) атрибут(ы) следует выбрать в качестве первичного ключа, и начать создание сущности с описания именно этих атрибутов. После ввода атрибутов, входящих в состав первичного ключа, ввод атрибутов следует временно прекратить. На экране появит-
ся изображение создаваемого объекта. Его следует открыть двойным щелчком левой клавиши мыши. После чего на экране появится окно Attributes в котором и надо продолжить описание остальных атрибутов.
3. Задача.
База данных содержит таблицы:
Сотрудник (код_сотрудника, фио,....)
Дети (код_сотрудника, фио_ребенка).
Выдать список сотрудников, имеющих менее 2 детей. (SQL)
Заведующий кафедрой
бизнес-аналитики
Т.К.Кравченко ______________
БАЗЫ ДАННЫХ
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ N 24.
Вопросы:
1. Базовая ER-модель. Виды свойств.
2.. ERWin. Виды связей.
3. Задача.
 Корректирующий запрос. SQL. Установить оклад сотруднику Иванову Ивану Ивановичу оклад в размере 30000 руб.
Корректирующий запрос. SQL. Установить оклад сотруднику Иванову Ивану Ивановичу оклад в размере 30000 руб.
Заведующий кафедрой
бизнес-аналитики
Т.К.Кравченко ______________
БАЗЫ ДАННЫХ
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ N 25.
Вопросы:
1. Табличные языки запросов. Корректировка данных.
Ввод и корректировка данных в режиме «Таблица»
Как отмечалось выше, чтобы сразу после описания структуры таблицы в режиме
Конструктора вводить данные в эту таблицу, надо перейти в режим таблицы. После со-
хранения описания таблицы, она высвечивается на экране в табличном виде (первая
строка этой таблицы содержит имена полей таблицы, вторая – пустая, в которую и вво-
дятся данные).
Для того чтобы попасть в режим «Таблица» для ввода данных в уже существую-
щую таблицу, надо в области переходов позиционироваться на нужной таблице и от-
крыть ее. Каждая таблица содержит пустую запись, которая следует за последней суще-
ствующей записью и предназначена для ввода новых данных (эта запись отмечена слева
символом «звездочка»(*)).
В Access для рационализации процесса ввода данных в БД можно использовать
свойство поля «Значение по умолчанию». Свойство «Значение по умолчанию» позволя-
ет указать значение, которое будет автоматически вводиться в поле при создании новой
записи. В качестве значения по умолчанию чаще всего выбирается то значение, которое
чаще всего встречается в записях БД. Например, для значения поля «Должность» в таб-
лице, содержащей сведения о сотрудниках вуза, это будет «доцент».
Обычно в качестве значения по умолчанию указывается постоянное значение, од-
нако можно использовать и выражение. Например: для ввода текущей даты можно ввести
выражение
=Date(),
использующее функцию «Date()», выводящую текущую дату.
Если функция используется в выражении по умолчанию, то значение соответст-
вующего поля может быть впоследствии изменено вручную.
Выражения, которые используются в качестве значений по умолчанию, не должны
содержать ссылки на элементы управления и другие поля, а также функции, определен-
ные пользователем.
Выражения могут записываться непосредственно или строиться с помощью «По-
строителя выражений».
Надо с осторожностью относиться к использованию значений по умолчанию.
2..Задание ограничений целостности в ERWin..
4.9. Ограничения целостности
При построении ER-модели в ERWin можно задавать ограничения целостности.
Способ задания ограничения целостности зависит от вида ограничения.
Ограничения на значения атрибутов Некоторые из ограничений целостности можно задать при определении атрибутов. На вкладке Datatype окна Attributes (рис. 4.61) можно отметить свойство Required, что будет означать, что при вводе информации в базу данных для соответствующего поля должно быть обязательно введено значение. Для тех атрибутов, которые выбраны в качестве первичного ключа, это свойство является неактивным, так как свойство обязательности и так (по определению ключа) присуще элементам ключа
Для того чтобы задать ограничение на значение атрибута, надо нажать на кнопку рядом с окошком для задания значения параметра Valid. В появившемся далее окне Validation Rules (рис. 4.62) можно задать новые ограничения целостности Для задания нового ограничения целостности надо нажать на кнопку New и в появившемся окне New Validation Rule (рис. 4.63) задать имя ограничения. В окне Validation Rules (рис. 4.64) можно задать список допустимых значений для выбранного атрибута (Valid Values List). В рассматриваемом примере был задан допустимый список значений для атрибута
«пол».
Кроме задания списка значений для атрибута можно определить максимальное и минимальное значение. Для этого в окне при описании ограничения целостности следу ет выбрать тип ограничения Min/Max ри задании ограничений целостности можно воспользоваться и возможностью задать любое допустимое выражение, выбрав тип ограничения User-Defined (рис. 4.68). В приведенном примере задано выражение, определяющее возраст сотрудника В окно задания ограничений целостности можно попасть и выбрав позиции меню Model/Validation Rules (рис. 4.69). Если ранее уже были заданы какие-то ограничения целостности, то в окне Validation Rules будет выводиться весь список этих ограничений.
При описании связи можно задать ограничения целостности связи. Для этого следует воспользоваться вкладкой RI Actions
Вид окна Relationships для этой вкладки показан на рис. 4.71. Для каждой связи можно задать действия, которые будут выполняться при удалении (Delete), вставке (Insert) и удалении (Update) как порожденной (Child), так и родительской (Parent) сущности. Для каждой из корректирующих операций можно выбрать следующее действие:
• NONE – действие не оказывает влияние на связанные записи;
• RESTRICT – действие запрещено (при определенных условиях);
• CASCADE – действие вызывает изменения в связанных записях;
• SET DEFAULT – устанавливается значение по умолчанию для поля связи;
• SET Null – устанавливается по умолчанию значение Null для поля связи.
Набор возможных значений и значения, выбранные системой по умолчанию, будут зависеть от характеристик связи, для которой задаются ограничения целостности.
3. Задача.
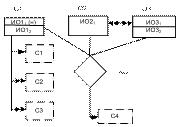 Построить структуру реляционной базы данных
Построить структуру реляционной базы данных
Заведующий кафедрой
бизнес-аналитики
Т.К.Кравченко ______________
БАЗЫ ДАННЫХ
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ N 26.
Вопросы:
1. Базовая ER-модель. Виды свойств.
2.. Особенности реляционных баз данных.
Основной информационной единицей в реляционных базах данных является плоская двумерная таблица. Отличительной чертой реляционных моделей является ограничение на внутризаписную структуру: записи имеют линейную структуру и могут содержать только простые поля
Другой особенностью реляционных моделей является то, что связи между записями соответствующих таблиц определяются динамически в момент выполнения запроса. Эти связи определяются по равенству значений соответствующих полей (полей связи), содержащихся в каждой из связанных таблиц.
Особенностью реляционных моделей является то, что в этих системах должны использоваться теоретико-множественные
Языки Манипулирования Данными. Восьмидесятые годы были временем интенсивного развития реляционных систем.
В 1992 году1 уровень продаж реляционных СУБД впервые превысил уровень продаж нереляционных СУБД. Но до 90% данных предприятий хранилось к этому моменту в нереляционных базах данных на мэйнфреймах. Преобладание популярности реляционных СУБД сохранилось до настоящего времени.
Для реляционной модели сложность будет характеризоваться числом таблиц и полей в БД, числом индексных файлов (индексов). В принципе, чем меньше сложность БД, тем лучше. Однако снижение сложности, наряду с положительными результатами, часто приводит ко многим отрицательным последствиям. Так, для реляционных систем самой «простой» БД будет одно универсальное отношение, но к каким последствиям приведет использование такого проектного решения, хорошо известно из теории нормализации
• обработка «неэлементарных» полей в реляционных системах всегда представляет сложность (это вызвано тем, что с точки зрения СУБД поле остается элементарной единицей). Например, если вы в БД «КАДРЫ» включили поле «ДЕТИ», в котором в записи о сотруднике фиксируете сведения обо всех его детях, то задать запросы типа «Выделить всех сотрудников, имеющих больше 3-х детей» или «Определить среднее число детей у
сотрудников» будет достаточно сложно. В то же время если сведения о детях выделить в отдельную таблицу, в которой каждому ребенку будет соответствовать отдельная запись, то реализация подобных запросов не составит особого труда;
• все «групповые» операции (суммирование, подсчет, определение среднего значения и т.п.) в реляционных СУБД обычно относятся к элементам одного столбца, а не строки; это следует учитывать при проектировании структуры БД;
• для полей типа Memo число допустимых операций по их обработке сильно ограничено по сравнению с полями других типов. Число подобных примеров можно продолжить. Таким образом, при проектировании БД необходимо знать:
а) особенности языков манипулирования данными в целевой СУБД;
б) особенности предполагаемой обработки данных
Связи между файлами в реляционной модели в явном виде могут не описываться. Они устанавливаются динамически в момент обработки данных по равенству значений соответствующих полей. В сетевых и иерархических моделях структура записи, в принципе, может быть любой. Хотя многие СУБД накладывают различные ограничения на структуру записи. В реляционных моделях структура записи должна быть линейной. Каждое отношение по определению имеет ключ, т.е. атрибут (простой ключ) или совокупность атрибутов (составной ключ), однозначно идентифицирующих кортеж. В некоторых случаях в отнош
3. Задача.

Для приведенной структуры таблицы реализуйте следующий запрос на SQL:
Выдать список сотрудников, работающих в данном учебном заведении более 10 лет. Список должен быть упорядочен по алфавиту.
Заведующий кафедрой
бизнес-аналитики
Т.К.Кравченко ______________
БАЗЫ ДАННЫХ
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ N 27.
Вопросы:
1. Базовая ER-модель. Виды свойств.
2. Объектная модель ADO. Как используются объект Recordset и коллекция Fields.
ADO (от англ. ActiveX Data Objects — «объекты данных ActiveX») — интерфейс программирования приложений для доступа к данным, разработанный компанией Microsoft и основанный на технологии компонентов ActiveX. ADO позволяет представлять данные из разнообразных источников (реляционных баз данных, текстовых файлов и т. д.) в объектно-ориентированном виде.
Объектная модель ADO состоит из следующих объектов высокого уровня и семейств объектов:
· Connection (представляет подключение к удалённому источнику данных)
· Recordset (представляет набор строк, полученный от источника данных)
· Command (используется для выполнения команд и SQL-запросов с параметрами)
· Record (может представлять одну запись объекта Recordset или же иерархическую структуру, состоящую из текстовых данных)
· Stream (используется для чтения и записи потоковых данных, например, документов XML или двоичных объектов)
· Errors (представляет ошибки)
· Fields (представляет столбцы таблицы базы данных)
· Parameters (представляет набор параметров SQL-инструкции)
· Properties (представляет набор свойств объекта)
In ADO, Recordset object is the most important and the one used most often to manipulate data from a database.
When you first open a Recordset, the current record pointer will point to the first record and the BOF and EOF properties are False. If there are no records, the BOF and EOF property are True.
Recordset objects can support two types of updating:
In ADO there are 4 different cursor types defined:
The cursor type can be set by the CursorType property or by the CursorType parameter in the Open method.
Note: Not all providers support all methods or properties of the Recordset object.
Главное содержание Recordset - это то, что лежит в ячейках на пересечении строк (в Recordset они называются записями - records и представлены соответствующими объектами Record) и столбцов в Recordset они представлены столбцами (полями - объектами Field), которые сведены в коллекцию Fields. Объекты Record используются нечасто - поскольку имен у них нет, а переходить между записями проще при помощи свойств и методов самого объекта Recordset - AbsolutePosition, Find, Move и т.п. Коллекция же Fields и объекты Field используются практически в каждой программе.
коллекции Fields все свойства стандартные, как у каждого объекта Collection:
· Count - сколько всего столбцов в Recordset
· Item - возможность вернуть нужный столбец (объект Field) по имени или номеру. Поскольку это свойство является свойством по умолчанию, то можно использовать код, как в нашем примере: rs.Fields("CompanyName"). Есть еще один вариант синтаксиса для обращения к этому свойству:
rs!CompanyName
Методы же имеются как стандартные, так и специфические:
· Append - возможность добавить новый столбец в Recordset. Delete - соответственно, удалить столбец. Обе команды разрешено выполнять только на закрытом Recordset (пока не был вызван метод Open или установлено свойство ActiveConnection).
· Update - сохранить изменения, внесенные в Recordset (будет произведена попытка создать новый столбец на источнике данных, если источник данных по каким-то причинам принимать эти изменения отказался, возникнет ошибка), CancelUpdate - отменить изменения, внесенные в Recordset.
· Refresh - загадочный метод, который ничего не делает (о чем честно написано в документации). Обновить структуру Recordset данными с источника можно только методами самого объекта Recordset.
· Resync - работает только для коллекции Fields объекта Record (не Recordset), обновляя значения в строке.
Намного больше интересных свойств у объекта Field:
· ActualSize - реальный размер данных для текущей записи, DefinedSize - номинальный размер данных для столбца (в байтах), в соответствии с полученной с источника информацией.
· Attributes - возможность определить битовую маску для атрибутов столбца (допускает ли пустые значения, можно ли использовать отрицательные значения, можно ли обновлять, используется ли тип данных фиксированной длины и т.п.)
· Name - просто строковое имя столбца. Для столбцов, полученных с источника, доступно только на чтение.
· NumericScale и Precision - значения, которые определяют соответственно допустимое количество знаков после запятой и общее максимальное количество цифр, которое можно использовать для представления значения.
· Value - самое важное свойство объекта Field. Определяет значение, которое есть в столбце (если мы пришли через коллекцию Fields объекта Record, то для этой записи, если через Fieldsобъекта Recordset - то для текущей записи). Пример применения - в нашей строке для поиска. Доступно и на чтение, и на запись (в зависимости от типа указателя). ADO позволяет работать с большими двоичными данными (изображения, документы, архивы), что очень удобно. OriginalValue - значение, которое было в этом столбце до начала изменений, UnderlyingValue - значение, которое находится на источнике данных (пока мы работали с Recordset, оно могло быть изменено другой транзакцией, и поэтому OriginalValue и UnderlyingValue могут не совпадать). Свойство Value - это свойство по умолчанию, поэтому эти две строки равноценны:
Wscript.Echo rs.Fields("CompanyName")
Wscript.Echo rs.Fields("CompanyName").Value
· Status - значение, отличное от adFieldOK (значение 0) означает, что поле было недавно программно добавлено в Recordset или при добавлении возникла ошибка на источнике данных.
· Type - тип данных в соответствии с приведенной в документации таблицей. Например, для типа данных nvarchar возвращается 202.
У объекта Field есть только два метода - AppendChunk и GetChunk. Оба этих метода используются только для работы с большими двоичными типами данных, когда работать обычными способами через свойство Value не получается.
3. Задача.
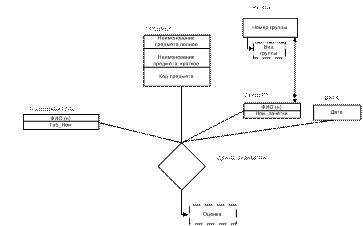 Изобразить данный фрагмент базовой ER-модели в ERWin
Изобразить данный фрагмент базовой ER-модели в ERWin
Заведующий кафедрой
бизнес-аналитики
Т.К.Кравченко ______________
БАЗЫ ДАННЫХ
-----------------------------------------------------------------------------------------------------------------------------
ЭКЗАМЕНАЦИОННЫЙ БИЛЕТ N 28.
Вопросы:
1.Реляционные модели. Первичный ключ: понятие, свойства, выбор первичного ключа при проектировании.
Перви́чный ключ (англ. primary key) — в реляционной модели данных один из потенциальных ключей отношения, выбранный в качестве основного ключа (или ключа по умолчанию).
Если в отношении имеется единственный потенциальный ключ, он является и первичным ключом. Если потенциальных ключей несколько, один из них выбирается в качестве первичного, а другие называют «альтернативными».
С точки зрения теории все потенциальные ключи отношения эквивалентны, то есть обладают одинаковыми свойствами уникальности и минимальности. Однако в качестве первичного обычно выбирается тот из потенциальных ключей, который наиболее удобен для тех или иных практических целей, например для создания внешних ключей в других отношениях либо для создания кластерного индекса. Поэтому в качестве первичного ключа, как правило, выбирают тот, который имеет наименьший размер (физического хранения) и/или включает наименьшее количество атрибутов.
Другой критерий выбора первичного ключа — сохранение уникальности со временем. Всегда существует вероятность того, что некоторый потенциальный ключ перестанет быть таковым в долговременной перспективе или при изменении требований к системе. Например, если номер студенческой группы включает последнюю цифру года поступления, то номера групп для идентификации групп уникальны только в течение 10 лет. Поэтому в качестве первичного ключа стараются выбирать такой потенциальный ключ, который с наибольшей вероятностью не утратит уникальность.
Исторически термин «первичный ключ» появился и стал использоваться существенно ранее термина «потенциальный ключ». Вследствие этого множество определений в реляционной теории были изначально сформулированы с упоминанием первичного (а не потенциального) ключа, например, определения нормальных форм. Также термин «первичный ключ» вошёл в формулировку 12 правил Кодда как основной способ адресации любого значения отношения (таблицы) наряду с именем отношения (таблицы) и именем атрибута (столбца).
Дата добавления: 2015-07-20; просмотров: 93 | Нарушение авторских прав
| <== предыдущая страница | | | следующая страница ==> |
| MS ACCESS | | | Простые и составные ключи |